智猩猩Agentic整理
编辑:六一
在复杂数学推理任务中,传统方法往往面临两难选择:当前长链式思维模型虽擅长数学推理,但依赖缓慢且易出错的自然语言过程。工具增强智能体可用代码解决算术问题,但在复杂逻辑任务上表现有限。
为此,卡内基梅隆大学团队提出双策略蒸馏框架DualDistill,将多个教师模型的互补推理策略蒸馏至统一的学生模型中。由此训练出的Agentic-R1模型可根据不同问题动态选择最优策略:用工具处理算术、算法问题,用文本推理解决理论性任务。在此基础上,通过自蒸馏技术,Agentic-R1-SD进一步提升了模型性能。
模型在多种任务中的准确性均有所提升,超越同规模的Qwen2.5和Deepseek-R1模型,展示了多策略蒸馏方法的有效性,向实现通用推理智能迈出了关键一步。

论文标题:
Agentic-R1: Distilled Dual-Strategy Reasoning
论文链接:
https://arxiv.org/pdf/2507.05707
项目地址:
https://github.com/StigLidu/DualDistill
1
方法
论文采用基于Claude-3.5-Sonnet构建的工具辅助智能体OpenHands作为智能体推理教师,可执行人工设计的问题解决流程。文本推理教师则采用Deepseek-R1。学生模型选用Deepseek R1-Distill-7B,该模型不仅经过纯文本推理轨迹的微调,还在预训练阶段接触过代码相关数据。
DualDistill框架通过轨迹组合将互补教师模型的知识蒸馏至学生模型,随后学生模型通过自蒸馏机制实现策略的深层理解。具体流程如下:

1、教师蒸馏
论文从DeepMath数据集中选取了两个对比鲜明的数学问题子集作为训练集:一个子集的问题更适合采用工具辅助推理策略,另一个子集则更适用于纯文本推理策略。
对于训练集中的每个训练实例,通过采样二元指示器随机选择初始教师,生成初始解y1,另一位教师随后在原始问题x和先前解y1的条件下生成第二个解y2。
使用基于规则的评分器分别为 y1 和 y2 分配二元正确性得分g1、g2 ∈ {0,1}。然后根据这些正确性得分构建蒸馏训练轨迹:
g1=0, g2=1:第一位教师解法错误,第二位纠正成功,轨迹为 y1⊕t−+⊕y2。
g1=1, g2=1:两位教师均正确,轨迹为y1⊕ t++⊕y2,体现互补策略。
g1=1, g2=0:仅第一位正确,轨迹仅包含 y1。
g1=0, g2=0:两位均错误,舍弃该问题,不生成轨迹。
这里⊕表示连接,过渡片段t−+和t++是预先定义的句子,表示策略转换(例如“等等,使用文本推理太繁琐了,让我们尝试代码推理。”)
经过组合后,进行额外的数据过滤以确保训练集平衡。使用合成的轨迹微调初始学生模型,得到中间学生模型。
2.自蒸馏
尽管学生模型从多位教师处学习了问题解决策略,但因自身规模等限制,表现仍不及教师模型。比如,面对本可简单推理解决的问题,模型仍倾向调用工具,却因工具使用能力不足,反而易产生错误。
为解决这一问题,论文引入自蒸馏机制,帮助学生模型根据自身能力和具体问题进一步优化策略选择。
具体而言,使用中间学生模型对训练集中的每个问题采样K条轨迹:采用二元评分器G来评估轨迹的准确性。定义g(i,j)为第j条轨迹的得分,
 为问题x(i)的平均得分。
为问题x(i)的平均得分。
当

时,表明模型无法完全解决问题x(i),按以下规则从其输出中筛选轨迹,用于自蒸馏训练:
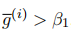
:保留一条中间模型输出的正确轨迹(经教师模型验证后)

:记录一条错误轨迹及教师修正方案
β1和β2是控制问题筛选的超参数,分别设置为0和0.9以保持样本多样性。鉴于学生模型的代码能力局限,当前仅使用文本推理方案作为教师反馈。
2
实验
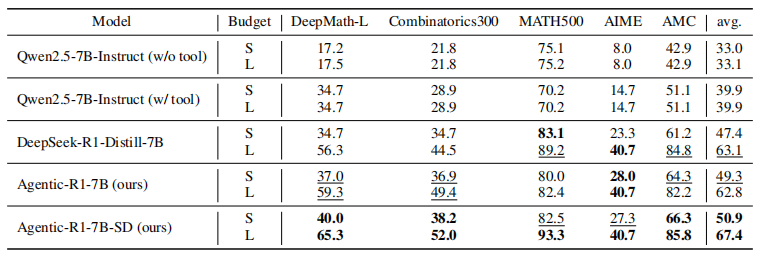
经过教师蒸馏的Agentic-R1在DeepMath-L和Combinatorics 300这两个需要复杂推理和工具使用的任务上表现突出:优于两个规模相似、但分别专注于工具辅助策略(Qwen2.5-7B-Instruct)或纯推理策略(Deepseek-R1-Distill-7B)的模型,同时在常规数学任务上保持了可比性能。通过自蒸馏技术,Agentic-R1-SD进一步提升了性能,在几乎所有任务上都超越了基线模型。
✦ END ✦
推荐阅读
ICML2025 Oral | NUS与上海AI Lab首提智能体超网概念并推出MaAS框架,可自动演化多智能体系统
精调手机GUI智能体击败GPT-4o!腾讯AI Lab俞栋团队提出在线强化学习框架MobileGUI-RL
从提示词到 Function Calling:MCP 的前世今生
别再迷信 Agent 框架了,Context Engineering 才是王道
点击下方名片 即刻关注我们