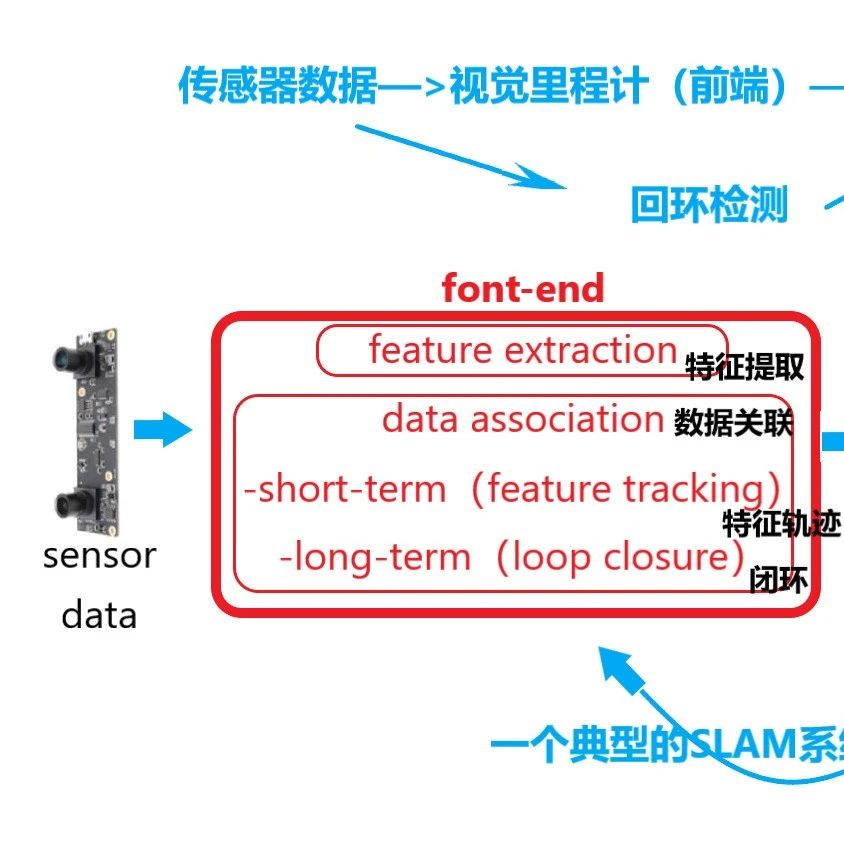
全文约 2400 字,预计阅读时间 6 分钟
一、研究背景与动机

惯性测量单元(IMU)作为机器人系统的核心组件,通过测量线性加速度和角速度实现运动跟踪,在自动驾驶车辆、无人机、腿式机器人等平台中不可或缺。与视觉或激光里程计相比,IMU在低光照、烟雾等极端环境中更鲁棒,但传统惯性里程计(IO)依赖二次积分计算位姿,易受传感器偏差、温度波动影响,误差会快速累积,几秒内即可产生显著漂移。
现有学习式IO方法虽有进展(如TLIO用于行人、IMO用于无人机),但存在两大瓶颈:
泛化性不足:模型多针对单一平台或运动模式训练,面对新设备或未知运动时性能骤降;
适应性匮乏:难以快速适配新平台,且大规模参数微调易导致“灾难性遗忘”(忘记已有知识)。
为此,来自卡耐基梅隆大学的研究团队提出Tartan IMU——首个面向惯性定位的轻量级基础模型,通过“预训练-微调-在线适应”三阶段框架,实现跨平台通用化定位。
项目地址:https://superodometry.com/tartanimu
论文链接:(见文末[1])
二、核心方法:三阶段框架设计
Tartan IMU的核心是通过三级递进式学习,从通用知识到场景适配,实现全流程鲁棒定位。

2.1 阶段一:预训练IMU基础模型——学习跨平台通用运动知识
预训练的目标是让模型从海量多源数据中提炼普适性运动规律,核心设计包括四部分:
数据对齐与增强 不同设备的IMU存在坐标系与采样率差异,论文通过统一坐标系(X前、Y左、Z上)和采样率(200Hz)消除硬件差异;同时引入“旋转等变性”增强——若IMU坐标轴旋转,预测轨迹需同步变换,提升模型对不同安装姿态的适应性。
异构共享Backbone 采用“ResNet+LSTM”架构:ResNet提取IMU数据的空间特征,LSTM捕捉运动的时间动态性,将不同平台(汽车、无人机、腿式机器人、人类)的IMU数据映射到统一高维空间。t-SNE可视化显示,该空间中不同平台的运动数据形成清晰聚类(如车辆为红色、无人机为绿色),证明模型既能统一表征又能区分差异。
多头输出设计 在共享Backbone后,针对不同平台设计专用回归头(如汽车头、无人机头),分别预测速度与协方差。这种“共享特征+专用输出”的模式,既能并行学习多样化运动模式,又避免了不同平台运动特性的冲突(如无人机悬停与汽车转弯的差异)。
损失函数优化 采用“相对运动损失”与“协方差损失”结合的方案:1. 相对运动损失在IMU体坐标系中计算速度误差(而非全局坐标系),避免模型记忆固定轨迹; 2. 协方差损失通过估计不确定性,提升预测的可靠性。
2.2 阶段二:LoRA微调——高效适配未见过的平台与场景
预训练模型虽具备通用性,但面对全新平台仍需适配。论文引入低秩适应(LoRA)技术,仅微调少量参数即可实现快速适配:
原理:将预训练权重矩阵 的更新量 分解为低秩矩阵 与 (其中 ),训练时仅更新A和B,冻结原始权重。
优势:仅需1.1M可训练参数(远少于全量微调),既能保留预训练知识,又能快速学习新平台特性,同时避免灾难性遗忘。
2.3 阶段三:在线适应——实时学习与动态优化
实际部署中,环境与运动模式可能持续变化(如车辆从平地到越野)。论文提出“在线适应”机制,打破训练与测试的边界,实现“边运行边学习”:
动态训练缓冲区:采用高斯混合模型(GMM)对IMU数据聚类(如静止、直行、左转、右转),动态筛选多样化样本存入缓冲区,确保数据均衡且不重复,减少计算负担。 SLAM协同学习:将SLAM系统作为“教师”,提供相对位姿作为监督信号,IMU模型作为“学生”持续优化,在200 FPS的实时速率下实现性能提升。

上图展示了由高斯混合模型(GMMs)分类的运动模式分布。带有叠加高斯拟合的直方图显示了基于线速度和角速度的聚类。GMM 识别出的运动类型包括:红线表示的右转(具有负的线速度)、蓝线表示的左转(具有正的线速度 )、Y 方向线速度、绿线表示的速度接近零的静止状态,以及紫线表示的具有正线速度的前进运动。
三、实验验证:核心能力的量化与定性分析
论文基于100小时多平台IMU数据(涵盖轮式机器人、无人机、腿式机器人等),通过四类实验验证模型性能。
3.1 跨平台泛化性:超越专用模型

上图为TartanIMU 与其他专用 IMU 模型的定性分析,轮式机器人(第一行)、人类手持设备(第二行)、四足机器人(第三行)和无人机(第四行)系统,TartanIMU 都优于不同的专用 IMU 模型。

在轮式机器人、人类手持设备、腿式机器人(狗)、无人机四类平台上,Tartan IMU的绝对轨迹误差(ATE)平均降低35.5%,时间相对轨迹误差(T-RTE)平均降低41.0%:
腿式机器人场景中,ATE从3.23m降至1.46m,提升54.8%; 人类手持设备场景中,T-RTE从4.82m降至1.95m,提升60.0%。

对比“单一平台训练”与“全平台训练”的结果,后者在所有场景中均表现更优,平均ATE提升42%,证明多样化数据对泛化性的关键作用。
3.2 微调适应性:快速迁移至新场景

在“从SubT数据集(源域)到TartanDrive数据集(目标域)”的迁移实验中,Tartan IMU仅需60个epoch即可实现高精度定位,较现有SOTA方法少33%迭代次数,且轨迹更接近真值。
3.3 在线适应:实时动态优化

针对“UGV(最高5m/s)到越野车辆(最高15m/s)”的跨速度域适应,模型通过动态缓冲区选择,105秒内完成适配,轨迹误差随学习过程持续降低。
3.4 抗遗忘性:优于全量微调

对比“全量微调”与“LoRA微调”,全量微调后,模型在源域(SubT数据集)的性能显著下降(体现灾难性遗忘);而LoRA微调在适配目标域后,仍能保持源域的高精度定位。
四、创新点与局限性
4.1 核心创新
首个IMU基础模型:首次将“基础模型”理念引入惯性定位,通过大规模多平台数据学习通用运动知识,突破专用模型的泛化瓶颈; 高效适配机制:LoRA与在线适应结合,兼顾参数效率(1.1M参数)与实时性(200 FPS),满足机器人实际部署需求; 鲁棒学习框架:从数据增强(旋转等变性)到动态缓冲区(GMM聚类),全流程优化模型对异构数据与动态场景的适应性。
4.2 局限性
平台覆盖有限:目前支持汽车、无人机、腿式机器人、人类,尚未涵盖所有机器人类型(如特殊形态的工业机器人); 复杂运动挑战:GMM聚类对高度复杂的运动模式(如机器人杂技动作)可能失效; 数据依赖:泛化性能仍依赖大规模真实数据,尚未充分结合模拟数据扩展场景覆盖。
4.3 未来的研究方向
引入混合专家模型(MoE)以适配更多机器人平台; 融合真实与模拟 IMU 数据扩展场景覆盖; 开发无监督适应策略以减少对 SLAM 监督信号的依赖
总结
Tartan IMU为机器人惯性定位提供了全新范式——从“专用模型”走向“通用基础模型”,其框架不仅提升了定位精度与泛化性,更为多模态传感器融合、极端环境导航等领域提供了借鉴。随着技术迭代,轻量级、高适配的IMU基础模型有望成为机器人感知系统的核心组件。
论文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Zhao_Tartan_IMU_A_Light_Foundation_Model_for_Inertial_Positioning_in_CVPR_2025_paper.pdf#:~:text=To%20address%20these%20challenges%2C%20we%20present%20Tartan%20IMU%2C,IMU%20Model%20state%20estima-tion%20across%20diverse%20robotic%20platforms.
-- 完 --
机智流推荐阅读:
1. Code is Cheap,Show me your Prompt!Spec 将成为一统天下的编程语言
2. 打通投机采样最后一公里!SGLang联合美团技术团队开源投机采样训练框架
3. LLM智能购物助手革新电商体验!从直接搜索商品转向提出场景需求,揭秘香港科技大学等如何打造电商智能规划新标杆
4. Intern-S1发布8小时内,我用了8000万Tokens生成了3000篇ACL2025论文解读博客!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群