点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享人大与快手联合发布的专为训练多轮基于LLM的Agent而设计的ARPO算法。如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→大模型技术交流群
>>点击进入→Agent技术交流群
写在前面
当大语言模型(LLMs)开始像人类一样调用工具解决复杂问题时,一个关键挑战浮出水面:如何在长程推理与多轮工具交互之间找到平衡?
近期,中国人民大学与快手科技联合提出的 Agentic Reinforced Policy Optimization(ARPO) 算法,为这一难题提供了突破性解决方案。该算法通过捕捉工具调用后的「不确定性信号」,动态调整探索策略,在13个 benchmarks 中全面超越传统轨迹级强化学习方法,更惊人的是,它仅需一半工具调用预算就能实现性能提升。
大模型工具交互的「暗礁」:高熵陷阱与探索困境
在现实场景中,LLMs 往往需要借助搜索引擎、代码解释器等外部工具完成任务。例如,回答「2024年诺贝尔物理学奖得主是谁」时,模型需要调用搜索引擎获取实时信息;解决复杂数学问题时,则需通过 Python 解释器验证计算过程。
但现有强化学习(RL)算法在训练这类工具型智能体时,暴露出严重缺陷:
轨迹级采样的局限性:传统方法(如 GRPO、DAPO)专注于完整轨迹的采样与优化,忽视了工具交互后关键步骤的细粒度探索。 工具调用的不确定性:研究团队发现,LLMs 在接收工具反馈后,生成 tokens 的熵值会急剧上升(图1左)。这意味着模型在此时陷入决策迷茫,但现有算法无法针对性增强探索。 预算效率低下:为覆盖足够多的交互场景,现有方法需大量工具调用,导致训练成本高昂,难以规模化应用。

核心矛盾在于:工具反馈带来的信息冲击会重塑模型的推理分布,但轨迹级 RL 算法无法捕捉这种动态变化,导致模型在高不确定性步骤中探索不足,在低价值步骤中浪费资源。
ARPO 算法:用熵值导航的智能体训练框架

ARPO 的创新之处在于,它将工具交互后的「熵值波动」转化为探索导航信号,通过两大核心机制实现高效训练:

1. 基于熵的自适应滚动机制(Entropy-based Adaptive Rollout)
该机制动态平衡全局轨迹采样与步骤级分支采样,解决传统方法的探索效率问题:
初始化阶段:模型先生成 N 条全局轨迹,记录初始熵分布 ,剩余预算预留用于分支采样。 熵值监测:每次工具调用后,模型生成额外 tokens 计算当前熵 ,通过公式 量化不确定性变化。 自适应分支:当 超过阈值时,触发分支采样(Branch(Z)),从当前节点衍生 Z 条推理路径。例如,在搜索引擎返回多源矛盾信息时(高熵场景),模型会主动探索不同信息整合策略。 终止条件:当分支路径总数达到预算上限或所有路径完成推理时停止,确保资源高效分配。
这种设计使采样复杂度从轨迹级方法的 降至 到 之间,大幅提升训练效率。
2. 优势归因估计(Advantage Attribution Estimation)
为让模型有效学习步骤级工具使用策略,ARPO 设计了两种优势分配方式:
硬优势估计:明确区分轨迹中的共享段与独立段。共享 tokens 分配平均优势(),独立段则按各自奖励计算优势。 软优势估计:基于 GRPO 框架,通过重要性采样比 隐式区分共享与独立段。共享前缀的 相同,确保优势贡献对齐。
实验表明,软优势估计在训练稳定性和最终性能上更优(图5),因此成为 ARPO 的默认设置。

理论根基:广义政策梯度定理(GPG Theorem)
ARPO 的有效性可通过理论证明:将 Transformer 输出 tokens 划分为「宏动作」(MA)与「宏状态」(MS)后,政策梯度可分解为各宏动作梯度的总和:
这表明,ARPO 对轨迹的动态分割符合政策优化的数学本质,为其性能提升提供了理论保障。
核心贡献:从机制创新到效率突破
ARPO 的贡献可概括为四个维度:
发现工具交互的熵值规律:首次量化 LLM 在工具调用后的熵值跳变现象,揭示轨迹级 RL 算法的固有缺陷——无法应对工具反馈引发的分布偏移。
自适应探索机制:通过熵值信号动态分配探索资源,解决传统方法在高不确定性步骤中探索不足的问题,使模型能聚焦关键交互节点。
优势归因新范式:硬/软优势估计结合的设计,让模型有效内化步骤级工具使用经验,而非仅依赖最终结果反馈。
预算效率革命:在保持性能优势的同时,将工具调用预算削减50%,为大规模部署 LLM 智能体扫清成本障碍。
技术细节:训练框架与参数设计
ARPO 的实现基于冷启动微调(SFT)+ RL 范式,关键设置如下:
微调阶段:使用 LLaMAFactory 框架,在 Tool-Star 的54K 样本上训练,融入 STILL 数据集增强数学推理能力。 RL 阶段: 深度推理任务:采用10K 样本,全局滚动大小16,初始采样8,熵权重0.2。 深度搜索任务:仅用1K 样本,响应长度扩展至8192 tokens,训练5个 epoch。 奖励函数:综合正确性(Acc.)、格式合规性与多工具协作奖励(),例如同时使用搜索与代码工具时额外加0.1分。
实验验证:13个基准上的全面超越
研究团队在三大领域13个数据集上验证了 ARPO 的性能:
1. 数学推理与知识推理

在 AIME24、HotpotQA 等任务中,ARPO 显著优于 GRPO、DAPO 等方法:
Qwen2.5-7B 模型在 AIME24 上准确率达30%,超 GRPO 6.7个百分点; Llama3.1-8B 在 2WikiMultihopQA 上提升4.1个百分点,展现跨模型的普适性。
2. 深度搜索任务

在 GAIA、HLE 等需要复杂工具交互的场景中,ARPO 优势更为明显:
Qwen3-14B 模型在 GAIA 上准确率43.7%,远超 GRPO 的36.9%; 在高难度 HLE 数据集上,ARPO 实现10.0%的 pass@1 分数,而 GPT-4o 仅为2.6%。

3. 预算效率分析
ARPO 用一半工具调用量(约250次)达到传统方法500次调用的性能,在 WebWalker 任务中工具使用效率提升1.8倍(图7)。
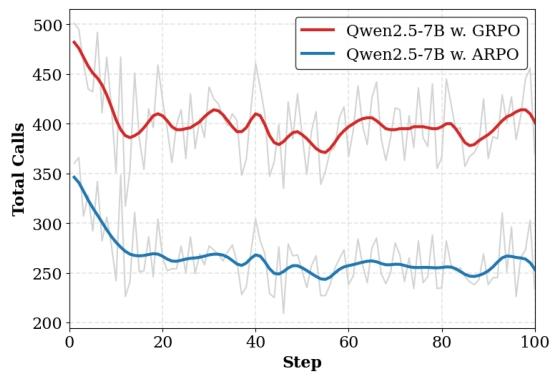
未来展望:让智能体更懂「动态交互」
ARPO 的提出为 LLM 智能体训练开辟了新方向:
多模态工具扩展:当前实验聚焦文本工具(搜索、代码),未来可将熵值机制扩展至视觉工具(图像解析)、物理工具(机器人控制)。 不确定性量化优化:如何更精准地建模工具反馈的不确定性(如搜索引擎结果的可信度评分),可能进一步提升探索效率。 实时环境适配:ARPO 的动态采样机制为实时系统(如自动驾驶决策)提供了新思路,可根据路况复杂度调整推理路径。
随着工具型智能体在客服、科研、教育等领域的普及,ARPO 所展现的「高效探索+预算友好」特性,或将成为行业标准训练范式。
参考
[1] Agentic Reinforced Policy Optimization (https://arxiv.org/pdf/2507.19849)
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











