点击下方卡片,关注“AI生成未来”
如您有工作需要分享,欢迎联系:aigc_to_future
1. CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
https://deepreinforce-ai.github.io/cudal1_blog/
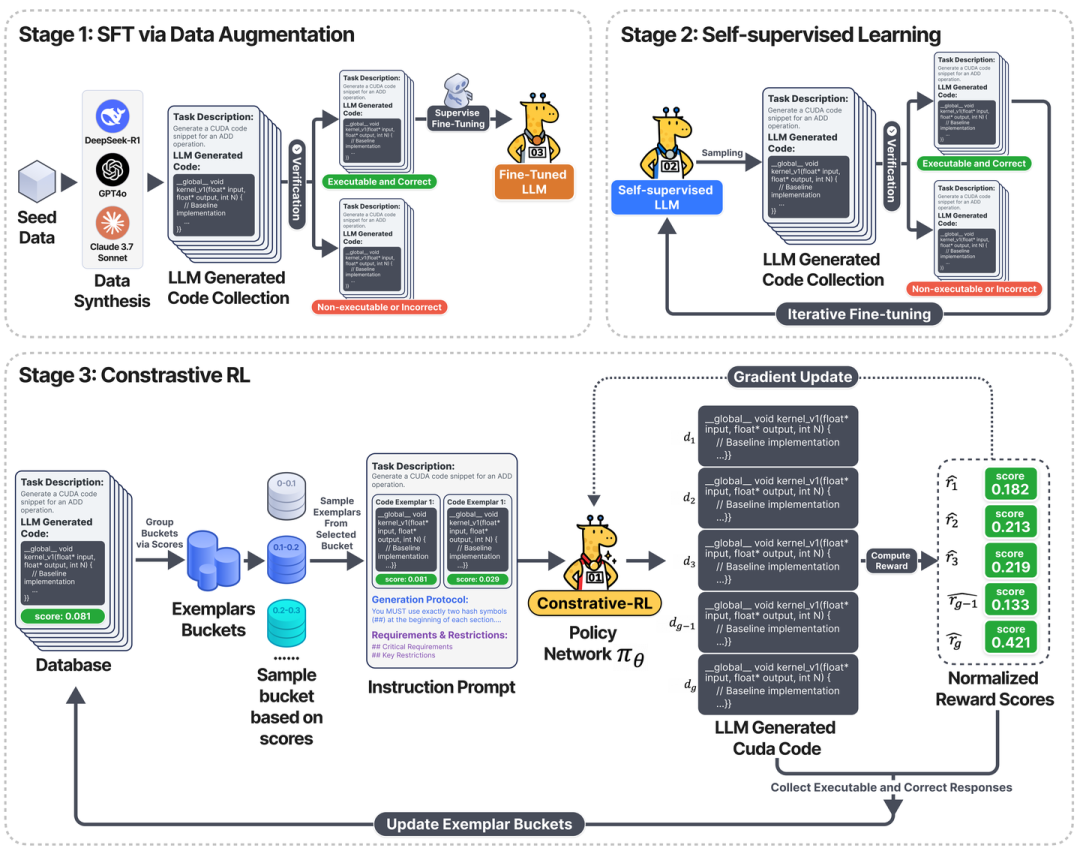
论文提出 CUDA-L1——首个基于对比强化学习的全自动 CUDA 优化系统。通过“SFT → Self-supervised → Contrastive-RL”三阶段,让大模型仅用“运行时间”作为 reward,便可自主发现、组合并泛化 CUDA 优化技巧,在 250 个真实 kernel 上实现平均 3× 以上、峰值 120× 的加速,且可跨 GPU 架构迁移。

三阶段训练
Stage 1:SFT+数据增强 → 保证代码可编译、正确。利用了六个现有的LLM模型:GPT-4 o、OpenAI-o 1、DeepSeek-R1、DeepSeek V3、Llama 3.1- 405 B指令和Claude 3.7,每一个LLM都进行了250条数据的推理,每个最多尝试20次。

Stage 2:Self-supervised 采样 → 进一步提升正确率。使用SFT模型重新采样得到结果,根据结果更新模型参数。这一步只关注生成代码的可执行性和正确性。

Stage 3:Contrastive-RL(核心贡献)
把“多条历史代码+真实 speedup”放进 prompt,让模型先写“性能分析”,再写新代码。
用 GRPO 做策略梯度更新;同时把高分代码回写数据库,形成“模型权重-代码库”协同进化。
prompt
·任务描述:计算问题的详细描述,包括输入/输出规范,性能要求和优化目标。
·具有分数的先前CUDA代码:先前生成的CUDA实现与其对应的性能分数配对(例如,执行时间、吞吐量、内存效率),提供了不同解决方案质量的具体示例。
·生成协议:定义所需输出格式和组件的明确指令。
·要求和限制:要求和限制,以防止RL中的奖励黑客。

解决 RL 在 CUDA 任务中的 Reward Hacking:
发现三种常见漏洞 • 额外 CUDA stream 绕过计时器 → 虚假 18× 加速。 • 篡改超参数(把 batch_size 改小)。 • 跨 batch 缓存计算结果。
提出三重防护 • 修改评测脚本:强制同步所有 stream。 • 引入对抗检测器(DeepSeek-R1)+动态 hack-case 数据库,实时识别异常高分。 • 奖励平滑:对突发大 reward 做 clip(±1.5σ),降低梯度吸引力。

结果

• CUDA-L1 平均加速 3.12×(中位 1.42×),最高 120×;249/250 成功编译运行,240/250 带来实际加速。 • 跨架构移植:L40 3.12×、RTX3090 2.50×、H100 2.39×、H20 2.37×。 • Ablation: – – 仅用 SFT 22% 带来加速;加入 Self-sup 66%;换成普通 GRPO 88%;完整 Contrastive-RL 96%。 – – Evolutionary-LLM 最好 72%,明显低于可更新参数的 RL 方案。
结论:Contrastive-RL 能持续自我改进,显著优于固定权重或纯 prompt 方法,且优化可迁移到不同 GPU。
基于GPT-4o的技术术语提取和频率分析,确定了十大最流行的优化技术:
1. 内存布局优化,确保数据存储在连续的内存块中;
2. 内存访问优化,它通过共享内存使用、合并全局内存访问和内存填充等技术来安排数据访问模式,以最大化内存带宽并最小化延迟;
3. 操作融合,它将多个顺序操作组合成一个优化的内核执行;
4. 内存格式优化,使数据布局与硬件内存访问模式保持一致;
5. Memory Coalescing,通过确保相同warp中的线程访问连续的内存位置来优化CUDA内核性能;
6. Warp-Level Optimization,利用线程在一个线程束内的并行执行(通常为32个线程)来高效地执行集体操作;
7. 优化的线程块配置,它仔细选择网格和CUDA内核块尺寸,以最大限度地提高并行执行效率和内存访问模式;
8. 共享内存使用,通过将频繁使用的数据存储在线程块内的所有线程可访问的高速缓存中来实现快速数据访问;
9. 寄存器优化,将频繁访问的数据存储在快速寄存器存储器中,以减少延迟并提高计算吞吐量;
10. 流管理,支持并行执行操作,以提高GPU利用率。

2. Agentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
现有模型要么缺乏金融领域特定知识,导致在金融相关任务中表现不佳;要么容易产生幻觉,违反金融环境中严格的安全性和合规性要求。
论文提出了Agentar-Fin-R1系列金融大型语言模型来解决上述问题,第三节主要介绍了数据验证与检查、训练方法等。以下是详细介绍:

数据验证与检查
数据源治理:从权威金融机构和监管机构获取可靠数据,并运用知识工程技术确保数据完整性和领域相关性,包括数据提取、标准化、解耦和精炼等步骤。
数据合成:设计双轨数据合成流程,结合领域导向生成与自我进化指令改进,生成高质量、可验证的推理三元组(问题、思考、答案)。
验证与检查:实施多级验证框架,通过多模型集成验证、一致性验证、推理验证以及人工标注和质量控制等方法,确保数据质量、准确性和可靠性。

训练方法
加权训练框架:提出一种动态调整任务重要性的加权训练框架,根据任务实例的难易程度分配权重,优先关注模型表现不佳的复杂任务,以改善模型在复杂金融任务上的性能,同时保持对简单任务的学习效率。
两阶段训练流程:采用两阶段训练策略。第一阶段通过监督微调(SFT)在多样化金融任务上进行广泛的知识和能力注入;第二阶段结合广义强化学习优化(GRPO)和针对性微调,专门优化挑战性任务的性能。
归因循环:作为一种训练后的优化机制,通过追踪特定金融场景和任务中的错误,实现针对性的数据采样和模型增强。

基于Qwen3-8B/32B-Instruct微调得到的Agentar-Fin-R1-8B/32B得到了最佳的效果。


3. Enhancing Step-by-Step and Verifiable Medical Reasoning in MLLMs
论文介绍了MICS(Mentor-Intern Collaborative Search),一种多模型协作搜索策略,用于生成高质量的多模态医学推理数据,并提出了MMRP数据集,基于InternVL3-8B微调得到了Chiron-o1模型。

MMRP数据集的构建
Part 1:简单问答对(QA):基于临床案例文本信息,生成适合医学实习生水平的QA对。超过 6 万个包含纯文本信息的病例,涵盖神经系统疾病、心血管异常、骨骼系统疾病等。
Part 2:图像—文本对齐数据:使用真实医学图像及其分析,生成图像—文本对齐数据,避免幻觉信息。
Part 3:多模态CoT数据:利用MICS策略生成复杂医学场景的多模态推理路径。
MICS策略
多导师协作搜索推理路径:多个导师模型从起点或上一轮选择的最佳路径开始,生成完整的解决方案。
基于MICS-Score的推理路径评估:利用实习生模型对导师模型生成的推理路径前缀进行评估,计算其MICS-Score。
选择最佳推理路径:根据MICS-Score选择当前搜索迭代中最佳的推理路径前缀,继续下一步搜索,直至达到最大深度或提前停止条件。
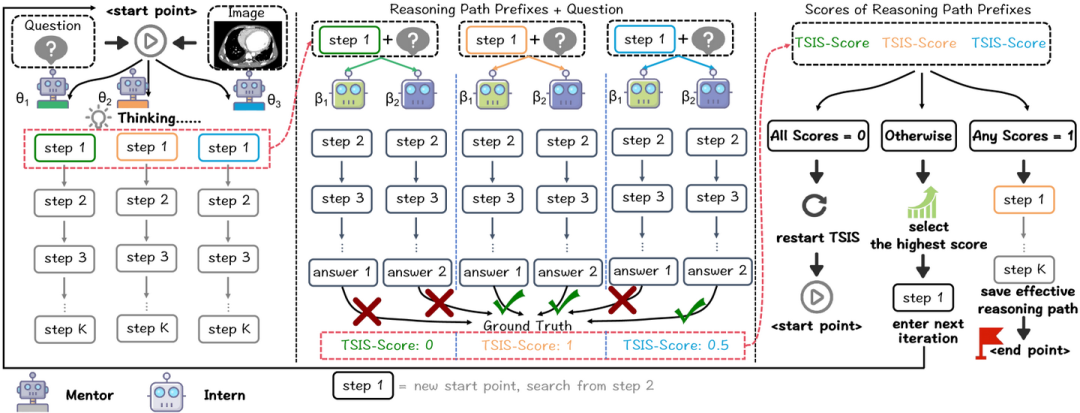
简而言之就是多个small LLM根据question和large LLM的回复进行回答,根据回答正确的数目占比作为large LLM的回复score,选择最佳score作为当前结果。循环此过程,得到最佳回复trace。
Chiron-o1的多阶段SFT训练策略
阶段1:训练模型回答简单的医学问题并提供简要解释。
阶段2:利用真实临床图像及其分析,使模型熟悉医学图像特征,实现图像—文本有效对齐。
阶段3:利用MICS生成的高质量CoT数据,提升模型的推理能力。

4. MedGemma Technical Report
论文介绍了MedGemma,这是一套新的医疗视觉-语言基础模型,基于Gemma3-4B和27B。MedGemma在医疗多模态问答、胸部X光发现分类和代理评估方面分别实现了2.6-10%、15.5-18.1%和10.8%的改进。微调MedGemma可以进一步提高子领域的性能,例如将电子健康记录信息检索中的错误减少50%,并达到与现有专门方法相当的性能,用于气胸分类和组织病理学补丁类型分类。
论文还介绍了MedSigLIP,这是一个从SigLIP衍生的医疗调优视觉编码器,为MedGemma的视觉理解能力提供支持,并且作为编码器,其性能与或优于专门的医疗图像编码器。

数据集(通用+领域):作者使用了SigLIP和Gemma3的原始数据混合进行通用的数据回放。医疗训练和评估数据集主要遵循Med-Gemini的数据集。具体变化包括对文本数据集和多模态数据集的调整,例如移除了存在数据质量问题的PathVQA和MedVQA数据集,增加了眼科和皮肤科的内部数据集等。
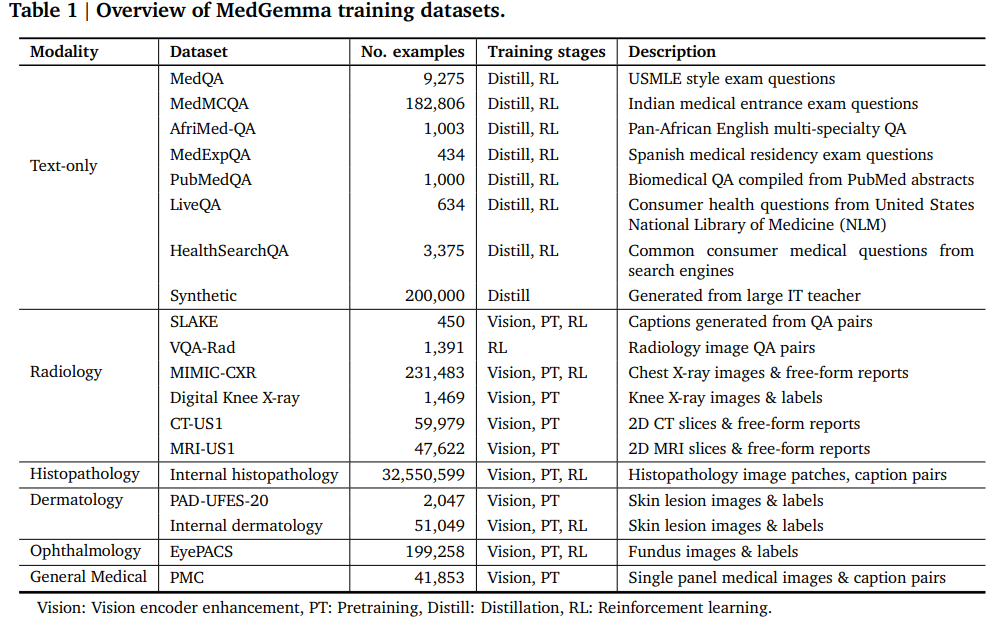
数据预处理:图像填充和调整大小算法保持不变,但由于Gemma 3的视觉编码器不同,图像被调整为896×896大小(而非768×768)。使用SentencePiece分词器,包含262,000个条目。对于CT图像,预选三种窗口并将其转换为输入图像的RGB颜色通道,以突出不同的组织结构。
模型架构和训练基础设施:MedGemma模型架构遵循Gemma 3,并与其所有现有基础设施兼容。视觉编码器为Gemma 3中的400M SigLIP编码器变体,适用于不同大小的Gemma语言模型。输入图像分辨率为896×896,像素值归一化至[-1,1]。语言模型组件同样遵循Gemma 3,支持任意图像-文本交错和长上下文(128k)。MedGemma在TPUv4、TPUv5e和TPUv5p上进行训练,利用预计算的视觉令牌节省内存,并使用数据和模型分片进行多pod训练。
模型训练:MedGemma 4B多模态模型利用了所有以下步骤,而文本专用的MedGemma 27B则利用了后训练阶段。
视觉编码器增强:使用超过33M的医学图像-文本对(包括635k来自各种医学模态和32.6M组织病理学补丁)对Gemma 3中的SigLiP-400M视觉编码器进行了微调,以提高其编码和区分医学图像细微差异的能力。在训练过程中保留了SigLIP的原始训练数据,并以2%的权重混合医学数据。
多模态解码器预训练:在增强视觉编码器后,Gemma语言模型需要重新适应新的视觉编码器,不仅针对医学数据,还针对通用图像领域,以保留视觉-语言推理能力。此目标通过在预训练阶段结合原始混合文本和交错成像数据以及新引入的医学领域图像-文本网格数据来实现。
后训练:预训练中获得的知识需要在后训练阶段显现为能力。后训练包括两个主要组件:蒸馏和强化学习(RL)。蒸馏过程中增加了医学文本数据,使模型能够进一步从大型指令调优(IT)教师模型中学习。在强化学习阶段,使用了与文本配对的医学成像数据。对于多模态训练,发现RL比监督微调能实现更好的泛化,因此所有多模态后训练均通过RL进行。

效果如下



5. Gazal-R1: Achieving State-of-the-Art Medical Reasoning with Parameter-Efficient Two-Stage Training
论文介绍了Gazal-R1,这是一个320亿参数的语言模型,它通过两阶段的训练流程在医疗推理方面达到了最先进的性能。该模型基于Qwen3-32B,并结合了监督微调和基于GRPO的强化学习。
第一阶段:监督微调(SFT)
数据集策划:作者创建了一个包含107,033个示例的合成数据集,用于教授结构化的临床思维。还结合了现有的MedReason数据集,后者包含32,682个高质量的医疗问答对,每个问答都有详细的逐步解释。
架构考虑和技术:在SFT过程中,作者采用了先进的参数高效微调技术,包括DoRA(权重分解低秩适应)和rsLoRA(秩稳定的LoRA),以最大化性能同时管理计算资源。
训练过程和超参数:使用了2个NVIDIA H100 GPU、48vCPUs和480GB RAM的硬件设置,使用EXAdam优化器进行训练,并采用了系统提示,明确指示模型遵循特定格式。
第二阶段:组相对策略优化(GRPO)
算法选择:GRPO被选为强化学习算法,因为它不需要单独的价值函数,从而减少了内存开销。
数据集策略:使用了UltraMedical数据集的一个随机打乱的10%子集进行训练,以增强泛化并加速策略收敛。
增强的GRPO实现:为了提高训练稳定性,作者采用了信任区域扩展和Clip-Higher策略,消除了KL散度惩罚,并实现了高级损失归一化。
6. Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards
论文提出了Med-PRM,一种用于医学推理的过程奖励模型框架。该框架通过检索增强的逐步验证来评估推理过程中的每一步,确保推理的准确性和透明度。Med-PRM结合了检索增强生成和大型语言模型作为评判者,能够精确定位和纠正推理步骤中的错误。

具体方法如下:
1、检索增强的逐步验证(RAG-AS-A-JUDGE):该方法结合了检索增强生成和大型语言模型作为评判者的角色。对于每个医学问题,模型会检索相关的医学文档,并对推理过程的每一步进行评估。具体步骤包括:
问题和文档检索:给定一个问题,模型从医学知识库中检索相关文档。
推理路径生成:生成多个可能的推理路径。
逐步标注:使用大型语言模型对每一步推理进行标注,判断其是否正确。
训练数据构建:将标注后的推理路径用于训练过程奖励模型。
2、过程奖励模型(PRM):PRM通过评估推理过程中的每一步来提供奖励,而不仅仅依赖最终结果。模型使用交叉熵损失函数进行训练,以最小化预测分数与真实标签之间的差异。
3、自动标注策略:为了避免昂贵的人工标注,论文提出了一种基于检索的事实核查方法。通过检索相关文档来验证每一步推理的正确性,从而生成训练标签。
4、测试时计算扩展:在推理阶段,使用最佳候选答案选择(Best-of-N)和自洽性加奖励模型(SC+RM)策略来提高模型的性能。
5、策略模型微调:通过拒绝采样和奖励模型引导的微调来优化策略模型,使其生成的推理路径更符合医学标准。


7. A Practical Two-Stage Recipe for Mathematical LLMs: Maximizing Accuracy with SFT and Efficiency with Reinforcement Learning
论文的核心是提出了一种提升大型语言模型(LLMs)数学推理能力的两阶段训练方法。首先通过长时间的监督微调(SFT)建立性能基线,然后利用基于在线推理的强化学习(RL)方法GRPO来优化解决方案长度,从而在保持高准确性的同时提高token效率。
论文提出了一种两阶段的训练方法:
第一阶段:监督微调(SFT):使用特别策划的高难度数学推理问题数据集进行密集的SFT。数据集整合了来自不同来源的数据,包括OpenR1 Math、openr1 hard数据集和Light-R1-SFT Data,并去重处理,最终得到7900个问题-解决方案踪迹-答案三元组。在训练过程中,采用全参数微调,使用8个NVIDIA H200 GPU,每个设备的训练批次大小为1,梯度累积步数为8,训练持续10个周期,最大序列长度设置为24000,并启用数据打包。学习率为1e-5,采用余弦学习率调度器。
第二阶段:GRPO增强令牌效率:在SFT阶段之后,使用GRPO来提升模型的令牌效率。GRPO的奖励函数包含三个关键部分:格式奖励(根据输出结构是否符合预期给出二进制信号)、余弦相似性奖励(衡量生成推理踪迹与参考正确踪迹的余弦相似度)和长度惩罚(根据生成输出的长度进行惩罚)。GRPO训练配置了8个生成次数和0.04的beta值,每个设备的训练批次大小为2,梯度累积步数为8,训练持续50步,最大完成长度为16384,学习率为4e-6,同样采用余弦调度器。

论文提出的结合SFT和GRPO的训练方法能够有效提高LLMs在数学推理方面的准确性和效率。
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











