本篇选自Semi Version的长文深度解析Marvell如何以全栈定制战略重塑AI芯片基础设施。面对云巨头3270亿美金AI投资浪潮,传统GPU架构遭遇成本与能效瓶颈。Marvell凭借XPU+Attach双轨架构(18款定制芯片落地)、6.4Tbps硅光引擎及2nm级封装集成,构建从SRAM缓存优化到光互连的完整技术闭环。文章揭示其颠覆性创新:定制SRAM面积减半功耗降66%,448G SerDes突破带宽极限,更以XPU Attach组件90%增速卡位模块化AI生态——这不仅关乎单点技术突破,更是算力基础设施的范式革命。欢迎感兴趣的读者转发与关注!
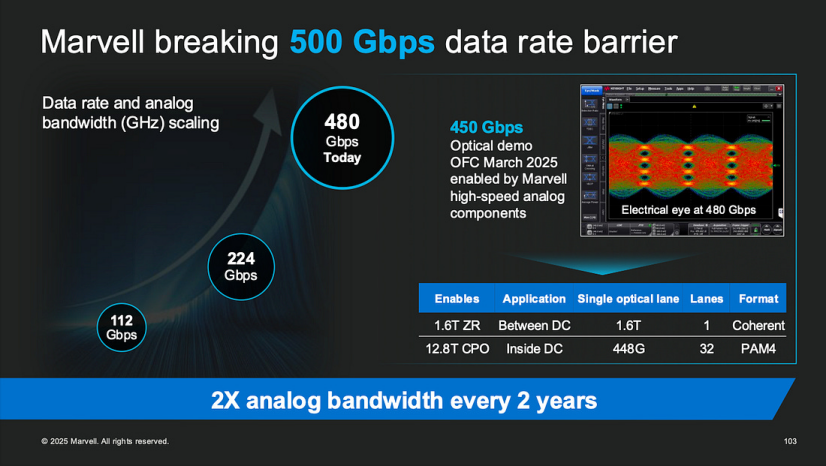
1.XPU 与 XPU附属芯片:系统角色与可扩展性Marvell 将定制计算生态系统分为两大类:XPU(主要计算芯片,如 CPU、GPU 和加速器)和 XPU附属芯片(提供网络、内存、管理和 I/O 功能的配套芯片)。虽然 XPU 作为核心计算引擎,但 XPU附属芯片 则包含网络接口、内存控制器、系统管理协处理器和安全/压缩引擎等元素,以提升整体系统性能。根据 Marvell 的数据,定制 XPU 市场预计到 2028 年将达到 408 亿美元,复合年增长率 (CAGR) 为 47%。然而,XPU附属芯片 领域的增长速度更快,估计 CAGR 接近 90%。在 Marvell 迄今为止部署的 18 个定制 ASIC 中,有 3 个是 XPU 设计,9 个是来自超大规模客户项目的附属芯片;新兴客户贡献了另外 2 个 XPU 和 4 个附属芯片——这表明超过三分之二的部署是附属类组件。在不断演变的服务器格局中,这些配套芯片正成为架构设计的核心。它们在高带宽连接、内存池化、系统级安全和性能优化方面提供关键功能。Marvell 提供全栈式解决方案——从机架级协作到 IP 设计、先进封装和大规模制造——使客户能够快速构建定制系统。随着 AI 芯片向模块化和异构集成发展,XPU附属芯片 组件正成为性能扩展和系统级内聚力的关键赋能者。虽然市场曾经只关注主要计算芯片(例如 GPU、NPU、DPU),但现在很明显,支持性基础设施——高速互连、内存编排、I/O 和安全——对平台性能至关重要。历史上被视为次要角色的配套芯片,如今在数据密集型、高吞吐量的 AI 系统中至关重要。如果没有 SerDes 接口、光收发器控制器、内存访问单元或 PCIe/CXL 引擎的强有力支持,即使是最强大的加速器也会表现不佳。XPU附属芯片 市场正超越核心 XPU 领域。到 2028 年,其规模预计将达到 146 亿美元,惊人的 CAGR 为 90%。在 Marvell 已部署的 18 个芯片插槽中,只有 5 个是主要 XPU 设备,而其余 13 个是附属芯片。此外,在超过 50 个潜在合作项目中,近三分之二是面向附属芯片的——突显了市场对模块化配套芯片日益增长的需求。·通过将 I/O 和内存功能从主 XPU 卸载,提升性能·由于标准化 IP 复用,为 ASIC 供应商带来更高的毛利率机会与那些纯粹专注于核心计算的厂商不同,Marvell 的战略核心是附属芯片——提供能与任何 XPU(包括来自第三方供应商的 XPU)无缝集成的协作组件。这使得 Marvell 能够深入参与 AI 平台设计,而无需直接在 XPU 竞赛中竞争。其附属芯片产品组合——包括高速 SerDes、CPO 光学模块和 HBM 内存控制器——构成了一个用于可扩展、高效数据基础设施的连贯解决方案堆栈。AI 芯片市场正从单片式超级芯片向模块化、分解式系统过渡。XPU附属芯片 是这一演进的核心。这些配套芯片为下一代平台注入了性能、灵活性和集成效率,同时为创新和商业成功开辟了新途径。Marvell 对附属芯片技术的深度投入,使其成为未来 AI 基础设施的关键参与者,确保其在数据中心计算架构的持续转型中扮演核心角色。随着数据流的持续激增,附属芯片组件的重要性只会增加——最终将与 XPU 核心并肩而立,成为 AI 计算平台的平等支柱。随着 AI 训练和云计算工作负载激增,互连接口必须突破现有局限。Marvell 处于前沿,正在 3nm 工艺节点开发基于 DSP 的先进 SerDes,实现每通道 200–224Gbps 的速度,以支持跨卡和主机间连接。在 DesignCon 演示中,Marvell 展示了其 224G 长距离 SerDes 通过 2 米铜缆以每通道 200Gbps 的速度传输——几乎是传统 100G 链路带宽的两倍。这些高端 SerDes 需要强大的均衡和低损耗通道设计,以克服在电缆和插槽上超高频率下严重的信号衰减。通过利用先进的 DSP 技术,Marvell 的 SerDes 接收器能够重建具有闭合眼图的信号,实现高达 50dB 插入损耗的米级传输——且无数据丢失。芯粒间(D2D)互连既是一项挑战,也是一项突破。Marvell 的目标是实现每毫米 50Tbps 的芯粒间带宽密度和低于 0.1pJ/bit 的能效。在 2nm 平台上,Marvell 最近展示了一个双向 3D 芯粒堆叠接口,每通道速率达到 6.4Gbps。理论上,在使用 2.5D、3D 或 3.5D 配置组装多芯粒系统时,这可以将带宽翻倍并将引脚数量减半。这种先进的封装互连对于最小化核心间距离和提高内存计算密度至关重要。在共封装光学(CPO)领域,Marvell 将硅光子引擎与芯片级封装集成,以实现超长距离、高带宽连接。其定制 AI 加速架构将 XPU 计算芯粒、HBM 和其他芯片与 Marvell 的 3D 硅光子引擎集成在单一基板上,通过高速 SerDes、D2D链路和先进封装连接。这使得数据可以在芯片之间以光学方式传输,而无需依赖传统的铜缆或 PCB 走线。Marvell 强调,此类光学链路的速度比基于铜的链路快 100 倍,传输距离远 100 倍。将硅光子技术嵌入封装内部,显著缩短了电路径长度,最大限度地减少了频率响应损耗并降低了延迟。例如,Marvell 的 6.4Tbps 光子引擎集成了 32 个 200Gbps 的光学 I/O 通道。与传统的 100Gbps 系统相比,该解决方案将带宽和 I/O 密度提高了一倍,同时将比特级功耗降低了约 30%。其最新的 1.6Tbps 光子引擎,具有 8 个 200Gbps 通道,专为线性可插拔光学(LPO)模块优化,实现了低于 5pJ/bit 的能效,大大提升了中型机架内的互连性能和可靠性。总之,Marvell 的超高速 SerDes 和集成硅光子引擎正成为下一代 AI 服务器的关键构建模块——实现多卡、跨主机甚至跨数据中心的高带宽、低延迟互连。https://tspasemiconductor.substack.com/p/from-custom-sram-to-optical-serdes