“编者按:当AI竞赛的焦点不再仅仅是更大,而是转向更聪明时,我们正迎来一场深刻的范式革命。
本文深入剖析了xAI对「强化学习」的战略重注,这不仅是技术路线图上的关键转向,更揭示了AI迈向解决真问题的本质进化。
传统训练方式,已无法让大型人工智能模型在复杂的推理任务上更进一步,它们正集体撞上一面无形的墙。
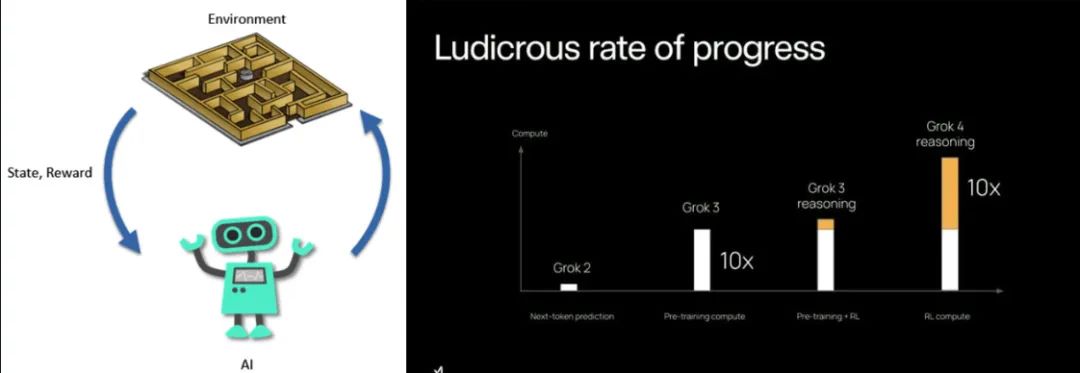
面对这一瓶颈,xAI 果断采取行动,为其最新模型 Grok 4 的强化学习训练,投入了比以往多出10倍的计算能力。
这项豪赌只有一个目标:教会 AI 解决那些仅靠通用训练无法攻克的极端难题。
Grok 4 不再仅仅是吞食海量数据,而是像学生在专家指导下攻克难题一样,通过反复试错来实践高难度问题。
尽管计算成本高昂,但这种新颖策略收效甚丰。Grok 4 不仅在多个领域展现出博士级别的水平,更在推理基准测试中刷新纪录。
这雄辩地证明了,有针对性的后训练微调,能够带来仅靠蛮力预训练无法企及的突破。
在表象之下,xAI 的路径选择标志着 AI 发展范式的深刻转变。
各大实验室正将重心转向后训练微调,尤其是强化学习,视其为通往更强智能的捷径,而非继续依赖扩大预训练规模。
OpenAI、DeepMind 等公司虽早已涉足强化学习,用于模型对齐或游戏博弈,但 xAI 的 Grok 4 将其推向了前所未有的核心地位。
本报告将深入剖析强化学习的运作原理、xAI 的战略抉择、其与竞争对手的异同,及其对整个 AI 未来的深远影响。
一言蔽之,xAI 重注强化学习,志在将 AI 智能推向新高。这预示着,AI 的下一次飞跃,或将取决于教模型如何思考,而非仅仅读过什么。
核心概念:强化学习与预训练的本质区别

强化学习的灵感源于人类的试错学习机制——AI 做对了就获得奖励,做错了就接受惩罚。
历经万千次的试炼,AI 会逐渐摸索出最大化奖励的最优策略。
在象棋或围棋这类游戏中,奖励非常明确:赢得比赛。每一步棋的价值,都由它是否导向最终胜利来衡量。
正是这种清晰的反馈,让 AI 能高效学习好棋、摒弃坏棋。DeepMind 的 AlphaGo 正是通过数百万次自我对弈,才练就了超凡的棋力。
相比之下,语言模型的传统预训练,更像是一场漫无边际的阅读马拉松。
AI 从浩如烟海的文本中吸收语言模式,学会预测下一个词,从而获得广博的知识基础和语言流畅性。
然而,这种方式并未教会模型如何去实现特定目标,也无法让它主动验证答案的正确性。
本质上,预训练模型是统计学意义上的鹦鹉,它们只输出看似合理的文本,却不理解内容是否真的正确。
这正是后训练微调,特别是强化学习登场的时刻。微调好比是模型在博览群书后,接受的专业辅导。
其中,基于人类反馈的强化学习(RLHF)是 OpenAI 用于训练 ChatGPT 等模型的关键技术。
在 RLHF 中,人类评估员对 AI 的回答进行评分,模型则根据评分反馈进行调整,从而学会生成更真实、更有用、更无害的内容。
值得注意的是,OpenAI 曾表示,RLHF 阶段的计算成本与预训练相比微不足道,它更像是在坚实基础上的一层精细抛光。
xAI 对 Grok 4 的策略则彻底改写了剧本:强化学习不再是锦上添花的微调,而是被提升为核心环节,其计算资源的投入规模,甚至逼近了预训练本身。
究其原因,在于强化学习能够主动驱使模型攻克复杂的多步骤难题,并从中获得成败的直接反馈——这是传统训练望尘莫及的。
简而言之,预训练给了 Grok 广博的通识教育,而强化学习则是一场严苛的研究生院修行,让模型在实践与纠错中学会解决真正棘手的任务。
预训练的极限与强化学习的崛起
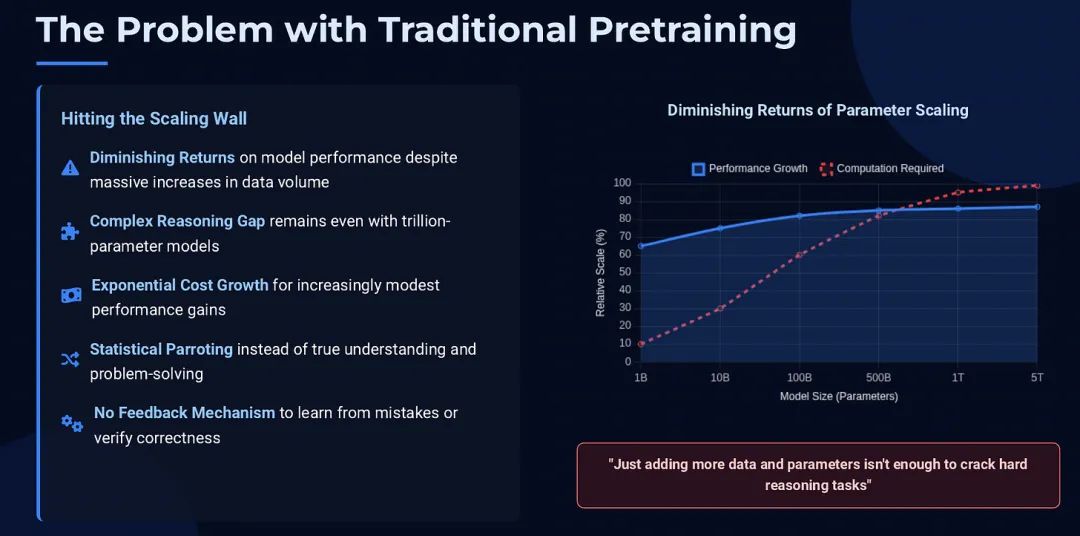
对于最前沿的 AI 模型,单纯增加阅读量或参数规模,已难以在推理能力上带来质的飞跃。
试想一个问题:“请设计一个能解决能量泄漏问题的实验性核聚变反应堆。”
一个庞大的预训练模型或许能洋洋洒洒地写出一篇看似专业的文章,但其内容很可能包含着微妙甚至荒谬的错误。
因为它从未真正解决过此类问题,只是在模仿它读过的论文,缺乏对其方案可行性的真实反馈。通用知识并不等同于专家级的解题能力。
当模型的知识储备接近人类时,它的短板便暴露无遗——即如何应用知识去解决那些新颖且艰深的难题。
过去,强化学习在目标明确的领域所向披靡:赢得比赛、到达终点、获得高分。成功与否,一目了然。
然而,开放式任务缺乏天然的记分牌。当要求设计反应堆或证明定理时,我们如何判断对错?
xAI 等机构的突破口,在于引入经由专家验证的挑战,作为强化学习的赛场。
他们与专业数据公司合作,聘请物理、数学等领域的专家,设计出顶尖模型也无法轻易解答的难题。
至为关键的是,专家们也为这些难题提供了标准答案。这为衡量成功创造了条件:只有当 AI 的答案与专家方案一致时,才给予奖励。
这种方法巧妙地将复杂的开放任务游戏化了:AI 在玩一种解题游戏,胜利的标志就是找到人类专家设定的那个黄金标准答案。
“如今,强化学习正驱动着一种远比过去更高效的性能爬山过程,全球顶尖的实验室无不投入重兵和算力,力求占得先机。
xAI 如何引爆 Grok 4 的推理引擎

Grok 4 的训练远不止于消化网络文本。预训练之后,它进入了一场围绕专家级问题的强化学习特训营。
这个过程对计算资源的需求极大,其核心步骤如下:
收集专家级挑战
xAI 打造了一个横跨多领域的超高难度问题库,这些问题都是 Grok 3 的噩梦,旨在将新模型的潜力推向极限。
规模化的试错
Grok 4 会对每个问题发起成百上千次的解答尝试。每一次尝试都因模型的内在随机性而略有不同,如同让一个学生进行头脑风暴。
筛选成功的金块
在海量的尝试中,总有少数幸运或极具洞察力的解答能够命中正确答案。这些成功的尝试,就是最宝贵的训练素材。
从胜利中学习
接下来便是强化环节。模型会基于那些成功的解答进行微调,这无异于告诉它:“像这样思考和推理。” Grok 4 由此归纳出通往正确答案的思维模式。
循环往复,内化能力
这个流程在海量问题上不断重复。久而久之,模型不再是记忆答案,而是真正内化了解决同类挑战所需的问题解决方法。
这套策略本质上是通过 AI 自我生成的成功范例进行强化学习,其代价高昂,因为每一次尝试都意味着一次完整的计算过程。
xAI 透露,Grok 4 在这一阶段的计算消耗,是 Grok 3 同类训练的十倍之多。
成本与回报:一场值得的豪赌?
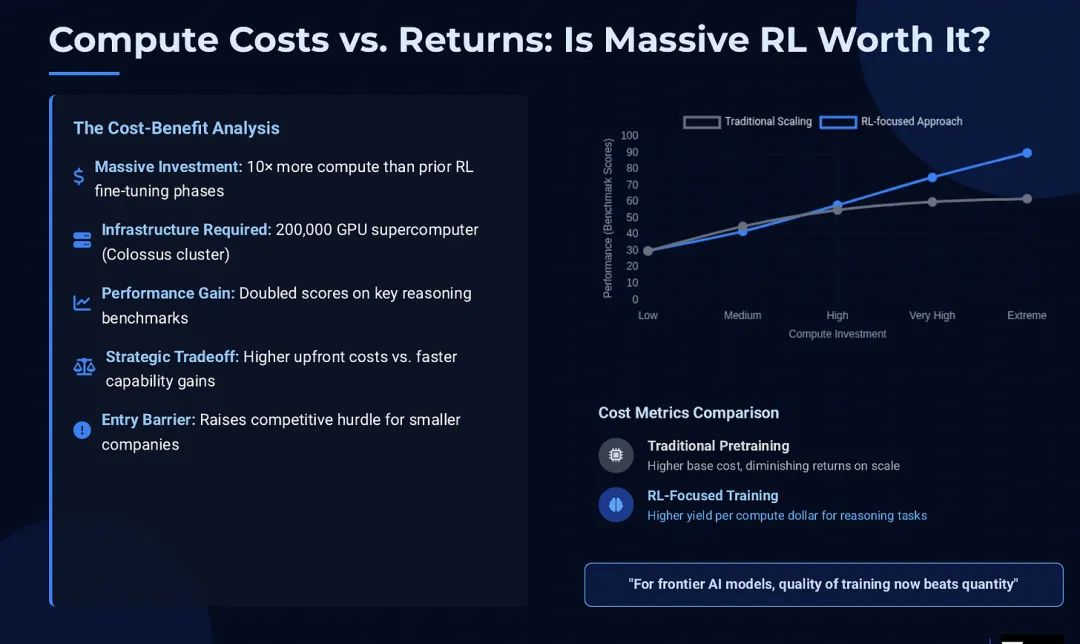
xAI 为何要投入如此惊人的计算资源?答案在于其背后的高回报。
强化学习的计算成本极高,因为它并非一次性读取数据,而是与数据进行反复的、迭代式的实战对抗,直至模型精通为止,这自然会消耗海量的 GPU 资源。
但高昂的投入换来了飞快的进步速度。与其耗费数月乃至数年等待下一代更大规模的模型,不如在现有模型上,用数周时间通过强化学习实现能力跃迁。
xAI 的策略证明,加大对强化学习的投入,可以比单纯扩大模型规模,更快地获得性能回报。这好比精细的战术指导,往往比单纯的体格增长,更能立竿见影地提升运动员的赛场表现。
当然,这也意味着巨大的门槛。并非所有公司都能效仿 xAI 的大手笔。
xAI 此举显示出一种强烈的决心:在无法迅速超越对手模型规模的情况下,就通过让模型更聪明来实现赶超。
它开创了一个先例:AI 的前沿阵地,不仅需要大规模预训练,更需要大规模后训练。
竞争格局:巨头们的强化学习之道
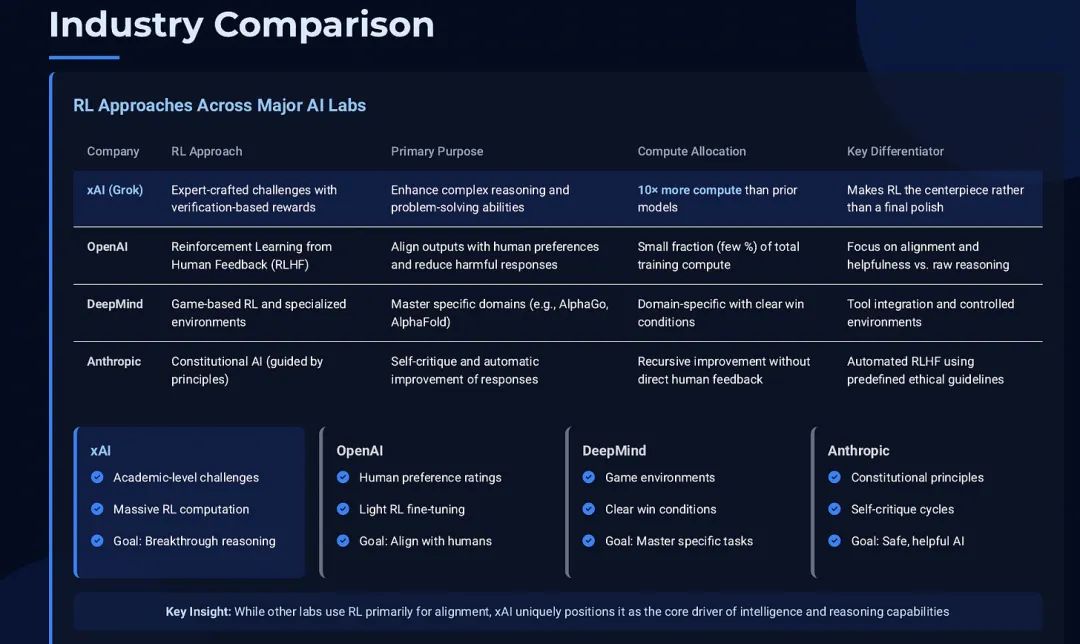
xAI 并非强化学习的唯一信徒,但它将这一理念推向了新的高度。
OpenAI (ChatGPT/GPT-4)
OpenAI 通过 RLHF 技术,让模型学习人类的偏好,变得更有用、更安全。但这更多是画龙点睛式的抛光,而非训练的核心,计算成本占比极低。其重点在于对齐行为与风格,而非攻克顶级智力挑战。
DeepMind
DeepMind 在强化学习领域战功赫赫,但其经典应用(如 AlphaGo)多在游戏等规则明确的领域。在语言模型上,他们也探索用强化学习实现安全对话或辅助推理,但尚未披露过类似 xAI 这种规模的、针对开放学术问题的训练。
Anthropic (Claude)
Anthropic 采用「宪法 AI」的思路,让 AI 根据一套预设原则进行自我批判和改进。这是一种更自动化的强化学习循环,再次印证了强化学习正成为大模型训练的标准配置,无论反馈是来自人类还是 AI 本身。
成果斐然:Grok 4 的表现与冲击

支撑 xAI 这场豪赌的,是 Grok 4 惊人的成果。
所有报告均显示,Grok 4 在智能和问题解决能力上,已一跃进入全球顶尖行列,在众多基准测试中追平乃至超越了最前沿的模型。
人们用“在所有领域都展现出博士级的智慧”来形容它的表现,这绝非一句寻常的赞美。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










