
今年GTC开发者大会之上,NVIDIA发布了名为NVIDIA Photonics的CPO(共封装光学)交换芯片,预计下半年就要用到其Quantum-X Photonics交换机之中;同时博通Tomahawk 6交换芯片大火,单芯片达成的交换容量可达102Tbps——且同时支持可插拔光模块和CPO...
加上AI数据中心市场持续火热,CPO显然成为时下的热议话题。《电子工程专辑》杂志9月刊封面故事将以CPO为题,谈谈光通信技术在数据中心领域的应用和发展情况。
在最近的WAIC世界人工智能大会上,曦智科技就和燧原科技合作,推出了国内首款xPU-CPO光电共封装原型系统——和前述数据交换端的应用不同,这是在GPU算力端的光电共封装,虽然只是个“原型系统”,亦表现出CPO技术在AI数据用心应用的前景。
除此之外,曦智科技还展示了光互连光交换芯片,和基于这颗芯片的“全球首个分布式光互连光交换GPU超节点解决方案”光跃LightSphere X。基于这两项展示,我们大致能从中窥见曦智科技眼中,乃至整个AI算力市场,光通信技术将发挥的潜在价值——毕竟当所有人都在WAIC上谈论“万卡计算”“超节点”这类话题时,更高效的光互连、光交换芯片与方案会越来越成为刚需。

“xPU-CPO光电共封装”的技术价值
有关为什么要发展CPO的问题,电子工程专辑在过去谈NVIDIA Photonics的文章里已经有过阐述:简单来说,巨量参数规模的AI大模型训练和推理并不是单张显卡或AI加速卡能完成的——AI计算的跨芯片、跨板卡、跨节点是必然。
是德科技在前不久的媒体活动上谈到,对于某特定AI集群,在做ViT模型这类AI CV类负载时,GPU真正工作的时间只占到36%左右,其他绝大部分时间都在等待数据传输,表现出较高的算力闲置率。虽然对于不同数据和参数量的模型、不同类型的负载、不同规模的算力资源而言,这个数值不尽相同,但它大致能说明数据通信的确是AI集群运作的瓶颈。即便是已经广泛应用的可插拔光模块,其延迟、功耗在万卡级别的算力集群之下也相当可观的。
曦智科技期望在万亿参数规模AI模型计算场景下,基于CPO光电共封装技术“降低至少1倍的闲置率”。CPO的实质是令原本的光模块离主芯片更近了:曦智科技创始人、首席执行官沈亦晨博士在最近的媒体会上说,对于可插拔光模块而言,“光电转换芯片离GPU距离远”,尤其当它位于交换机之中,“和GPU之间至少有1m以上的铜导线距离”。

所以在近封装/板载光学(NPO/OBO)解决方案中,“光电转换芯片直接放在了板卡上,距离从1m缩短到10cm,互联密度提高了2-3倍。如果把DSP芯片也去掉,还能减少与GPU之间的通信延迟。”这是目前曦智科技已经全面商用落地的解决方案。
如果将这种光电转换芯片与数字主芯片靠得更近,将二者放到同一个封装内,就构成了CPO芯片。两片chiplet距离“缩短到1mm”,“进一步增加互连带宽、降低传输延迟。”也就有了交换芯片与硅光引擎封装在一起的NVIDIA Photonics,以及曦智科技在WAIC上展示的、共封装GPU与硅光芯片的“xPU-CPO光电共封装原型”(下图)。这两者恰好对应了交换机侧与GPU侧的CPO实现。

这一CPO成果展示,是通过短距离SerDes连接,实现光电共封装,“将GPU上的信号直接转为光信号传出”。由于在同一封装基板内就集成了计算芯片和硅光引擎,实现了近距离光电互连。曦智科技称xPU与光引擎超短互连,面板IO密度提升3倍以上,信号完整性与系统带宽同步增强;另外“采用短距XSR SerDes,每bit能耗降低不少于30%”;加上“封装内信号路径优化,板上插损降低超10dB”。
曦智科技互连产品线副总裁朱剑解释说,越近的距离可达成的收益是巨大的,不单是物理距离更近带来的价值;例如去除DSP乃至FEC(前向纠错),都能有效降低延迟,最终在系统层面达成更高的算力利用率。
在2D/2.5D CPO之后,“最终光互连的方式,应当是光芯片和电芯片位于同一颗芯片之上,也就是3D共封装,将电芯片和光芯片堆叠在一起,实现更高效的数据传输。”“电芯片整体通过一个面的连接,(将信号)传导到硅光芯片——硅光芯片将信号往外传输。”“3D CPO大概会比现在的互连方式再提高1-2个数量级的互连带宽。”
此前我们撰文提过,包括NVIDIA Photonics在内的部分光电转换芯片自身已经有EIC(电集成电路)和PIC(硅光集成电路)上下两层了——但媒体问答环节,沈亦晨告诉我们这仍然不是3D CPO方案。从示意图来看,曦智科技所说的3D CPO,应当是GPU之类的处理器die,整体与硅光芯片做3D堆叠。沈亦晨说:“这是我们的愿景,相信5年内,它就有机会实现。”
对国内AI基础设施可能更有价值...
以上是常规意义上,CPO技术能够为数据中心带来的价值。但在曦智科技看来,这并不是全部,尤其在中国市场上。
沈亦晨在媒体会上谈到的逻辑是这样的:NVIDIA推出Grace Blackwell NVL72以后,达成了显著更高效的性能和效率提升;国内称这种多卡机柜(即scale-up扩展,NVL72这样一个NVLink域)为“超节点”。
NVL72系统相较9台NVL8(9x 单机8卡),由于互连技术上的提升,“当AI模型越大”,则在单用户响应速度及AI集群整体吞吐两个维度上表现出巨大优势。用黄仁勋的话来说,曲线任意点(表示各类不同并行配置方案下的表现)之下覆盖的面积大小就是AI工厂的营收多少——这一点我们在今年的GTC报道文章里也详细解释过。
“当每个用户TPS(tokens per second)超过200,超节点的吞吐量比非超节点提升了3倍以上。”体现出NVL72及超节点在算力和效率方面的优势。
而国产GPU芯片由于众所周知的原因,很难在性能、能效表现上与Blackwell GPU(如B200)相较。曦智科技给出的估算方法是,B200芯片相较基于Ampere架构的A100,算力提升约5-10倍;考虑国产GPU芯片目前与A100表现相似,则粗略估计,NVL72的算力,约等于500张国产GPU的算力(不考虑通信等因素)。
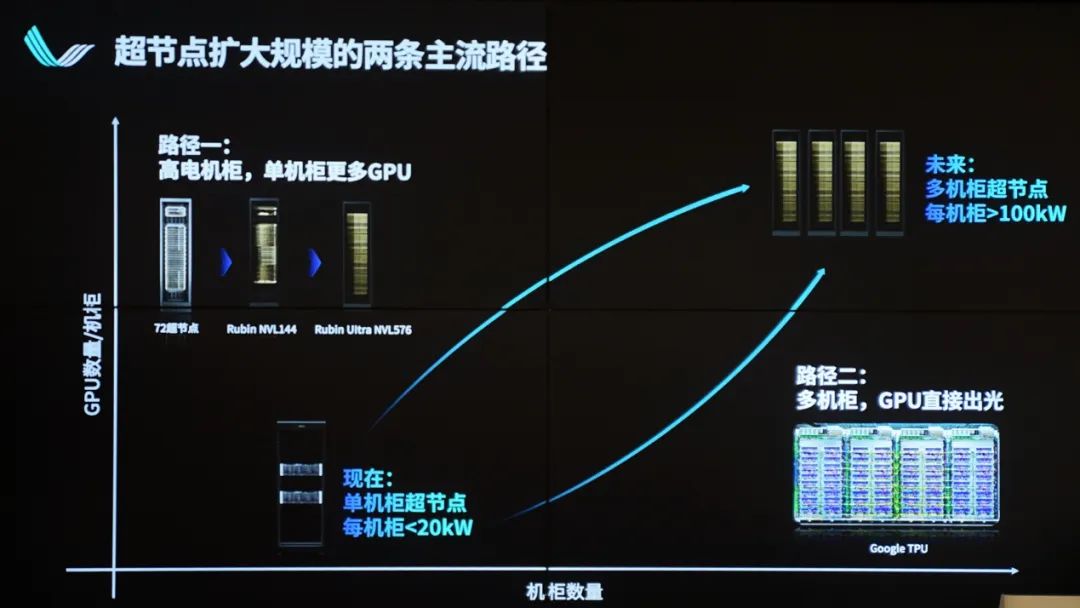
换句话说,如果采用国产GPU来建AI计算集群或基础设施,在技术受限——尤其先进制造工艺被封锁的情况下,为了达到NVL72机柜的相似性能,至少需要堆500张国产显卡。但“考虑功耗、散热、体积,将500颗GPU塞进一个机柜里是不可行的”,尤其“无法放下那么多的铜导线”。
所以唯有选择多机柜的思路,与此同时跨机柜、节点需要具备高带宽互连能力,“跨机柜往往超过了1m距离,所以只能选择光互连——而不能沿用铜导线方案。”沈亦晨说,而且应当采用“GPU直接出光”方案——也就是前文提到的应用于GPU的CPO方案,“这在我们看来是必须的路径”。
这是“现阶段,能够让国产算力迅速具备超节点能力的解决方案”。朱剑表示,“光互连还能让电机柜去组更大的集群。”另一方面,“有关CPO的商用,目前行业内首个落地场景是交换机——博通和英伟达已经有了对应的产品”——如文首所属,“国内的情况也类似。我们和国内头部交换芯片厂商已经在合作,共同提供光电共封装解决方案。”
“第二步就是GPU。”如本次WAIC上展示的“xPU-CPO光电共封装原型系统”即是前期实践,“落地只是时间问题。”朱剑甚至表示,国内已经“在N+0.5技术上做布局”,“我们相比海外竞争对手,在商业落地上更快。”这和NVIDIA在国际GPU市场上占大头,故而技术整体发展步伐与NVIDIA决策强相关有关,而“中国GPU企业都在寻求突破,更有利于光互连技术的市场落地”。

▲ 在CPO的加持下,500颗GPU的超节点“带宽相比8卡提高3个数量级,3D CPO则在此基础上再上一个数量级”,“才能应对未来几年的挑战”...
同时,沈亦晨补充说,“硅光产品并不特别依赖制造工艺。国内头部产线现在生产的器件性能也很出色。”“国内在光电这块的技术、产业链甚至可以说是更领先的。”“至少在电封装、光封装这两块都比较强。”
众所周知,台积电在先进封装技术上具有优势。但曦智科技表示,“我们现在也在推动国内硅光产线去做更好的封装技术,令其具备更好的光电合封能力”。“国内现在至少有3条硅光产线已经具备量产能力,且工艺节点处于领先位置。”所以“CPO技术对于中国的算力引入,是很重要的路线和机会”。
只不过“目前比较大的挑战在于产业链比较长。”朱剑表示,GPU企业本身无法通过简单地与OSAT封测厂合作完成CPO光电共封装,“一定需要有企业能够把控整个链条,进行协同设计,最终交付光电共封装的产品。”这体现的就是曦智科技的价值了。
就曦智科技自身,在“经过漫长的工程化研发、适配、优化的过程”以后,“我们提供的技术已经准备就绪”,支持国内GPU企业做超节点组网。另一方面由于采用“可解耦”方案,更能“满足现阶段的市场需求”,也“更适合国内生态”,尤其表现在“我们的光互连超节点很好地利用了服务器OEM生态,通过光学解耦让生态发挥最大的作用,降低超节点落地成本”。
这一点可能也部分体现在曦智科技的光互连、光交换解决方案依旧可以与传统电连接与交换方案共存。在做AI基础设施建设时,不需要做完全的greenfield投入。
超节点解决方案:基于dOCS分布式光交换
除了数字芯片与硅光引擎的共封装,曦智科技今年展示的另一个亮点是dOCS分布式光交换。沈亦晨说最先进的电交换芯片同样需要采用尖端半导体制造工艺,在国内的发展受到限制;既然“用光互连了,为何不尝试直接用光交换,直接连接所有的光通道呢”?
曦智科技展位上展示的“全球首个分布式光互连光交换GPU超节点解决方案”LightSphere X是由曦智科技、壁仞科技、中兴通讯共同推出的,在今年WAIC主论坛上还得到了2025 SAIL奖(卓越人工智能引领者奖)。
新闻稿中提到,“该方案以曦智科技的全光互连芯片为核心,创新性地提出了分布式光交换技术,解决了大规模算力集群中传统电互连、集中式交换的带宽瓶颈与扩展性受限等挑战,构建起高带宽、低延迟、灵活可扩展的自主可控智算集群新范式”。
“采用硅光技术的光互连光交换芯片和壁仞科技自主原创架构的大算力通用GPU液冷模组与全新载板互连,并搭载中兴通讯高性能AI国产服务器及仪电智算云平台软件,构建起高带宽、低延迟、灵活可扩展的自主可控智算集群新范式,即将于上海仪电智算中心落地。”

基于硅光子技术的分布式光交换dOCS芯片
曦智科技在媒体会上并未就此技术做太多解释,沈亦晨只是提到:“这颗光交换芯片做的事情是,通过中央信号控制,让光信号在波导间进行信道切换。”相关论文已经得到顶会SIGCOMM 2025的接收——感兴趣的读者可做留意(InfiniteHBD: Building Datacenter-Scale High-Bandwidth Domain for LLM with Optical Circuit Switching Transceivers)。
PPT上提到的dOCS的核心特点涵盖“可实现超节点规模和拓扑灵活切换”,“不受协议限制”,“突破核心器件与供应商瓶颈”;而基于dOCS超节点架构的性能优势则有“单位互连成本仅为NVL72的31%”,“GPU冗余率比NVL72和TPUv4低一个数量级”,“与NVIDIA DGX(单机8卡)相比,模型算力利用率最高提升3.37倍”。
这里沈亦晨特别强调了其“灵活组合和冗余容灾”能力,对于GPU失效的情况,“可以在毫秒级时间内,直接切换好的GPU,大大减少冗余带来的成本增加”。但他没有解释这其中的具体逻辑,大概与此处所说“分布式”特性、在每个GPU上集成光交换功能,可灵活切换GPU互连拓扑结构有关。
新闻稿中还提到,dOCS能“按模型算力需求动态调整超节点规模、切换拓扑网络”;并且“分布式设计支持GPU高带宽通讯域弹性扩展”,“光跃LightSphere X将实现2千卡规模部署”;“通过自主研发智算云平台软件灵活配置超节点网络拓扑,支持密集通信和更大TP&EP,高效适应各种大模型需求”——可见软件应当也是关键。

dOCS模组,看起来就像普通的可插拔光模组
朱剑在问答环节解释说,一般OCS“需要个盒子”,“看起来和传统电交换机很像”。传统OCS盒子之所以“没有在数据中心大规模应用,在于它连接大量光纤,一旦出问题,爆炸半径就会很大——当然业界也在持续研发,尝试解决问题,但还需要时间”;同时其“单位成本还没有完全降低到数据中心或云的客户可以无视的程度”。
“dOCS就着眼在这两个问题。首先是架构上创新,交换功能不做在大‘盒子’里,而是放进一个模块中——最终形态看起来就像个光模块——我们利用光模块传统硬件生态,将交换功能放进去”;“第二,因为基于硅光,可靠性更好;且由于基于成熟的硅光生态,成本大幅下降”;“加上系统应用上又能省去电交换,这款产品是面向技术、产品定义、应用场景的联合创新。”

有关上述曦智科技光互连技术的落地,沈亦晨表示“我们的目标是年内落地万卡集群”,“今年6月份已经在上海,和沐曦一起,落地了基于光互连电交换的数千卡集群超节点”,“现在也正在落地数千卡的光互连光交换系统——故而上述产品和技术已经不停留在纸面上了。
最后,给一个比较有趣的展望:虽然并不能完整概述曦智科技的硅光未来视野,不过在我们看来的确大概率会成真:“未来数据中心的芯片比如交换芯片、GPU,都会配数个硅光芯片——这就好像现在的GPU都会配HBM一样——可能将来的GPU左右是HBM存储芯片,上下就是硅光芯片共封装了。”
随着AI算力需求的持续走高,沈亦晨描述的这幅图景应当就在不远的将来了。而曦智科技显然是国内最有希望抓住这一市场机遇的。











