全文约 3200 字,预计阅读时间 10 分钟
在人工智能领域,大语言模型(LLM)的微调技术一直是推动模型性能提升的关键环节。但熟悉的朋友知道,尽管传统的监督微调(Supervised Fine-Tuning, SFT)简单高效,但其泛化能力不足,相比强化微调更像是“鹦鹉学舌”。
近期,由东南大学领衔,联合加州大学洛杉矶分校、加州大学伯克利分校、加州大学默塞德分校、上海交通大学、南洋理工大学和武汉大学等全球顶尖高校的研究团队,提出了一种名为动态微调(Dynamic Fine-Tuning, DFT)的新方法。这项研究通过一行代码的简单修改,显著提升了SFT的性能,展现出超越传统方法的强大泛化能力,并在数学推理任务中取得了令人瞩目的成果。以下,我们将从创新点、实验方法和实验结果三个方面,深入解析这项研究的魅力与价值。

创新点:从理论洞察到简单高效的解决方案
SFT作为大语言模型微调的主流方法,通过在专家演示数据集上进行训练,使模型快速学习特定任务的行为模式。然而,相比强化学习(Reinforcement Learning, RL),SFT的泛化能力较弱,尤其在面对复杂或分布外的数据时,容易出现过拟合现象。
这项研究的核心创新在于,通过数学分析揭示了SFT泛化能力受限的根本原因,并提出了一种简单而高效的改进方案——动态微调(DFT)。
研究团队从强化学习的角度重新审视SFT,证明了SFT的梯度更新可以看作是一种特殊的策略梯度方法,但其隐含的奖励结构存在问题:SFT的梯度隐式定义了一个稀疏且与模型对专家动作(即训练集中的目标输出,如一个数学问题逐步推理的思维链序列)分配概率成反比的奖励函数。这种奖励结构在模型对专家动作分配低概率时,会导致梯度方差的无界增长,即这个标准回答的梯度贡献会被无限放大,可能会导致模型过度关注这些低概率样本,进而造成优化过程中的不稳定性。这种不稳定的优化景观是SFT泛化能力受限的根源。
为了解决这一问题,研究团队提出了DFT,通过对每个token的损失函数进行动态缩放,抵消SFT中不合理的逆概率加权。具体而言,DFT在标准SFT损失的基础上,乘以token的概率并施加停止梯度操作(stop-gradient),从而将奖励函数修正为均匀分布的常数值。
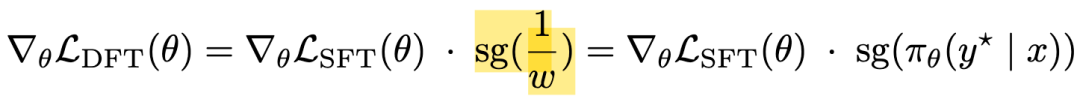
其中 sg(·) 表示停止梯度算子,确保梯度不会流经奖励缩放项 w。
这种简单的一行代码修改,不仅稳定了梯度更新,还显著提升了模型的泛化能力。值得一提的是,这种方法与传统的焦点损失(Focal Loss)形成了鲜明对比:焦点损失通过降低高概率样本的权重来关注难样本,而DFT则通过降低低概率样本的权重来增强泛化能力,反映了在大语言模型时代从欠拟合到过拟合问题的转变。
这项研究的理论贡献在于,首次明确建立了SFT与强化学习策略梯度之间的数学等价性,并精确指出了SFT泛化能力受限的根源——逆概率加权项。基于这一洞察,DFT通过动态重新加权,消除了不合理的奖励结构,构建了一个更稳定、更有效的优化过程。这种从理论到实践的突破,展现了研究团队在数学分析与工程实践之间的完美平衡。
实验方法:严谨设计,覆盖多模型与多任务
为了验证DFT的有效性,研究团队在数学推理任务上进行了广泛的实验,采用了NuminaMath CoT数据集作为主要训练数据。该数据集包含约86万个数学问题及其解决方案,涵盖了中国高中数学练习题以及美国和国际数学奥林匹克竞赛题目。为了控制计算资源,研究团队从中随机抽取了10万个样本进行训练,并确保所有方法的性能在数据集耗尽前达到收敛。
实验覆盖了多种先进的开源大语言模型,包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、LLaMA-3.2-3B、LLaMA-3.1-8B和DeepSeekMath-7B,模型规模从1.5亿到80亿参数不等。训练基于verl框架,采用AdamW优化器,学习率在不同模型间有所调整(例如,LLaMA-3.1-8B使用2e-5,其他模型使用5e-5),并设置了256的批次大小和2048的最大输入长度。学习率采用余弦衰减调度,预热比例为0.1。
在评估阶段,研究团队选择了五个具有代表性的数学推理基准测试:Math500、Minerva Math、Olympiad Bench、AIME 2024和AMC 2023。这些基准测试覆盖了从基础数学到奥林匹克级别的复杂推理任务,能够全面评估模型的数学推理能力。每个模型采用链式推理(Chain-of-Thought, CoT)提示方式,评估结果为16次解码的平均准确率,温度参数设为1.0,最大生成长度为4096个token。
此外,研究团队还探索了DFT在离线强化学习场景下的应用,采用拒绝采样微调(RFT)框架,生成约14万个训练样本,并构建了10万个正负偏好对,用于与直接偏好优化(DPO)等方法进行对比。实验还包括在线强化学习方法如PPO和GRPO,以全面评估DFT的竞争力。
实验结果:显著提升,展现强大泛化能力
实验结果表明,DFT在所有测试的模型和基准测试中均显著优于标准SFT,尤其在复杂任务上展现了更强的泛化能力。以Qwen2.5-Math-1.5B模型为例,DFT在五个数学推理基准测试上的平均准确率提升了15.66个百分点,相比之下,标准SFT仅提升了2.09个百分点,DFT的提升幅度是SFT的5.9倍。在Olympiad Bench上,SFT使Qwen2.5-Math-1.5B的性能从15.88%下降到12.63%,而DFT则将其提升至27.08%,比基线模型高出11.2个百分点。在AIME 2024和AMC 2023等高难度基准测试中,SFT甚至导致性能下降,而DFT始终保持显著的正向提升。
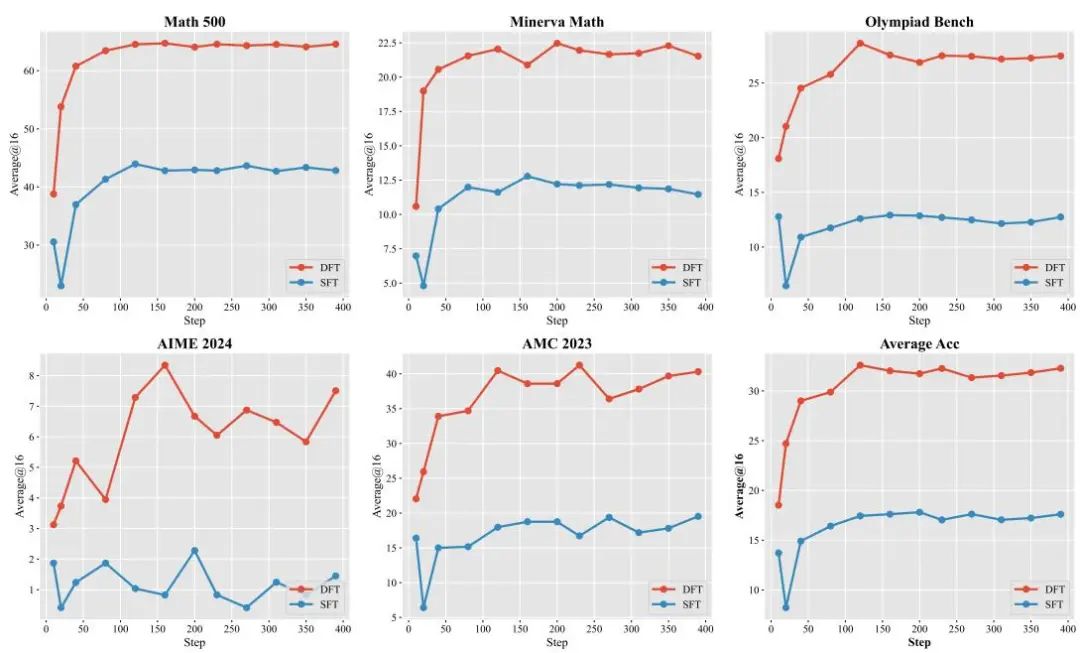
图1:Qwen2.5-Math-1.5B模型在数学推理基准测试上的准确率变化曲线,展示了DFT相较于SFT更快的收敛速度和更高的性能。
从学习效率上看,DFT展现了更快的收敛速度和更高的样本效率。在Qwen2.5-Math-1.5B的训练过程中,DFT在前120个训练步骤内即可达到峰值性能,而SFT需要更多步骤。此外,DFT在前10-20个步骤的性能已超越SFT的最终准确率,显示出更高效的梯度更新机制。
在离线强化学习场景中,DFT同样表现出色,平均准确率达到35.43%,超越了最佳离线方法RFT(23.97%)11.46个百分点,甚至比在线强化学习方法GRPO(32.00%)高出3.43个百分点。在AMC 2023基准测试上,DFT的准确率为48.44%,比GRPO高7.19个百分点,比RFT高17.66个百分点。这些结果表明,DFT在利用偏好数据时,能够更高效地转化为泛化能力的提升,是一种简单而强大的替代传统强化学习的方法。
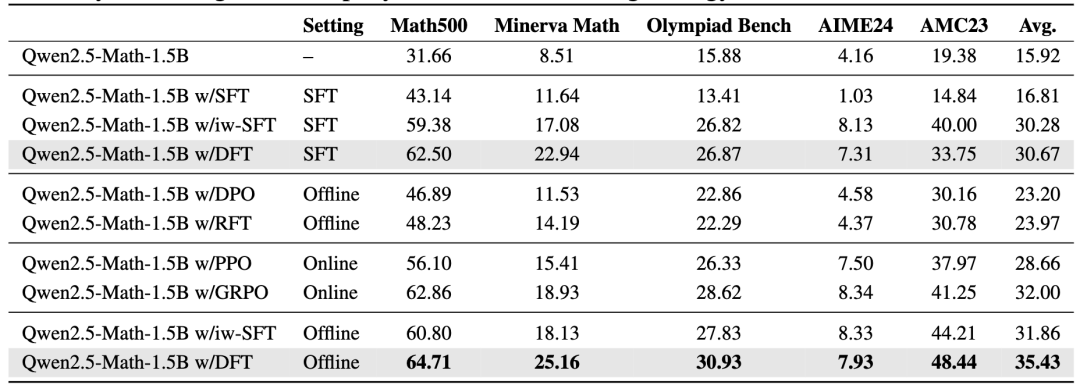 图2:在离线强化学习设置下,使用来自拒绝采样的奖励信号,在五个数学推理基准上的评估结果。DFT 取得了最佳的整体性能,超过了离线(RFT、DPO)和在线(PPO、GRPO)基线,证明了它作为一种简单而有效的微调策略的效率和优势。
图2:在离线强化学习设置下,使用来自拒绝采样的奖励信号,在五个数学推理基准上的评估结果。DFT 取得了最佳的整体性能,超过了离线(RFT、DPO)和在线(PPO、GRPO)基线,证明了它作为一种简单而有效的微调策略的效率和优势。
为了深入理解DFT的效果,研究团队分析了训练后模型的token概率分布。结果显示,SFT倾向于均匀提高所有token的概率,导致模型过度拟合训练数据。而DFT则呈现出双峰分布特征:部分token的概率显著提高,另一些token(尤其是连接词和标点等语法功能词)的概率被主动抑制。这种策略类似于人类教学中注重核心概念而非语法细节的做法,有助于模型在复杂任务中实现更 robust 的学习。

图3:训练前后模型在训练集上的token概率分布,DFT展现出独特的双峰分布特性,兼顾高概率和低概率token的优化。
在消融实验中,研究团队进一步验证了DFT对超参数的鲁棒性。通过调整学习率和批次大小,DFT在所有配置下均优于SFT,证明其性能优势并非源于超参数优化,而是方法本身的有效性。
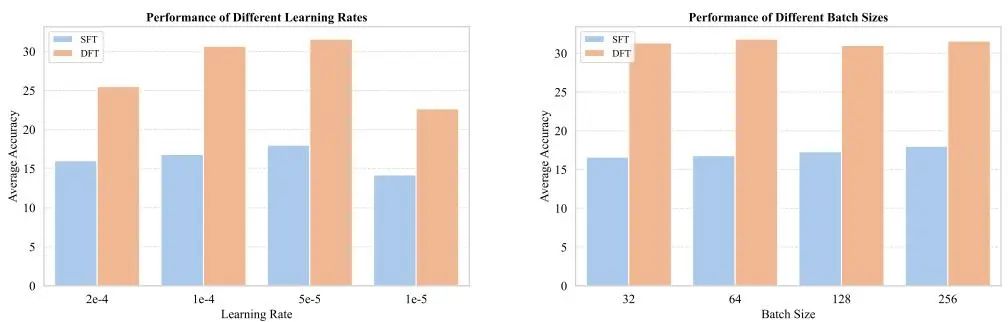
图4:DFT与SFT在不同学习率和批次大小下的性能比较,显示DFT对超参数变化的鲁棒性。
意义与展望
这项研究不仅在理论上深化了我们对SFT和强化学习关系的理解,还通过DFT提供了一种简单而高效的微调方法,显著提升了大语言模型在数学推理任务中的性能。DFT的成功表明,通过精准的数学分析和简洁的工程实现,可以在不增加复杂度的前提下,显著改善模型的泛化能力。这种方法尤其适合那些缺乏负样本或奖励信号的场景,为大语言模型的实际应用提供了更经济的选择。
尽管当前实验主要集中在数学推理任务和中小规模模型,研究团队计划未来将DFT扩展到代码生成、常识问答等更多领域,并验证其在更大规模模型(130 亿参数以上)和多模态任务中的有效性。这些扩展将进一步验证DFT的普适性,为大语言模型的微调技术开辟新的可能性。
结论
由东南大学领衔,联合全球顶尖高校的研究团队通过动态微调(DFT)方法,为大语言模型的监督微调带来了革命性的突破。这项研究从理论上揭示了SFT泛化能力受限的原因,并通过一行代码的修改,显著提升了模型在数学推理任务中的性能和泛化能力。实验结果显示,DFT不仅在标准SFT场景下大幅优于传统方法,还在离线强化学习场景中超越了复杂的在线和离线强化学习算法。这种简单而高效的方法,为大语言模型的微调技术提供了新的范式,展现了理论与实践结合的巨大潜力。
论文连接:https://huggingface.co/papers/2508.05629
开源仓库:https://github.com/yongliang-wu/DFT
-- 完 --
机智流推荐阅读:
1. 💥重磅,OpenAI开源!发布自GPT-2以来首批开源权重模型GPT-OSS系列,媲美o4-mini,还适配消费级硬件和边缘设备
2. Claude Opus 4.1 发布:更强大的编码与推理能力
3. 聊聊大模型推理系统之BrownoutServe,突破MoE大模型服务瓶颈:SLO违规率下降90.28%背后的三大创新
4. 淘宝上线大模型推荐系统!淘宝联合人民大学推出RecGPT,有效改善推荐效果、缓解信息茧房
5. 耗时一周:我给李沐老师的新模型Higgs audio学会了越南语
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群