如您有工作需要分享,欢迎联系:aigc_to_future
作者:skywork AI
解读:AI生成未来

Git:https://github.com/SkyworkAI/UniPic
huggingface:https://huggingface.co/Skywork/Skywork-UniPic-1.5B

亮点直击
一种原生统一的自回归架构Skywork UniPic,能够在无需多个独立模型或连接器的前提下,原生支持联合的视觉理解、图像生成与编辑任务,具备良好的现实可用性; 通过解耦的视觉编码策略,解决了语义理解与图像保真之间的矛盾,针对不同任务需求优化表示路径,同时保持任务间的协同; 通过严谨的数据构建、针对性奖励建模与渐进式训练,实现在前所未有的效率下达成最先进性能,证明高质量的多模态整合并不一定依赖于巨大的计算资源。 通过在四个广泛认可的图像相关基准上确立了 Skywork UniPic 作为可部署多模态系统的实用基础。
总结速览
解决的问题
多模态任务碎片化,协同困难:传统方法通常将图像理解、文本生成图像、图像编辑分别交由不同模型处理,导致流程碎片、协同效率低。 模型架构复杂、资源消耗高:现有多模态系统依赖任务特定模块或连接器,参数量大、训练和部署成本高,不适用于资源受限设备。 语义理解与图像保真度难以兼顾:基于 VQGAN/VAE 的方法偏向像素重建,牺牲语义表达能力;拼接式系统缺乏深度整合,影响生成质量与编辑精度。 缺乏高效、可部署的统一架构:当前尚缺一个参数高效、性能卓越、可在消费级硬件运行的多模态统一模型。
提出的方案
构建统一的自回归架构 Skywork UniPic:在单一模型中统一支持图像理解、生成与编辑,无需连接器或适配器,实现端到端训练。 解耦视觉编码策略:采用 Masked Autoregressive Encoder 处理图像生成,SigLIP2 编码器处理图像理解,共享一个自回归解码器,提升任务协同。 渐进式训练机制:从低分辨率(256×256)逐步扩展到高分辨率(1024×1024),并动态解冻参数,提升训练稳定性与模型容量利用率。 精心策划的大规模数据与奖励机制:构建亿级高质量多模态数据集,并引入任务特定的奖励模型,优化生成与编辑的效果。
应用的技术
自回归建模(Autoregressive Modeling):统一处理理解、生成与编辑任务,保持架构一致性。 Masked Autoregressive Encoder + SigLIP2 Encoder:分别处理生成与理解任务,兼顾像素保真与语义建模。 共享自回归解码器(Shared Decoder):多任务共享输出模块,提升协同效率与参数利用率。 渐进式训练(Progressive Curriculum Training):分辨率感知训练策略,动态调整模型训练难度。 任务特定奖励模型(Task-Specific Reward Models):用于图像生成与编辑的优化目标设计,提升人类偏好对齐度。 高效数据构建与训练调度:构建语义多样、任务均衡的数据集,提升泛化能力。
达到的效果
性能领先:
GenEval 得分 0.86,超越大多数统一模型; DPG-Bench 得分 85.5,创复杂生成任务新纪录; 图像编辑任务中,在 GEditBench-EN 得分 5.83,ImgEdit-Bench 得分 3.49。
模型参数仅 15 亿,远低于主流模型(如 BAGEL 的 140 亿); 可在 <15GB 显存(如 RTX 4090) 上生成 1024×1024 高分辨率图像。
单一模型即可完成多任务,无需外部模块拼接; 提供开源模型权重、训练代码与文档,便于在资源受限环境中落地使用。
实现语义理解与图像保真间的平衡; 支持自然语言驱动的图像生成与编辑,适用于多轮交互与创作场景。
方法
Skywork UniPic,这是一种统一的自回归模型,能够在单一框架中原生整合图像理解、文本生成图像以及图像编辑任务。多模态人工智能的快速发展揭示了碎片化方法的局限性,这些方法通常通过松散耦合的连接器让多个专用模型分别处理不同任务。这类架构存在跨模态协同不足以及部署复杂度高的问题。
受近期统一多模态建模工作的启发,尤其是 Harmon 的研究启示——其展示了在自回归框架中共享视觉表示的潜力——本文发展出一种更精细的任务统一方法。尽管 Harmon 在使用单一 MAR 编码器同时处理理解与生成任务方面取得了有希望的结果,本文识别并解决了其中一个关键限制:共享编码器可能因优化目标冲突而导致任务干扰。
重要洞察是:不同的视觉任务对表示的粒度要求不同——理解任务需要语义丰富性,而生成任务则需要像素级保真度——但二者都可以从通过共享语言主干实现的统一处理方式中受益。
基于这一观察,在统一的自回归框架中提出了一种解耦的编码策略。没有强迫单一编码器同时优化多个冲突目标,而是采用任务特定的编码器,并将它们的输出输入到共享的语言模型中,从而实现专用表示学习与跨任务知识迁移的结合。这一设计在保留统一训练优势的同时,也允许每个编码器在其指定任务上发挥最大效能。
模型架构
模型由四个核心组件组成:
一个用于生成任务的 掩码自回归(Masked Autoregressive, MAR)编码器-解码器对; 一个用于理解任务的 SigLIP2 编码器; 一个共享的 Qwen2.5-1.5B-Instruct 语言模型主干; 一组专用的 MLP 投影层,用于将视觉编码器的输出映射到语言模型的嵌入空间,如下图 2 所示。

该架构不同于原始 Harmon 框架所采用的共享编码器方法——发现该方法容易引发任务干扰。相反,本文采用了解耦的编码策略,使每个视觉编码器都针对其特定任务需求进行优化,同时通过共享语言主干保持统一处理流程。这种设计保留了统一训练的优势,同时支持任务特定的表示学习。
在图像生成方面,本使用 MAR-Huge* 作为编码器和解码器,其包含约 个参数,编码器和解码器各有 层,隐藏维度为 ,注意力头数为 。图像首先通过一个冻结的 VAE 编码为潜在表示,该 VAE 来自原始 Harmon 框架,用于保留低层视觉特征并在多模态训练过程中确保稳定收敛。将生成分辨率从 扩展到 ,以实现更高保真度的合成,并捕捉更细粒度的视觉细节,从而拓展 MAR 在高分辨率图像合成任务中的适用性。
在图像理解方面,采用 SigLIP2-so400m-patch16-512† 作为视觉编码器,利用其在多个视觉-语言基准测试中展现出的优越跨模态对齐能力和高效的表示学习能力。该编码器处理 分辨率的图像,并提取针对理解任务优化的语义丰富特征。为了进一步增强图像理解能力,本文在 SigLIP2-so400m-patch16-512 的检查点基础上继续训练,为跨模态表示学习提供了坚实基础。
两个独立的两层 MLP 将视觉编码器的输出投影到与 语言模型嵌入空间对齐。这种分离设计允许为每个任务独立优化投影映射,同时保持架构简洁,并促进与共享大语言模型的有效整合。
训练方法
本文的训练采用多任务目标函数,结合了生成与理解的损失:
图像生成(扩散损失):

图像理解(交叉熵损失):

这些在联合训练期间被整合进多任务目标中: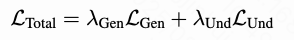
其中 系数在训练阶段中动态变化,以平衡任务学习动态。本文实现了一个四阶段的渐进式训练课程,涵盖亿级规模的预训练和百万级规模的监督微调。阶段1:MAR 预训练(PT)开始,通过专门训练 MAR 编码器-解码器模块建立基础的生成能力,特别强调人脸重建和复杂物体合成。
阶段 2:MAR-LLM 对齐,在此阶段中,MAR 的输出被投射到 LLM 的嵌入空间,同时保持 LLM 参数冻结,使用余弦退火调度加速投射层的收敛。
阶段 3:联合优化(CT)解冻 LLM,在多任务目标 下进行跨模态调优,损失权重取 和 ,在指令遵循指标上带来 12–15% 的提升。流程最后是阶段 4:监督微调(SFT),使用质量阈值高于 0.9 的奖励过滤样本对统一模型进行精细化调整,纳入完整的 目标及编辑损失组件,以优化最终任务性能。
分辨率扩展是渐进式的,从早期阶段的 逐步扩展到最终训练的 ,其中生成任务达到 ,理解任务稳定在 。这种分阶段的方法使模型能在较低分辨率下学习基本能力,然后适应高分辨率合成需求。
超参数详见下表 1。训练堆栈采用 bf16 混合精度,并使用 DeepSpeed ZeRO-3 进行优化。本文在预训练(PT)阶段使用全局 batch size 为 4096,在监督微调(SFT)阶段为 512。模型架构由一个拥有 8 亿参数的 MAR 模块与一个拥有 15 亿参数的语言模型主干组成。

数据质量保障
为确保训练数据质量,基于 Qwen-VL 架构开发了两个专用奖励模型:Skywork-ImgReward 用于视觉质量评估,Skywork-EditReward 用于图像编辑准确性评估。
Skywork-ImgReward 使用群体相对策略优化(Group Relative Policy Optimization, GRPO)进行训练,利用定制设计的配对排序奖励函数,将学习得到的成对排序分数 与格式评分 结合:
 训练数据整合了多个公开数据集,包括 Pick-a-Pic、ImageRewardDB 和 HPSv2,并通过精选样本增强,重点关注人体图像质量。Skywork-EditReward 通过对高质量编辑数据集(包括 HumanEdit、UltraEdit 和 SuperEdit-40K)进行监督微调训练,从而实现对图像编辑中指令对齐与语义正确性的细粒度评估。
训练数据整合了多个公开数据集,包括 Pick-a-Pic、ImageRewardDB 和 HPSv2,并通过精选样本增强,重点关注人体图像质量。Skywork-EditReward 通过对高质量编辑数据集(包括 HumanEdit、UltraEdit 和 SuperEdit-40K)进行监督微调训练,从而实现对图像编辑中指令对齐与语义正确性的细粒度评估。
本文的数据筛选流程采用严格的过滤机制,首先剔除奖励分数低于 0.9 的样本,然后使用 VQAScore 作为额外的质量启发式标准进行多重检查机制。分析显示主要存在四类失败模式:指令对齐偏差、视觉伪影、语义不一致以及编辑不合规。该精选数据集确保了数据的高度同质性,并增强了模型在包括人体、动物和文本渲染等多样视觉类别上的泛化能力。
主要结果
评估设置
为全面评估 Skywork UniPic 的统一能力,本文采用多维度评估策略,涵盖图像理解、文本生成图像和图像编辑任务,并基于多个权威基准进行测试。
基准测试。 对于文本生成图像任务,在 GenEval 上进行评估,该基准衡量组合理解与目标对齐能力;同时在 DPG-Bench 上评估其对复杂指令和长提示的遵循能力。这些基准测试覆盖了细粒度的组合推理能力与通用生成质量。
图像编辑能力通过 GEdit-Bench-EN 和 ImgEdit-Bench 两个主要评估套件进行评估。这些基准源于真实用户请求,涵盖多样化的编辑场景,真实反映了实际编辑需求,全面覆盖了基于指令的图像修改任务,包括物体添加/删除、风格迁移和属性修改。
评估协议。 所有图像生成任务均采用 64 步采样,输出分辨率为 ,无分类器引导比例设置为 3,以实现质量与多样性的最优平衡。性能评估使用官方基准脚本和自动化评估指标,所有得分均来自单次评估运行,未进行重排序或多次采样,以确保结果可复现。
对比基线。 本文与多个类别的最先进模型进行对比。统一模型包括 OmniGen/OmniGen2、Janus/Janus-Pro、BAGEL、UniWorld-V1、Show-o、BLIP3-o、MetaQuery-XL 和 Ovis-U1。
专用生成模型包括扩散方法(如 FLUX.1-dev、SD3-medium、SDXL、DALL-E 3、LUMINA-Next、Hunyuan-DiT、PixArt-P、NOVA)和自回归方法(如 TokenFlow-XL、Emu3-Gen)。在编辑方面,本文对比了 Step1X-Edit、ICEdit、AnyEdit、UltraEdit、Instruct-Pix2Pix 和 MagicBrush。专有模型包括 GPT-4o 和 Gemini-2.0-flash。
尽管仅使用了 15 亿激活参数,Skywork UniPic 在性能上仍与远大于其规模的统一模型(通常为 70 亿以上参数)相当或更优,凸显了本文架构设计与训练方法的有效性。各任务对应的性能指标汇总见下图 3。

文本生成图像
本文在两个标准基准 GenEval 和 DPG-Bench 上评估 Skywork UniPic 的文本生成图像(T2I)能力,分别衡量其组合理解能力和长提示遵循能力。本模型展现出极具竞争力的性能,尤其是在资源效率方面表现突出。
GenEval 评估。 如下表 2 所示,Skywork UniPic 在 GenEval 上获得了整体得分 ,在多样化生成任务中展现出强大的组合理解能力。模型在单物体生成任务中表现尤为出色(),在双物体组合任务中也取得了优异成绩(),同时在颜色理解()和空间定位()方面保持了稳定表现。计数任务()与颜色归属()相对更具挑战性,这与文献中统一模型的普遍观察一致。

DPG-Bench 评估。 在 DPG-Bench 上,Skywork UniPic 获得了整体得分 ,在长提示遵循与复杂场景理解方面展现出竞争力。下表 3 展示了各评估类别的详细对比结果,本文的模型在整体连贯性、实体识别、属性理解和关系推理等方面均保持稳定性能。

考虑到本文的模型仅包含 亿参数,而对比模型如 BAGEL( 亿)和 UniWorld-V1( 亿)参数量大幅高于本文,这些结果尤为显著,凸显了解耦编码策略与渐进式训练方法的有效性。
图像编辑
图像编辑是 Skywork UniPic 统一架构的核心优势之一。在 GEdit-Bench 和 ImgEdit-Bench 两个基准上评估模型的编辑能力,这些基准涵盖了基于指令的多样图像修改场景。
GEdit-Bench 评估。 如下表 4 所示,Skywork UniPic 在 GEdit-Bench 上表现强劲,整体得分为 ,跻身统一模型前列。模型在语义一致性(Semantic Consistency, SC)方面表现尤为突出,得分为 ,表明其具备强大的指令遵循能力。虽然感知质量(Perceptual Quality, PQ)得分为 ,仍有提升空间,但模型在保持未修改区域的同时实现精确局部编辑,验证了本文统一架构的有效性。

ImgEdit-Bench 评估。 为进一步验证模型在多样场景下的编辑能力,本文在涵盖九大编辑类别的综合基准 ImgEdit-Bench 上对 Skywork UniPic 进行评估。如下表 5 所示,Skywork UniPic 取得了整体得分 ,在综合图像编辑评估中跻身领先统一模型之列。

结果揭示了模型在不同编辑类别中的显著表现。Skywork UniPic 在动作编辑(Action editing)和风格修改(Style modification)方面表现尤为强劲,得分分别为 和 ,得益于本文强调多阶段能力发展的渐进式训练方法以及覆盖多样编辑场景的数据筛选流程。模型在背景编辑(Background editing, )和替换操作(Replace operations, )中也表现稳定,显示出对空间关系和物体替换的扎实理解能力。
与其他统一模型相比,Skywork UniPic 超越了 OmniGen(),并接近领先的专用编辑模型,如 ICEdit()和 Step1X-Edit(),同时保持了统一架构的优势,即在单一框架中处理多种模态。BAGEL()和 UniWorld-V1()在某些类别上的优越表现展示了更大参数规模和大量训练数据的优势,然而本文的模型在参数显著更少的情况下取得了可比的结果,凸显了本文架构设计与训练策略的高效性。
定性结果
文本生成图像质量。 下图 4 展示了 Skywork UniPic 与开源及闭源模型在文本生成图像任务中的定性比较。本文的模型在从简单物体生成到复杂场景构图的多种场景中,展现出具有竞争力的视觉质量和对文本提示的强遵循能力。结果显示,尽管模型体积紧凑,Skywork UniPic 所生成图像在保真度和语义准确性方面与体量更大的专用模型相当。

图像编辑能力。 下图 5 展示了 Skywork UniPic 与当前最先进编辑模型在图像编辑任务中的对比。模型在多种编辑场景中展现出对指令的精确遵循,包括物体添加/删除、风格迁移、属性修改和复杂组合变换等。值得注意的是,模型在准确执行所请求修改的同时,能保持未编辑区域的一致性,凸显了本文统一架构方法的优势。

局限性与讨论
局限性。 尽管 Skywork UniPic 在生成与编辑任务中表现强劲,仍存在一些局限性。如下图 6 所示,模型在处理复杂或歧义性文本提示时,偶尔会在文本生成图像任务中表现出较差的指令遵循能力。在图像编辑场景中,本文观察到模型在某些情况下未能响应编辑指令,导致修改不完整或缺失。这些局限性表明,在指令对齐与编辑稳健性方面仍需进一步优化,尤其是在具有挑战性或组合性的场景下。

能力涌现。 与 BAGEL 中的观察类似,UniPic 展现出明显的阶段性能力涌现。值得注意的是,文本生成图像(T2I)能力在第 2 阶段出现,并逐步得到优化,而更复杂的图像编辑能力则显著晚于前者,仅在第 3 阶段和第 4 阶段才逐渐显现。这种分阶段的能力表现反映了图像编辑任务的固有复杂性,其相比直接生成任务更依赖于视觉-语义对齐、条件推理与结构保持等复杂机制。在本工作中,将“能力涌现”定义为:某项能力在早期训练阶段缺失,而在后期阶段显现。这种定性转变,通常被称为“相变”,与本文观察到的现象一致:UniPic 的损失曲线并未明确反映新能力的出现,进一步支持了训练损失不足以作为真实模型能力评估指标的观点。
为研究这一现象,本文评估了各阶段的模型检查点,通过跟踪标准 VLM 基准上的平均得分(作为多模态理解的代理)、GenEval 得分(用于生成能力)以及 GEdit-Bench 表现(用于编辑能力)进行分析。本文的实验结果始终表明,编辑能力的涌现晚于生成能力,即使在将图像分辨率从 扩展到 的情况下,这一模式依然成立。有趣的是,每次分辨率的提升都会引发性能的暂时下降,随后迅速恢复,并超过先前的能力平台,这表明更高的分辨率能够解锁更高的性能上限。此外,本文没有发现明确证据表明,仅仅扩大以理解为中心的数据规模(例如图文匹配)能够直接增强这些生成或编辑能力。这一观察结果凸显了针对生成任务的专门训练策略在掌握复杂、指令驱动任务中的必要性。
结论与未来工作
Skywork UniPic,一个统一的自回归模型,在图像理解、文本生成图像和图像编辑任务中,在单一的 15 亿参数架构内实现了具有竞争力的性能。通过采用解耦的视觉编码策略,在生成任务中使用 MAR,在理解任务中使用 SigLIP2,本模型解决了以往统一方法中像素级保真度与语义理解之间的根本矛盾。
该模型在多个任务中展现出强劲的实证结果:在组合生成任务 GenEval 上得分 ,在复杂指令遵循任务 DPG-Bench 上得分 ,在图像编辑任务 GEdit-Bench 上得分 ,同时保持了在消费级硬件上的高效部署能力。本文全面的数据构建流程解决了图像编辑任务中关键的数据稀缺问题,专门设计的奖励建模框架为训练数据的质量保障提供了有效支持。
主要技术贡献包括:解耦的编码策略,在保持生成质量的同时保留理解能力;系统化的数据构建方法,用于创建高质量训练语料;以及渐进式训练课程,使模型在多种分辨率下高效发展能力。该工作表明,统一的多模态模型能够同时实现强性能与实际效率,挑战了关于构建强大多模态系统必须大规模扩展参数量的传统假设。
未来的工作将着眼于当前的局限性,包括在高度复杂组合指令上的性能、在挑战性场景中的细粒度编辑精度,以及进一步优化多语言能力。
参考文献
[1] Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











