G-0模型现场演示:星海图R1 Lite 执行自然语言指令
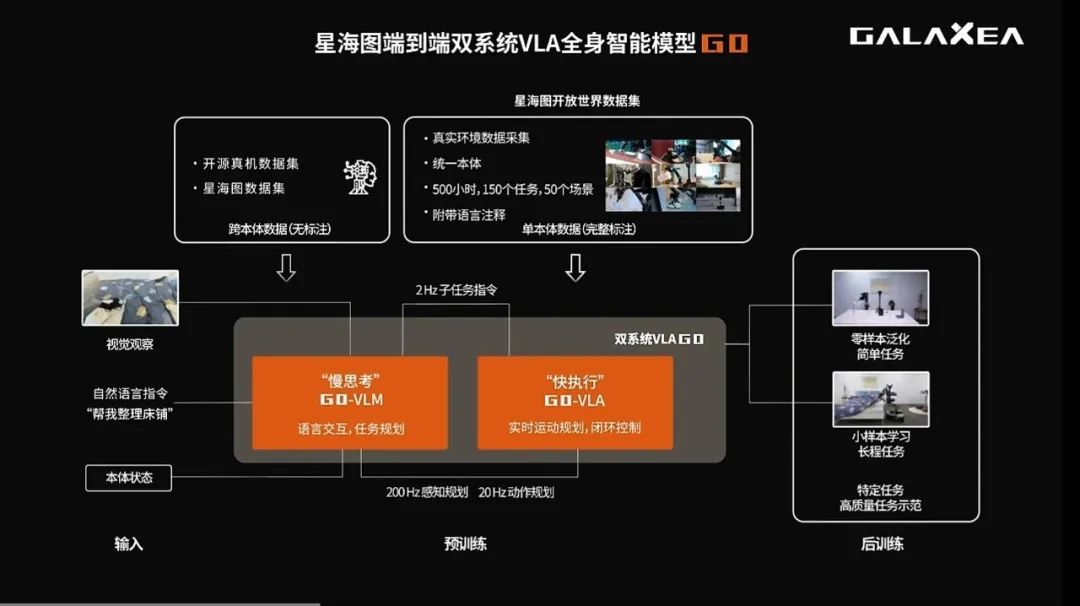
图中不难看出,G0是端到端双系统全身智能VLA模型:
提出了快慢双系统架构,结合System-2(规划,G0-VLM)+ System-1(执行,G0-VLA),实现从视觉和语言指令到23自由度全身控制的长程任务执行。
官方数据显示,星海图G0模型评测结果在多个基准任务上全面优于 π0 模型。
接下来,Galaxea Open-World Dataset及星海图双系统VLA模型也即将全面开源。
这些关于技术、行业、具身智能的强烈“好奇心”,或许正是下一个关键突破口。

G-0模型是如何训练的?
许华哲(清华大学助理教授、星海图联合创始人):G-0模型采用了三阶段的训练。
第一阶段:是用跨本体的所有的互联网上的机器人数据;第二阶段:用了我们本体采集的1,000多小时真机数据;第三阶段:是我们的后训练,会训练到这个特定的任务上。
我们在这次WRC展会,也做了一个相关展示。现场做整理床铺、拉被角这样的一个任务。
我们整体测下来,星海图G0模型评测结果在多个基准任务上全面优于 π0 模型。
8月11日我们也会发布我们的G0模型,和 π 进行一个对比(项目地址见文末)。

团队自己采集的这一批数据
场景上是相对偏家居,还是泛场景?
许华哲(清华大学助理教授、星海图联合创始人):是采集的泛场景数据,而且我们会将其全面开源。
我们场景上面是一个比较泛的场景,包括真的走到了一些酒店、超市里面,就是各种各样真实的场景。跟他们的店员/店长说好,进去帮他们理货、扔垃圾等。
我们这个数据集有1,000+,接近2,000小时。
我们也会进行开源,包括G-0模型的权重以及推理,都会开源给整个社区。


具身智能数据的争议:仿真还是真机?
许华哲(清华大学助理教授、星海图联合创始人):真机的数采数据,可能质量会更高,但仿真数据也同样宝贵。
我们认为还是真机的数采数据,可能质量会比较高,因为它在采集的过程中会有各种各样不同的物理上面的变化。所以,这个真机数据完全是符合物理规律的,因为它本身就是在这个物理世界采集而来的。
仿真的话,在一部分的刚体任务上效果会比较好。但是,在柔性物、在比较复杂的物理情况下,可能效果就没有那么好。更不要说,有的时候视觉上还有一些微小的差距。
那么,我觉得仿真数据,可以大规模地用在预训练;真机数据应该是预训练和后训练,都应该去完全使用。
所以,我们一直都是以真机数据为主,仿真数据为辅,这样的一个路线。
但我认为这两种数据,都是非常重要的非常宝贵的。

真机采集的数据,跨本体使用会存在问题吗?
许华哲(清华大学助理教授、星海图联合创始人):跨本体使用的话,肯定会有一些。
跨本体使用的话,肯定会有一些,就是难或易。就比如说,我们的数据都是在我们这个本体上采,那用我们的这个本体去做训练,肯定是更加容易的。
那么换一个本体,跟机器人的这个构型的差别有关。构型差别小的,也会相对比较简单;但如果构型差别比较大的话,那可能就会需要多一点本体数据。

不同细分赛道对机器人的本体
是否会有不同要求?
许华哲(清华大学助理教授、星海图联合创始人):是的,这会让机器人有自己独特的定义。
会有不同要求,主要还是精度、配重,还有自由度。有些场景可能就固定的机械臂就可以了;有些场景,有一个全身的运动才能做;然后还有一些场景可能比较轻、有的场景抓的东西比较重……
我觉得这些场景会对机器人有自己的独特的这个定义。
但我们定义的,通用人形的形态场景都是可以做的。
只不过在,比如配重和精度上面,可以进行一个微调。就是在于特别高配重场景,我们可以对电机进行一个升级和更换,来完成这个更困难的场景。

星海图团队,目前在招哪些岗位?
许华哲(清华大学助理教授、星海图联合创始人):有的,我们很重视人才招募,这个很关键。
我们一直持续在招算法工程师,尤其是VLA、扩散模型方面的AI算法工程师,包括强化学习的这种后训练的工程师,我们也是持续在招。


招聘时更关注候选人的哪些特征?
许华哲(清华大学助理教授、星海图联合创始人):我觉得候选人,需要有好奇心、一定的真机经验以及AI功底。
第一,是有好奇心,我觉得任何时候对技术充满好奇心都是好的。
第二,就是有真机经验。很多时候在实验室走出来,如果有一些真正操作机器人经验会知道机器人会遇到哪些问题。也能忍受在做机器人当中,跟物理世界打交道的这种慢节奏,今天这儿坏了一点,明天那可能这个床塌了,都有可能的。
第三,我觉得是AI的这个功底要过硬。不能是,我是一个调包侠。
我希望是,大家可以真正理解底层的算法。诸如,Transformer到底是怎么运行的?扩散模型的原理是怎样的?
编辑| 具身君
项目主页:https://opengalaxea.github.io/G0/
论文地址:https://github.com/OpenGalaxea/G0/blob/main/Galaxea_G0_report.pdf
开源数据集:https://github.com/OpenGalaxea/G0
>>>现在成为星友,特享99元/年<<<

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇