编辑:严浠
近年来,LLM与VLM已成为实现通用人工智能(AGI)的核心驱动力。但如何从数智化(Digital Intelligence)迈向物理 AI(Physical Intelligence),让模型真正感知世界、理解具身任务并与真实环境进行交互,仍是实现AGI的一大瓶颈。
现有的具身基础模型往往是将LLM与VLM的能力扩展至具身场景,目前仍面临三大核心问题:
空间理解能力不足:难以精确建模相对/绝对空间关系并识别物理环境的可供性,严重制约了落地应用;
时序建模薄弱:缺乏对多阶段、跨智能体时序依赖与反馈机制的理解,导致长程规划与闭环控制受阻;
长链推理能力欠缺:无法从复杂人类指令中提取因果逻辑并与动态环境对齐,限制了在开放式具身任务中的泛化性。
为此,北京智源研究院RoboBrain团队提出面向真实物理环境的最新一代通用具身大脑RoboBrain 2.0,在上述三大核心问题上实现了全面突破,显著提升了机器人对复杂具身任务的理解与执行能力。该模型有两个版本:轻量级的RoboBrain 2.0–7B和全量级的RoboBrain 2.0–32B,能够满足不同资源条件下的部署需求。
目前,RoboBrain 2.0以及相关成果跨本体大小脑协同框架RoboOS 2.0已全面开源。

论文标题:《RoboBrain 2.0 Technical Report》
论文链接:https://arxiv.org/pdf/2507.02029
项目主页:https://superrobobrain.github.io/
开源代码:
https://github.com/FlagOpen/RoboBrain2.0
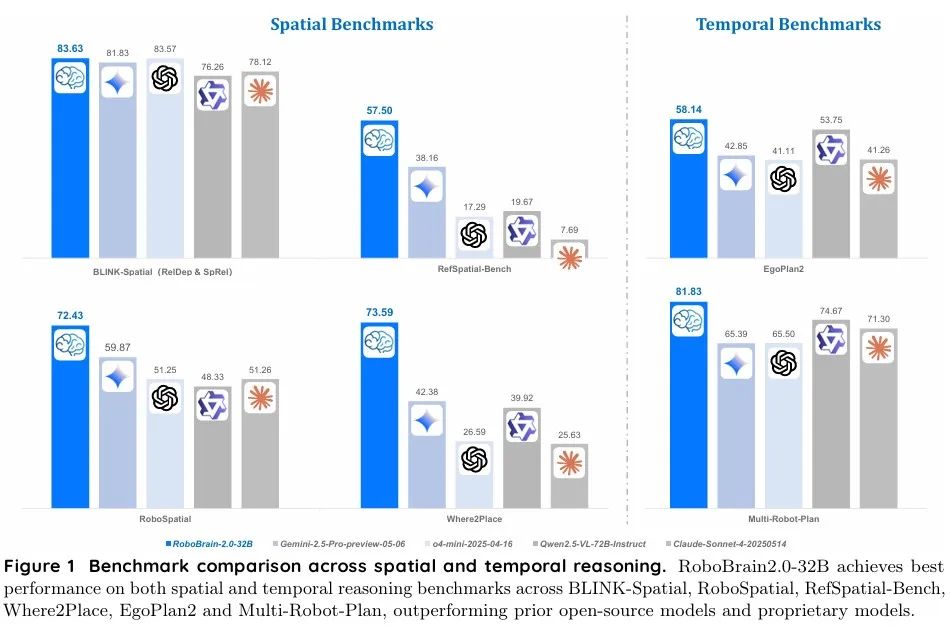
RoboBrain 2.0–32B在空间与时间推理基准测试中全面超越了包括谷歌Gemini 2.5 Pro、OpenAI GPT-4o-mini、Anthropic Claude-Sonnet-4在内的所有开源、闭源模型,达到了SOTA水平。
1
方法
1.1 模型架构
RoboBrain 2.0采用模块化编码器–解码器架构,统一了感知、推理与规划模块,以应对复杂的具身任务。模型整体架构如下图所示,通过四个核心组件处理多视角视觉观察与自然语言指令:
分词器(Tokenizer):处理文本/结构化输入;
视觉编码器(Vision Encoder):提取视觉特征;
多层感知机投影器(MLP Projector):将视觉特征映射至语言模型的词元空间;
基于Qwen2.5-VL初始化的语言模型作为主干网络。

与传统专注于通用视觉问答(VQA)的VLMs不同,RoboBrain 2.0在保持通用VQA能力的同时,专注于具身推理任务,包括:空间感知、时序建模和长链推理。该架构将高分辨率图像、多视角输入、视频帧、语言指令及场景图(Scene Graphs) 编码为统一的多模态词元序列,实现了全面综合的处理。

1.2 通用MLLM VQA
高质量数据:RoboBrain 2.0的通用训练数据集包含87.3万个高质量样本,主要来自LLaVA-665K和LRV-400K,涵盖标准视觉问答(VQA)、区域级查询、基于OCR的VQA以及视觉对话。
1.3 空间数据
空间数据旨在提升模型的空间感知能力。
视觉定位(Visual Grounding):基于LVIS的丰富标注构建视觉定位数据集,包含15.2万张高分辨率图像,生成了86万条多轮问答的对话,通过精准物体级定位增强多模态理解能力。
目标指向(Object Pointing):利用Pixmo-Points和RoboPoint数据集,通过过滤策略简化场景,聚焦目标物体,构建指向任务数据集。让模型理解“在图片里指出某个特定物体在哪里”的指令,并准确输出目标物体的位置。
功能可供性(Affordance):利用PACO-LVIS数据集的部件级标注,通过GPT-4o生成问题(例如,提问手提包的哪个部分可以用来抓握),训练模型识别物体可以抓握的部件。
3D空间理解:为提升模型的3D空间推理能力,构建了82.6万个样本,涵盖了31种空间类型。
空间推理(Spatial Referring):在3D空间理解基础上,引入了80.2万条“空间推理”数据,专门针对单一明确的目标,满足机器人抓取-放置需求。
1.4 时序数据
用于训练模型的规划和动态交互能力。
第一人称视角规划(Ego-View Planning):通过处理部分EgoPlan-IT数据集(包含5万个自动生成样本)构建第一人称视角的规划数据集。让模型学习从第一人称视角预测下一步的正确动作。
ShareRobot规划:ShareRobot数据集是一个面向机器人操作的,大规模、高质量、细粒度的异构数据集。该数据集显著提升模型在复杂具身环境中的细粒度推理与任务分解能力。
AgiBot规划:基于 AgiBot-World数据集构建的大规模机器人任务规划数据集(含9,148对QA,覆盖19项操作任务,109,378张第一人称视角图像)。该数据集提升了模型在复杂具身场景中的长时序任务规划与空间推理能力。
多机器人规划(Multi-Robot Planning):在RoboOS仿真环境中,设计了家庭、超市、餐厅等多智协作场景,利用DeepSeek-V3生成44,142个样本,提升模型的多智能体协作能力。
闭环交互(Close-Loop Interaction):在AI2Thor中,利用Embodied-Reasoner框架,生成了大量的“观察-思考-行动”(OTA)轨迹,将GPT-4o生成的思维链与视觉观察和具体行动无缝结合,提升模型的动态反馈和推理能力。
1.5 训练策略
RoboBrain 2.0采用渐进式三阶段训练策略,来实现空间理解、时序建模和思维链推理能力。每个训练阶段的详细配置如下表所示:

阶段1:基础时空学习(Foundational Spatiotemporal Learning)
通过在涵盖常见场景与交互模式的大规模多模态数据集上进行监督微调,旨在构建模型的空间感知与时序理解的基础能力。通过这一阶段的训练,模型能够处理静态图像和视频流,掌握物体的基本空间关系和运动事件,为后续更复杂的任务奠定了坚实的基础。
阶段2:具身时空增强 (Embodied Spatiotemporal Enhancement)
模型通过引入高分辨率多视图图像、第一人称视频数据以及导航和交互任务,进一步增强其在具身任务中的时空建模能力。模型学习处理长时序信息,支持多智能体协作、长时序规划和动态环境中的适应性决策。这一阶段使模型能更好地将历史视觉信息与当前指令相结合,从而在动态交互环境中实现更连贯的长程规划和稳定的场景理解。
第三阶段:具身场景思维链推理(Chain-of-Thought Reasoning in Embodied Contexts)
模型基于Reason-RFT两阶段框架(监督微调 CoT-SFT + 强化微调 RFT),进一步提升在复杂具身任务中的推理能力。这一阶段使模型能够生成思维链,支持复杂任务的推理和决策,从而在具身场景中实现更高效、准确地推理及规划。
2
实验
研究人员采用自研的多模态评估框架FlagEvalMM,对RoboBrain 2.0进行了全面评测,验证了模型在具身场景下的空间与时序推理能力。
2.1 空间推理能力
RoboBrain-32B-2.0与RoboBrain-7B-2.0在BLINK、CV-Bench、EmbSpatial、 RoboSpatial、RefSpatial-Bench、SAT、VSI-Bench、Where2Place和ShareRobot-Bench,这9个空间推理基准测试中表现突出,评测结果如下两个表所示。


结果表明,在RoboSpatial、RefSpatial-Bench、SAT、Where2Place和ShareRobot-Bench基准上,RoboBrain-32B-2.0均取得了SOTA成绩,大幅领先其他模型。轻量级的RoboBrain-7B-2.0在BLINK和CV-Bench上也取得了SOTA,展现了极高的效率和性价比。
2.2 时序推理能力
RoboBrain-32B-2.0和RoboBrain-7B-2.0在Multi-Robot Planning、Ego-Plan2及RoboBench三大关键时序推理基准测试中展现出卓越性能,评测结果如下表所示。

在Ego-Plan2基准上,RoboBrain-32B-2.0以57.23分达到SOTA;而RoboBrain 2.0 7B则在Multi-Robot Planning获得最高分81.50分,在RoboBench以72.16分达到SOTA。RoboBrain 2.0展现出卓越的长程规划、闭环反馈及多智能体协作能力。
RoboBrain 2.0共同一作冀昱衡是中国科学院自动化研究所博士生、北京智源研究院具身智能团队成员。主要研究方向为基于多模态大模型的具身智能。在CVPR,AAAI,MM等顶级会议上发表多篇论文。
8月14日晚上7点,冀昱衡博士将参加「智猩猩AI新青年讲座具身智能专题」30讲,以《面向真实物理环境的通用具身大脑RoboBrian》为主题进行成果讲解。

END
推荐阅读
20亿参数+全面超越π0!清华朱军团队&地平线提出全新VLA模型H-RDT,有效从人类操作数据中学习
机器人非抓取操作重大突破!北大&银河通用王鹤团队提出自适应世界动作模型DyWA | ICCV 2025
清华联合生数提出具身视频基座模型Vidar,20分钟真机数据实现跨本体泛化!
星海图联合创始人赵行:定义具身智能的ImageNet | 演讲回顾
RSS 2025最佳Demo奖!UC伯克利联合谷歌开源机器人强化学习框架MuJoCo Playground
点击下方名片 即刻关注我们