
全文约 2000 字,预计阅读时间 6 分钟
相信不少读者在 WAIC2025 大会上已经被华为云的 CloudMatrix384 超节点震撼到了。CloudMatrix 384对标英伟达GB200 NVL72方案,以384颗芯片对74颗,五倍数量的昇腾芯片来弥补每颗 GPU 仅相当于英伟达 Blackwell 芯片三分之一性能的差距。

近日,华为云推出新一代大模型服务系统 xDeepServe,基于 CloudMatrix384 超级集群,首次实现千卡级 MoE(Mixture of Experts) 模型的高效、可靠推理。
它如何在数百 NPU 上实现 2400 tokens/s/chip 的吞吐与 50ms TPOT(每输出 token 时延) 的极致性能?背后三大创新揭秘。

核心看点



华为云最新推出的 xDeepServe,是专为 SuperPod-scale(即超节点规模,指由很多服务器组成的超级集群)基础设施设计的大模型即服务(MaaS)系统。其核心创新在于提出 Transformerless 架构,将传统 Transformer 模型的计算单元——注意力(Attention)、前馈网络(FFN) 和 MoE(专家混合)——进行解耦,使其能独立部署在不同的 NPU(神经网络处理器)集群上,通过高速互联网络协同执行。
这一架构突破了传统集中式推理的瓶颈,实现了计算资源的灵活调度与高效利用。系统通过 FlowServe 服务引擎,结合 Multi-Token Prediction(MTP) 和 动态微批处理 技术,显著提升了硬件利用率。
最终,xDeepServe 在生产环境中运行 DeepSeek-R1/V3 等大模型时,达到了 2400 tokens/s/chip 的峰值吞吐,并稳定满足 50ms TPOT 的服务等级协议(SLA),为超大规模模型的高效部署提供了全新范式。
研究背景
随着大语言模型(LLM)参数规模的爆炸式增长,尤其是 MoE 架构的普及,传统的推理服务系统面临严峻挑战。
首先,计算资源异构性突出:MoE 层需要大量 NPU 用于专家计算,而注意力层则对内存带宽和 KV Cache 管理要求更高,统一调度极易造成资源浪费。 其次,通信开销成为瓶颈:在千卡以上规模,专家并行(EP)模式下的 All-to-All 通信(如 dispatch 和 combine)会产生巨大的元数据开销和网络拥塞,导致时延飙升。 最后,可靠性问题不容忽视:大规模分布式系统中单点故障可能导致服务中断。
现有系统往往采用整体式(monolithic)的推理架构,难以适应这种异构、高并发、长尾请求共存的生产环境。
xDeepServe 的切入点正是打破这一僵局,通过架构级解耦,将模型执行转变为一个可编程的数据流(dataflow)过程,从根本上重构大模型的推理范式。
核心贡献
1. Transformerless:解耦式计算架构

xDeepServe 的核心是 Transformerless 架构,它将 Transformer 模块分解为独立的计算单元——注意力计算单元(Attention TE) 和 专家计算单元(Expert TE),分别部署在专用的 NPU 集群上。这种解耦式执行(disaggregated execution)允许系统根据各模块的计算特性,进行独立的资源分配和调度。
为支持这种架构,团队设计了全新的 XCCL 通信库,其中包含两个关键通信原语(communication primitives):A2E(Attention-to-Expert) 和 E2A(Expert-to-Attention)。面对 288 个 MoE NPU 与 160 个注意力 NPU 这类不对称资源分配的难题,xDeepServe 创新性地引入了 “蹦床”(trampoline)机制:一部分 MoE NPU 先作为“中继站”接收数据,再转发给其余 MoE NPU。这一两阶段路由策略将元数据更新量减少了 90% 以上,有效平衡了通信负载,实现了跨千卡的高效数据交换。
在方法创新的基础上,团队进一步验证了 DP Domain 抽象与持久化内核调度。
2. DP Domain 抽象与持久化内核调度
为解决大规模数据并行(DP)下的调度难题,xDeepServe 提出了 DP Domain 抽象。该抽象将多个 DP 组封装起来,确保在任意时刻,只有一个 DP Domain 与 MoE NPU 集群进行交互。这避免了所有 DP 组同时发起 All-to-All 通信造成的“微批次(microbatching)”瓶颈,使得系统能在不牺牲批处理效率的前提下,支持数百个 DP 组并发运行。
此外,系统采用持久化内核调度(persistent kernel scheduling),让计算和通信流在 NPU 上持续运行,彻底消除了 CPU 调度带来的开销。这些设计共同将跨 SuperPod 的任务调度延迟控制在 200 微秒以内,为低时延推理奠定了基础。
最后,系统的性能与可靠性也得到了充分验证。
3. 高效执行与量化优化
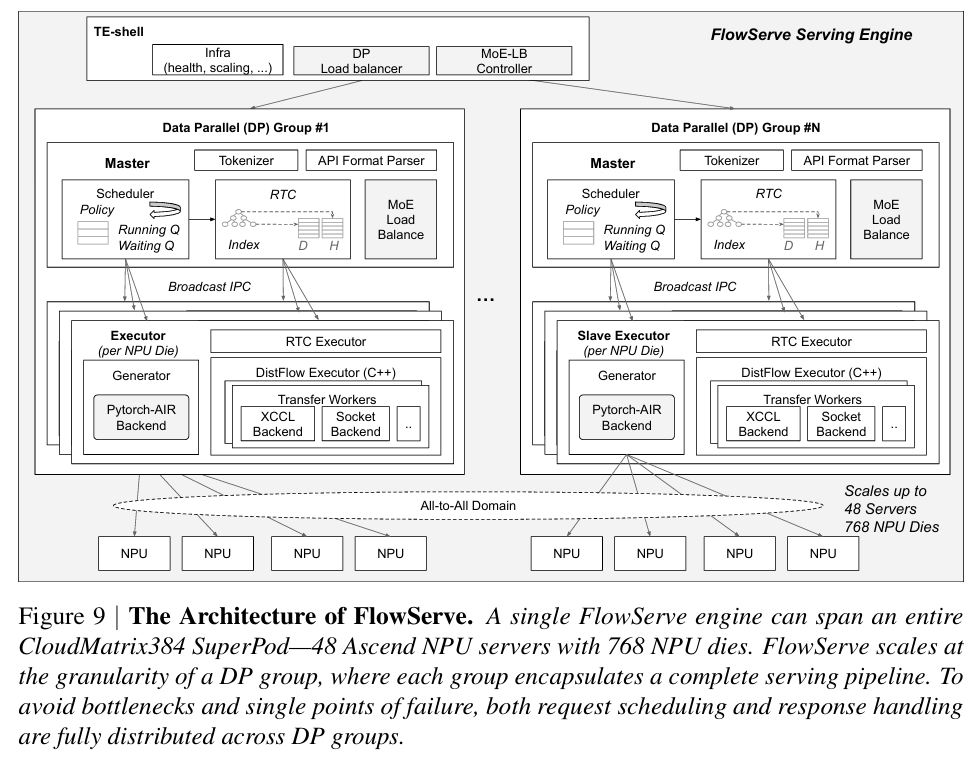
xDeepServe 内置的 FlowServe 服务引擎集成了 Multi-Token Prediction(MTP) 技术,通过一次前向传播生成多个“草稿”token,再由主模型验证,显著提升了吞吐量。在 DeepSeek 模型上,MTP 的接受率高达 90% ,使得平均 TPOT 从 93ms 降低至 50ms。

在模型层面,系统采用 INT8 量化以提升计算效率。针对 MLA(Multi-Head Latent Attention) 和 MoE/MLP 模块,团队设计了优化的量化策略:激活值采用逐 token 量化(token-wise quantization,每个 token 一个缩放因子),权重采用逐通道量化(channel-wise quantization,每个输出通道一个缩放因子),并通过误差补偿机制减少精度损失。推理时,利用硬件加速的 npu_quant_matmul (QMM) 算子进行高效的 INT8 矩阵乘法,进一步释放了 NPU 的算力潜能。
行业意义
xDeepServe 的发布,标志着大模型推理正从“尽力而为”的服务模式,迈向“可预测、可扩展、高可靠”的工业化阶段。其 Transformerless 架构为未来 LLM 推理系统指明了新方向——数据流式服务(Dataflow Serving),即模型计算被视作异步流动的数据流,组件间松耦合,系统整体更具弹性与可扩展性。
这一技术路线与国家推动的 “东数西算” 和 “算力网络” 战略高度契合,有助于实现算力资源的跨区域、精细化调度。它不仅能推动 自动驾驶、智能客服、代码生成 等领域的服务升级,更可能引发 云计算基础设施 的深层变革——未来的云服务或将不再售卖“虚拟机”或“容器”,而是直接提供“模型推理能力”作为标准服务。
xDeepServe 不仅是一次技术突破,更是华为云在 AI 基础设施 领域领导力的体现。它证明了通过全栈协同设计(full-stack co-design),从硬件、通信到软件架构的深度优化,能够真正释放大模型的生产力,为 AI 普惠化铺平道路。
推动大模型服务走向工业化,变革正在发生。
论文链接:xDeepServe: Model-as-a-Service on Huawei CloudMatrix384[1]
xDeepServe: Model-as-a-Service on Huawei CloudMatrix384: https://arxiv.org/pdf/2508.02520
-- 完 --
机智流推荐阅读:
1. WE-MATH2.0解锁数学推理新高度!北京邮电大学与腾讯WeChat Vision联手打造从小学到大学的多层级数学推理知识体系
3. GUI-Agent 领域新作!蚂蚁集团发布 UI-Venus,以截图驱动的智能交互,刷新行业标杆!
4. 本地也能玩转AI图片创作?腾讯3B开源模型实测:精准又轻便,统一生成理解,手把手教你部署
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










