本文通讯作者周王春澍,OPPO个性化AI实验室负责人,主要研究方向是AI个性化、智能体的自主进化和强化学习、以及大模型和智能体的记忆系统等。本文核心贡献者均来自OPPO个性化AI实验室的AI智能体团队。
近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。现有的多智能体框架通过多个角色明确、工具多样的智能体协作完成复杂任务,展现出明显的优势。然而,现阶段的 MAS 依然面临一些关键限制:
计算开销高:智能体之间频繁冗余的通信和复杂的工作流设计导致效率不高。
泛化能力有限:面对新领域或新任务时,需要大量的 prompt 设计与工作流配置。
缺乏数据驱动的学习能力:难以通过智能体任务数据实现持续提升性能。
底层的大语言模型(LLMs)未原生支持多轮、多智能体、多工具交互,仍依赖 prompt 工程实现。
同时,近期兴起的工具融合推理(TIR)模型,通过显式地将工具使用融入推理过程,显著提升了单智能体框架(如 ReAct)在信息检索任务中的表现。然而,传统的 TIR 模型,无法直接支持多智能体系统的原生训练与协作。
针对上述瓶颈,本文提出了一种全新的智能体推理范式——Chain-of-Agents(CoA)。与传统的 TIR 模型仅支持单一智能体的「思考-行动-观察」模式不同,CoA 框架能够灵活定义多个角色和工具的智能体,在单一模型内动态激活,实现端到端的多智能体协作。

论文:
https://www.arxiv.org/abs/2508.13167 主页:
https://chain-of-agents-afm.github.io/ 代码:
https://github.com/OPPO-PersonalAI/Agent_Foundation_Models 模型:
https://huggingface.co/collections/PersonalAILab/afm-models-689200e11d0b21a67c015ba8 数据:
https://huggingface.co/collections/PersonalAILab/afm-datasets-6892140eaad360ea5ccdcde1
与传统的 MAS 相比,CoA 无需复杂的 prompt 和工作流设计,降低了智能体间的通信开销,并支持端到端训练,显著提升了系统的效率和泛化能力。经过训练后,具备原生 CoA 问题求解能力的模型称为 Agent Foundation Model(AFM)。
在实验上,AFM 展示了卓越的性能和高效的推理能力,在近 20 项复杂任务和基准测试中全面刷新记录:在 Agentic 任务中,其在 GAIA 基准上以 32B 模型实现了 55.4% 的 Pass@1 成功率;在代码推理方面,AFM 在 LiveCodeBench v5 上的 47.9% 准确率和在 CodeContests 上的 32.7% 成绩均显著超越现有 TIR 方法。同时,它将推理成本(token 消耗)减少高达 85.5%,在保持领先性能的同时大幅提升效率。
CoA 的架构范式

CoA 采用了一种层次化的智能体架构,包括两个核心组成部分:
角色型智能体(Role-playing Agents):进行推理和协调的智能体,包括:思考智能体(Thinking Agent)、计划智能体(Plan Agent)、反思智能体(Reflection Agent)和验证智能体(Verification Agent)。
工具型智能体(Tool Agents):执行特定任务的智能体,包括:搜索智能体(Search Agent)、爬取智能体(Crawl Agent)和代码智能体(Code Agent)。
在 CoA 范式下,模型可以支持更多类型的智能体的推理和调用。
为了实现 LLMs 的原生多智能体协作推理能力,本文开发了一套专门的 CoA 微调框架,用于构建 AFM,该方法具体包括以下流程:

任务数据采集,生成与筛选:从公开数据集中采集不同类型的任务数据,以及采用自动化的方式(如 TaskCraft)自动生成高质量智能体任务,并进行有效过滤。
多智能体能力蒸馏:利用先进的多智能体框架(如 OAgents)完成任务,将成功轨迹转换为 CoA 兼容的形式。
监督微调与强化学习:利用生成的 CoA 轨迹进行模型微调,并通过可验证的智能体任务进行强化学习,进一步提升性能。
数据的构建
任务采集
为了构建丰富且多样的训练数据,本文首先从网页任务、数学和代码推理两大方面采样任务数据,并用于后续轨迹生成:
网页:利用开源 QA 数据集包括:NQ、TQ、HotpotQA、popqa、musique、2wiki、webdancer 以及利用 TaskCraft 自动化生成轨迹。
数学和代码:使用包括 LiveCodeBench v1-v3、CodeForces、ReTool SFT 和 SkyworkOR1 在内的编程和数学推理数据集。
SFT 轨迹生成
为了采集 CoA 适配的数据用于 SFT,本方法基于先进的多智能体系统 OAgents,建立了一套统一的轨迹采集框架,生成结构化的任务求解轨迹。具体来讲,本方法利用 OAgents 执行采集到的任务,并通过设定的规则产生反思和验证等行为,例如:按执行成功率对数据进行难度分级,对于难题引入反思机制,对于更难的题目基于答案引入规划生成的引导等。执行轨迹中有效的内容将通过规则转换的方式,以 CoA 要求的轨迹格式保存。最终产生约 87k 条 SFT 轨迹数据。
RL 数据筛选
为了进一步提升智能体的多工具协作策略,在强化学习(RL)阶段,本方法进一步利用约 85k 条高质量的 Agentic 任务、数学问题和代码任务数据,通过严格的数据质量筛选与策略抽样,确保强化学习专注于最具挑战的任务,防止过拟合。
实验
为了验证 CoA 范式与微调框架的有效性,本方法在多跳问答、智能体任务以及代码生成和数学推理等多个智能体基准上开展了全面的实验评估。
多跳问答(MHQA)任务评估
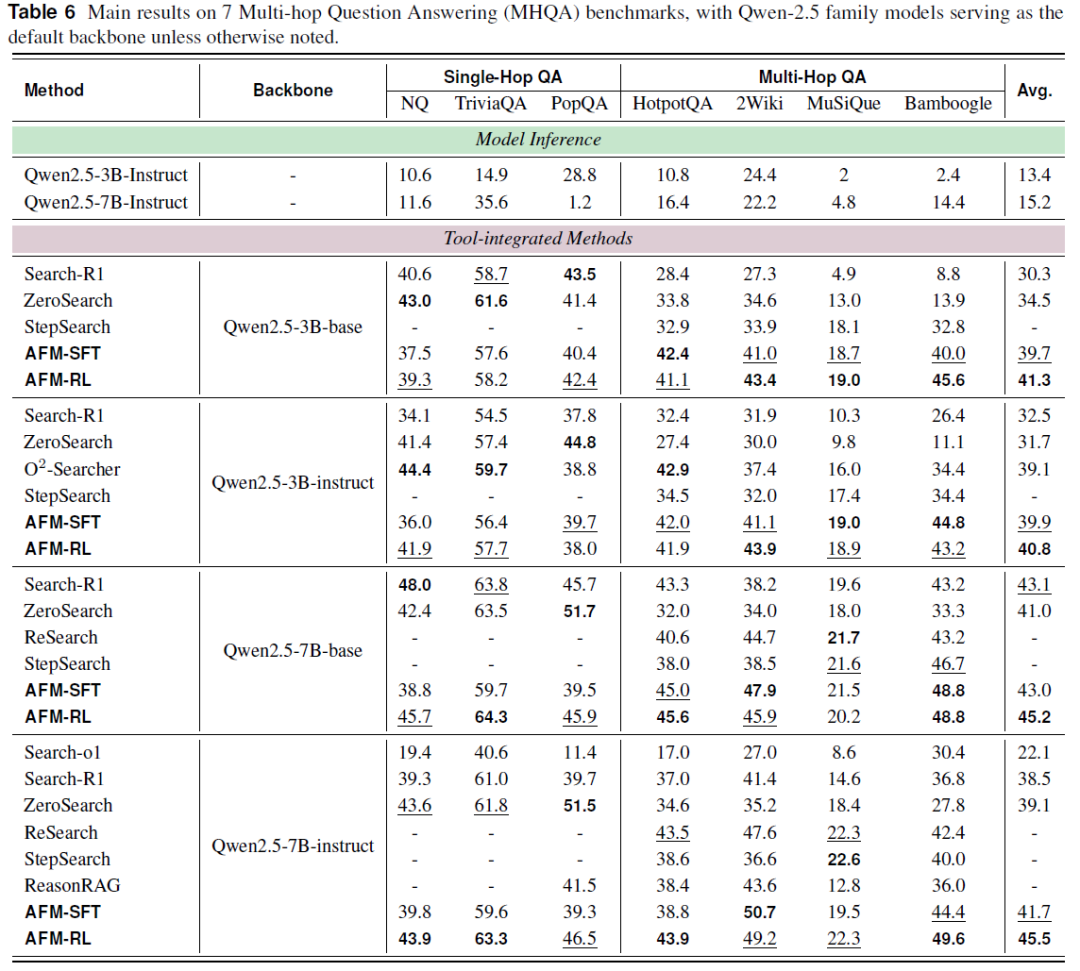
本文训练的 AFM 模型在 MHQA 基准任务的单跳与多跳问答测试集中展现出稳健且优异的性能,相较于同规模模型保持一致的有效性,且整体表现更为突出。具体而言,AFM-SFT 在多个数据集上接近或者超越了先前的 SOTA 方法,有效验证了多智能体蒸馏技术在协同智能迁移方面的优势。经过策略优化后的 AFM-RL,在七个数据集上达成了平均性能的新高,树立了当前任务中的新标杆。
在同类型且同规模的模型对比中,AFM 在不同的模型设置下都取得了领先成绩(例如以 Qwen-2.5-7B-instruct 为基准模型,平均准确率达到了 45.5%,相较 ZeroSearch 提升 6.4%)。
AFM 在多跳问答任务中的提升尤为显著,说明其在任务分解与工具使用方面具有更强的能力。并且在处理跨领域数据集时,AFM 的性能增益更加明显,表明通过该框架训练的模型具备更强的泛化能力与适应性。
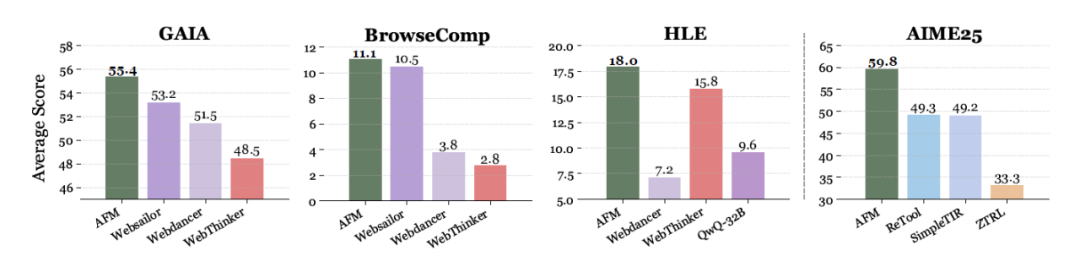
复杂网页搜索任务评估
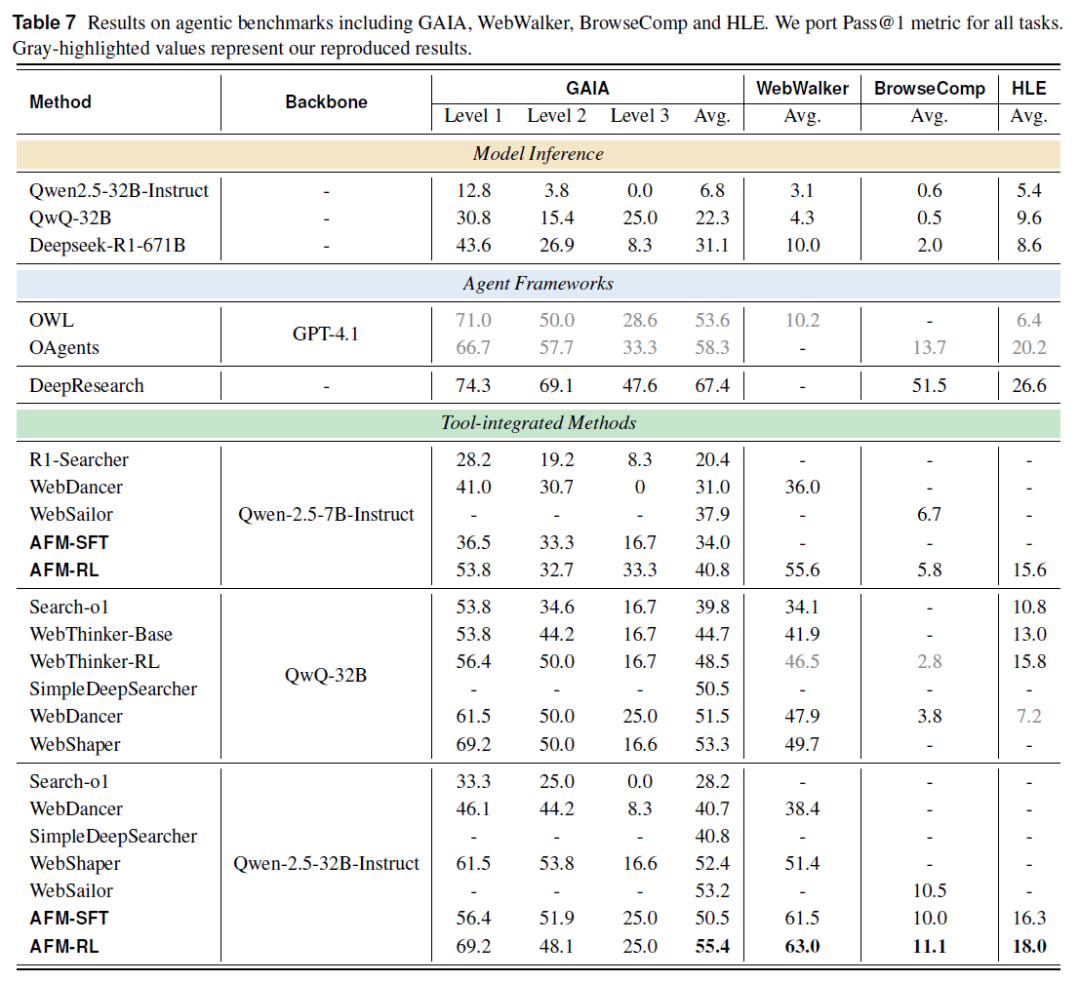
AFM 在多个复杂知识密集型任务中刷新性能纪录:
GAIA 基准:AFM(Qwen-2.5-32B-Instruct)得分 55.4%,领先 WebSailor(+2.2%)与 WebDancer(+3.9%)。
BrowseComp:成功率 11.1%,居 32B 模型首位。
WebWalker:准确率达 63.0%,超过 WebThinker-RL(+16.5%)、WebDancer(+24.6%)与 WebShaper(+11.6%)。
HLE 基准:得分 18.0%,优于 GPT-4.1 支持的 OWL(+11.6%)及 Deepseek-R1-671B(+9.4%)等多款主流推理模型。
即使使用更小的 Qwen-2.5-7B-Instruct 主干,AFM 仍在 HLE 任务中取得 15.6% 的成绩,仅略低于采用更大主干的 WebThinker-RL(15.8%),同时在多个基准任务中超越其他集成工具的 32B 模型。进一步验证了 AFM 在智能体问题求解中的高效性,以及多智能体蒸馏策略在跨模型尺度中稳定迁移协作智能的能力。
除此以外,本文还发现,单独 SFT 的模型也能取得优异的结果:
GAIA:AFM-SFT 得分 50.5%,优于 WebSailor-SFT(46.6%)。
WebWalker:AFM-SFT 达 61.5%,领先 WebShape-SFT(44.6%)。
BrowseComp:AFM-SFT 得 10.0%,高于 WebSailor-SFT(7.2%)。
这些结果均验证了 AFM 在工具协同、推理迁移和跨模型尺度上的卓越表现。
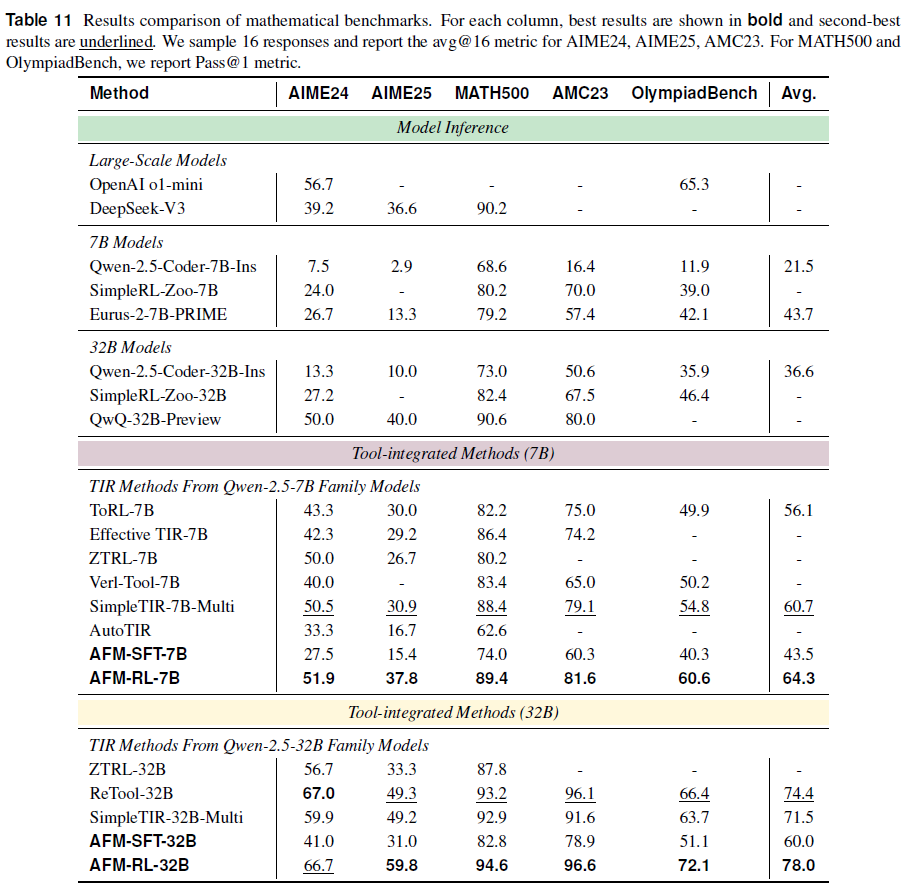
数学能力
AFM 在数学推理任务中展现出显著优势:
7B 模型:AFM-RL-7B 在五个数学基准上均表现最佳,平均准确率达到 64.3%,较次优模型 SimpleTIR-7B-Multi 提高 3.6%。
32B 模型:AFM-RL-32B 平均准确率为 78.0%,领先现有最优模型 ReTool-32B 同样 3.6%。在 AIME25 和 OlympiadBench 数据集上,AFM 分别取得 10.5% 和 5.7% 的绝对提升,体现了在复杂数学场景下更强的泛化与解题能力。
进一步分析训练过程中的阶段贡献:
对于 7B 模型,SFT 带来 22.0% 的准确率提升,RL 在此基础上再增益 20.8%。
对于 32B 模型,SFT 和 RL 分别带来 23.4% 和 18.0% 的性能增幅。
综合来看,AFM 通过多智能体蒸馏过程在 SFT 阶段获得了链式推理能力,如规划、反思和工具调用;RL 阶段进一步强化了这些能力,造就了其在数学推理任务中的全面优势。
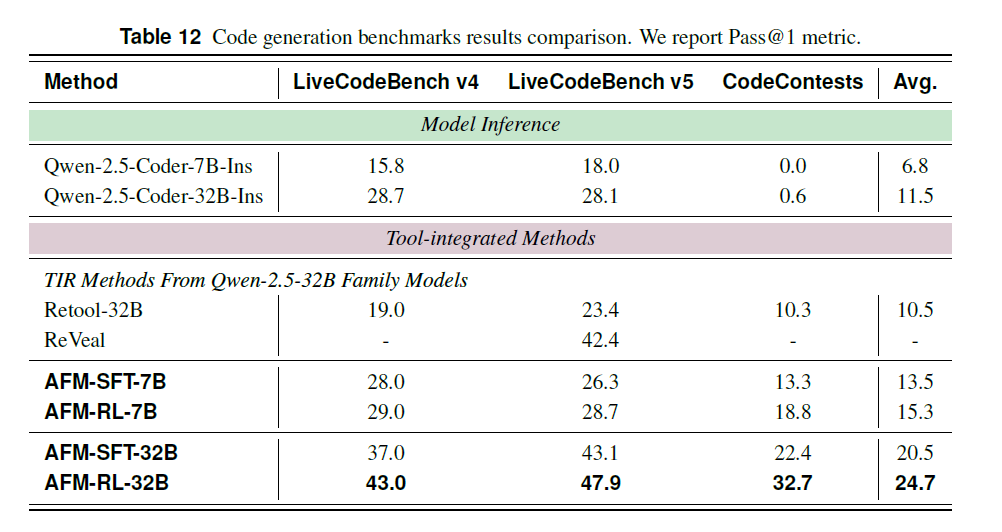
代码基准
AFM 在代码生成任务中同样表现优异,显著超越多个基线模型:
在三项高难度编程任务中(LiveCodeBench v5、LiveCodeBench v4 和 CodeContests),与基础模型相比,AFM 通过强化学习优化后在 7B 与 32B 模型上平均准确率分别提升 8.5% 和 13.2%,验证了其在代码生成能力上的增强效果。
面对使用代码解释器的主流 TIR 模型,包括基于数学训练的 ReTool-32B 与专注代码任务的 Reveal-32B,AFM 全面领先。即便仅采用 SFT 训练,AFM 在 LiveCodeBench V5 数据集上的表现亦优于上述模型,证明本文方法能有效提升复杂编程能力。
在 SFT 的基础上,经 RL 精调后,AFM 在 7B 与 32B 模型上进一步获得 1.8% 和 3.2% 的提升,体现了智能体强化学习对编程能力的持续增强效果。
效率分析

AFM 在工具调用效率和推理成本方面展现出显著优势,基于 GAIA 数据集的 10 个实例,对比 AFM 与三个主流框架(OAgents、WebThinker 和 AFM)在工具调用和 token 消耗上的表现。结果显示:
在工具效率维度上(单位任务成功所需调用次数),AFM 使用的工具调用次数最少。
在 token 效率方面(每个成功任务所需的提示工程成本),AFM 的 token 消耗最低,包括整体和工具相关 token。
Test-Time Scaling 分析
此外,AFM 在 Test-Time Scaling 方面表现卓越,并在多项智能体基准中展现稳健性能。通过对 GAIA、WebWalker、BrowseComp 和 HLE 四个任务的深入分析,AFM 及其变体:AFM-Bo3 与 AFM-Pass@3,在测试阶段进一步验证了模型的泛化与推理效能。AFM-Bo3 采用三选一优化策略,通过 Qwen-2.5-72B-Instruct 模型评估三个候选答案以选出最优路径;AFM-Pass@3 则采用三次尝试中至少一次正确的机制以提升任务完成率。

在与其他主流智能体模型对比中,这三种方式均在多项任务中展现出领先优势,证明了 AFM 具备优越的策略组合能力与稳健的跨任务适应性,也体现出该方法在训练后仍可通过推理策略扩展进一步提升表现。
结束语
CoA 范式与 AFM 模型的突破,本质上是通过层次化智能体架构与端到端训练,解决了传统多智能体系统(MAS)在通信效率、泛化能力与 LLM 原生协作支持上的核心矛盾。其技术价值不仅体现在近 20 项基准测试的性能跃升,更在于构建了一套可扩展的智能体推理框架——角色型智能体(思考、计划、反思、验证)与工具型智能体(搜索、爬取、代码)的动态激活机制,使 LLM 首次具备无需外部工作流配置即可完成复杂协作的能力。
从技术细节看,AFM 的优势源于两点:一是多智能体能力蒸馏过程中,将 OAgents 的成功轨迹转化为 CoA 兼容格式,实现了协作策略的高效迁移;二是 RL 阶段针对高难度任务的策略优化,显著增强了工具调用的精准性(如数学推理中 7B 模型经 RL 后准确率提升 20.8%)。这种「蒸馏-微调-强化」的技术路径,为其他智能体框架提供了可复用的训练范式。
然而,作为一项突破性工作,CoA 与 AFM 仍存在待探索的技术方向:
动态角色生成能力:当前角色型智能体的类型与分工需预先定义,未来可探索基于任务特性自主生成新角色的机制,进一步提升对未知任务的适应性。
跨模态工具融合:现有工具型智能体以文本(搜索、代码)为主,如何将图像、语音等模态工具纳入 CoA 框架,是扩展应用场景的关键。
长周期任务记忆机制:对于持续数天甚至数月的复杂任务(如长期科研跟踪),需设计更高效的智能体状态记忆与历史轨迹复用策略,避免重复推理开销。
这些待解问题,既是 CoA 范式向更通用智能体系统进化的必经之路,也为研究者提供了明确的技术探索方向。随着开源模型、数据集与代码的开放,AFM 有望成为智能体协作领域的重要基线,推动多智能体技术从「任务适配」走向「通用协作」。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com