

该论文收录在AAAI Conference on Artificial Intelligence 2025(CCF A),题目为《AnchorInv: Few-Shot Class-Incremental Learning of Physiological Signals via Feature Space-Guided Inversion》。
该论文的第一作者是英国牛津大学工程科学系的Chenqi Li,通讯作者是Tingting Zhu和Chenqi Li。
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/33563



论文概要
在生物医学领域,模型通常基于有限数据开发,且这些数据会随着新类别的出现而增量到达,要求在少量数据支撑下识别新类别的同时,需要保留对旧类别的认知且无需重训整个模型。此外,现有少样本类增量学习(FSCIL)方法的评估因其实验样本少的特性,对样本的选择极为敏感。
论文提出创新策略 AnchorInv,不同于选择和存储原始数据,其在特征空间中的锚点引导下生成合成样本,既能保护隐私,又能为模型微调提供正则化。在基础会话中,训练集被投影到特征空间,各类别锚点存储在锚点集内存中;在增量会话中,锚点集引导模型逆变换过程,生成先前见过类别的代表性样本,这些逆变换样本和少样本训练集随后被用于微调骨干网络,新类别的锚点也会陆续添加到锚点集内存中,供后续增量会话使用。
本研究在生理时间序列数据集BCI-IV 2a、NHIE、GRABMyo上对 AnchorInv 进行了评估,AnchorInv 在所有增量会话中均取得了最佳的 Macro-F1 分数。AnchorInv的方法框架图如图 1所示。

图1 Anchorinv的框架总览图


现有的FSCIL方法通常基于两个关键假设:一是拥有大量基类来训练泛化能力强的骨干模型,二是能够存储原始样本以供增量阶段使用。但在医疗场景中,基类数量通常有限,且直接存储数据会引发隐私问题。此外,简单微调骨干网络会导致灾难性遗忘,而生成对抗网络(GAN)等生成式回放方法又存在计算复杂性和模式坍塌等问题。
近期研究尝试通过模型反演技术(如DeepDream和DeepInv)生成合成样本,但这些方法主要在标签空间进行约束,可能无法充分防止特征空间的偏移。因此,本研究提出了一种基于特征空间锚点引导的反演方法,通过生成多样化的合成样本来平衡新旧类别的学习,同时保护数据隐私。这一方法在生理信号数据集上表现出色,超越了现有方法的性能。


(1)模型推理(Model Inference)
模型推理过程的目的是定义模型对输入样本的处理流程,其分为特征提取和分类两个阶段。特征提取阶段通过骨干网络将维度为H×W(H为通道数,W为时间步)的输入样本映射到特征空间,得到维度为D 的嵌入向量,即

分类阶段采用基于度量的分类器,通过计算嵌入向量与类别原型的相似度进行预测,其中,相似度函数s基于负余弦距离(归一化后)和温度参数T计算:

其中,分类器参数ϕk(t)由每个类别的平均嵌入(即原型)替代。
(2)特征空间引导的反转(Feature Space-Guided Inversion)
该模块是本研究的核心,通过锚点引导生成历史类别的合成样本,避免直接存储原始数据,正则化模型以防止遗忘,同时实现模型对新类别的高效适应。
首先进行锚点选择,对于每个会话t的训练数据,通过特征提取器得到特征集,再从特征集中随机采样或者通过聚类确定聚类中心选取锚点集:
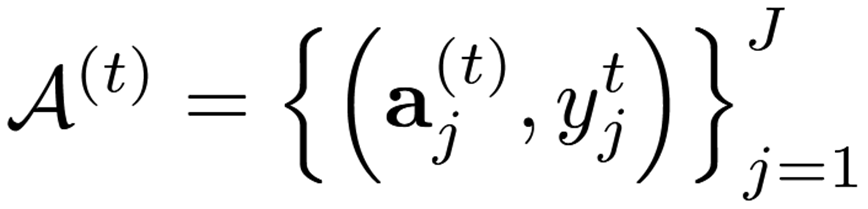
然后是反转阶段,从会话t的选定锚点集中推导出一个重放集:
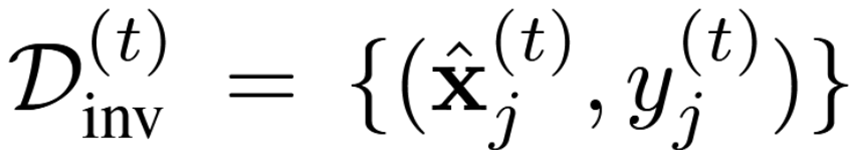
其用于正则化特征提取器对会话t+1的适应。这一推导过程的自然形式化定义使潜在重放样本的嵌入与锚点对齐,具体通过最小化算子实现:
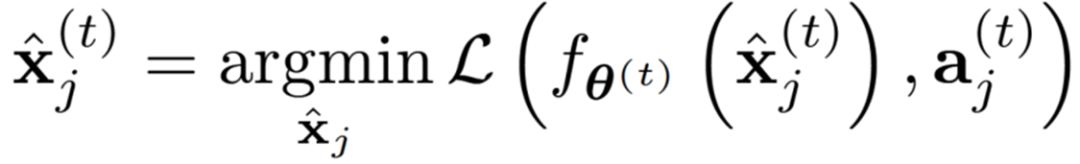
其中,L代表平均绝对误差(MAE)。该优化可以通过对随机初始化的重放样本进行梯度下降来实现。
最后是模型微调,微调通过新类别损失和历史类别损失的加权组合损失实现:新类别损失与历史类别损失分别基于当前会话的训练数据与所有历史会话的合成样本来计算分类交叉熵定义的。通过最小化该损失来更新特征提取骨干网络和分类器的参数。
(3)实验设计
由于少样本数据的随机性可能导致性能波动,论文采用多试验评估策略:在每个增量会话中随机采样M个训练集,分别训练M个模型副本。实验设置具体如图2所示,a)和b)分别表示现有文献中的评估流程和本研究采用的评估流程。本研究最终报告这些复制实验的均值和标准差。

图2 FSCIL的评估流程概况


实验分别在BCI-IV 2a运动想象EEG数据集、NHIE新生儿缺氧缺血性脑病EEG分级数据集和GRABMyo手势识别EMG数据集上进行,皆采用1-way 10-shot设置。实验使用EEG-Conformer作为骨干网络。AnchorInv在三个数据集的所有增量阶段均取得最佳Macro-F1 分数,尤其在BCI和NHIE数据集上分别比最优基线方法提升2.19%和3.24%,具体结果参见表1:
表1 Anchorinv与基线方法在三个数据集上的性能比较

研究对NHIE数据集的两个基类的锚点集和反演样本的特征向量进行降维可视化(如图3所示)。结果表示该方法能精确控制合成样本在特征空间中的位置,确保其与原始数据的统计特性一致,从而有效保留基类知识。
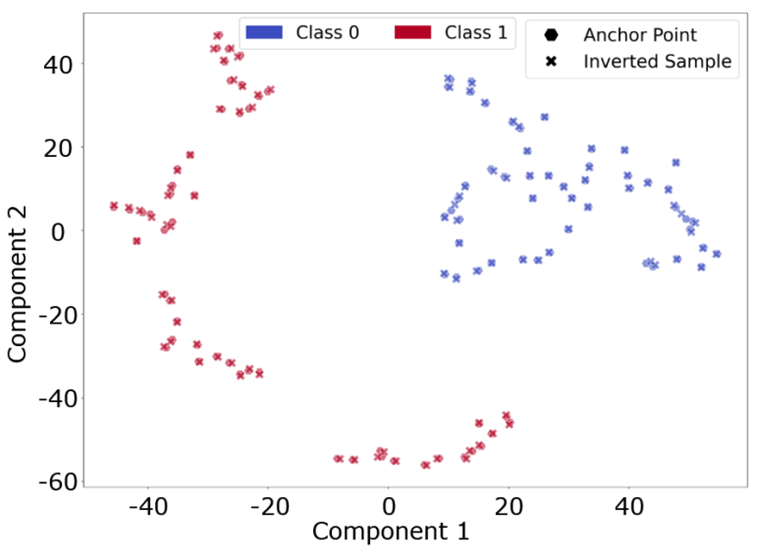
图3 锚点集与反演样本在特征空间的可视化对比
消融实验部分主要研究了AnchorInv方法中关键设计选择对最终性能的影响,集中在三个部分:
① 基类锚点选择策略的比较:锚点策略需要根据数据特性调整,但简单的随机采样在多数情况下已足够鲁棒。
② 增量阶段训练样本数量K的影响测试:当K≥10时模型性能趋于稳定,说明少量样本(10-shot)已能提供足够的增量学习信息,符合实际应用中数据稀缺的场景设定。
③ 基类锚点数量P的作用:性能随P增加而提升,当P≥50时趋于饱和,说明保留适量锚点即可有效表征基类分布,过度增加并不能带来显著增益。


结论
本研究针对生理信号少样本类别增量学习(FSCIL)中基础类别有限及数据隐私问题,提出AnchorInv方法。该方法通过特征空间锚点引导生成合成样本,无需存储原始数据,在保护隐私的同时缓解灾难性遗忘。实验在BCI、NHIE和GRABMyo三个生理数据集上进行,结果显示AnchorInv在各会话中均优于现有基线方法,尤其在基础类别有限时表现突出,有效平衡了历史知识保留与新类别适应,为生理信号增量学习提供了高效解决方案。
撰稿人:陈浩
审稿人:李景聪


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci


![倒计时5天!西门子EDA年度大会-AI EDA|3DIC|IC设计及验证|物理设计及验证|制造与测试[上海]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-23/68a9133d8a19e.jpeg)








