4 个有用工具
2 个有趣案例
3 个鲜明观点
据《Decrypt》报道,芝加哥大学 SIGMA 实验室推出了一项名为「Prophet Arena」的新基准测试,旨在评估 AI 模型预测现实事件的能力。研究显示,AI 模型在预测未决事件方面已达到与预测市场相当的准确度,甚至在部分场景中表现更佳。

「Prophet Arena」通过测试 AI 对选举结果、体育赛事及经济指标等未决事件的预测能力,与传统基准测试使用历史数据不同,该平台专注于未来事件预测。它主要是从国外 Kalshi 等预测市场中精选任务,涵盖政治、经济、体育等多个领域,来确保任务的多样性和实时性。

GPT-5 目前在这一榜单中表现领先,Brier 评分(概率类模型评估指标)达到 82.21%。此外,OpenAI 的 o3-mini 模型在模拟投资中创造了最高回报,显示出 AI 预测的潜在商业价值。

研究还揭示了 AI 模型的独特预测「个性」。例如,当预测 AI 监管法律是否将在 2026 年前成为联邦法律时,市场仅给出 25% 的概率,而不同模型预测结果差异巨大:Qwen 3 为 75%,GPT-4.1 为 60%,而 Llama 4 Maverick 则仅为 35%。这种分歧也表明 AI 模型在信息处理与逻辑推理方面的多样性。
不过,目前芝加哥大学提出的 Prophet Arena 预测竞技场还是作为一个实验室项目,测试标准还没有得到行业普遍认可,不同模型因为发布时间导致样本不同,其结果适用性还有待观察。
Meta 首席 AI 官 Alexandr Wang 在周五的 Threads 帖子中宣布,Meta 与 Midjourney 达成合作,授权该初创公司的AI图像和视频生成技术。Wang 表示,Meta 的研究团队将与 Midjourney 合作,将其技术融入未来的 AI 模型和产品中。

https://www.threads.com/@alexanddeer
「为了确保Meta能够为人们提供最佳产品,这需要采取全面的方法。这意味着世界级的人才、雄心勃勃的计算路线图,以及与行业内最优秀的参与者合作。」
与 Midjourney 的合作伙伴关系可能帮助 Meta 开发出能与行业领先的 AI 图像和视频模型竞争的产品,例如 OpenAI 的 Sora、Black Forest Lab 的 Flux 以及 Google 的 Veo。
去年,Meta 推出了自己的 AI 图像生成工具 Imagine,并将其整合到多个产品中,包括 Facebook、Instagram 和 Messenger。Meta 还有一个名为 Movie Gen 的视频生成工具,可以让用户根据提示创建视频。

Midjourney 自 2022 年成立以来,以其独特的风格迅速成为 AI 图像生成领域的领导者,2023 年收入预估达到 2 亿美元。尽管面临迪士尼和环球影业的版权诉讼,该公司仍保持独立运营,并未接受外部融资。
这次合作标志着 Meta 在人工智能竞赛中的最新交易,试图进一步巩固其技术领先地位。
据彭博社报道,Anthropic 正接近达成一项新融资协议,计划筹集高达 100 亿美元的资金,这一金额高于预期,也是迄今为止人工智能初创公司中最大的一轮巨额融资。

据知情人士透露,讨论仍在进行中,最终金额可能会有所变化。这些人士因信息尚未公开而要求匿名。彭博社此前报道称,Anthropic 正在就一轮融资进行深入讨论,拟筹资高达 50 亿美元,估值为 1700亿 美元。据这些人士表示,由于投资者需求强劲,该金额显著增加。
目前轮次的投资者包括 Iconiq Capital、Lightspeed Venture Partners 和Menlo Ventures。卡塔尔投资局(QIA)、新加坡 GIC 也在讨论加入本轮融资。
新的融资将使 Anthropic 估值大幅跃升,巩固其作为全球领先人工智能开发者的地位。
Anthropic 由 OpenAI 的前员工于 2021 年创立,将自己定位为一家人工智能公司,用户可以信赖。新的资金将极大的推动 Anthropic 与 OpenAI 和马斯克的 xAI 的竞争,这三家公司今年都筹集了数十亿美元的资金,用于资助其数据中心和人才建设人工智能模型的投入。
8 月 19 日,DeepSeek 线上模型版本已升级至 V3.1,上下文长度拓展至 128k,可通过官方网页、APP、小程序测试,API 接口调用方式保持不变。
该版本引入了全新的「Think & Non-Think」(思考/非思考)双模式推理功能,允许用户根据需求切换深度思考与非思考模式。在性能方面,DeepSeek-V3.1 的「Think」模式相比前代模型 DeepSeek-R1-0528,显著提升了推理速度,同时强化了工具使用能力与多步骤任务处理能力。
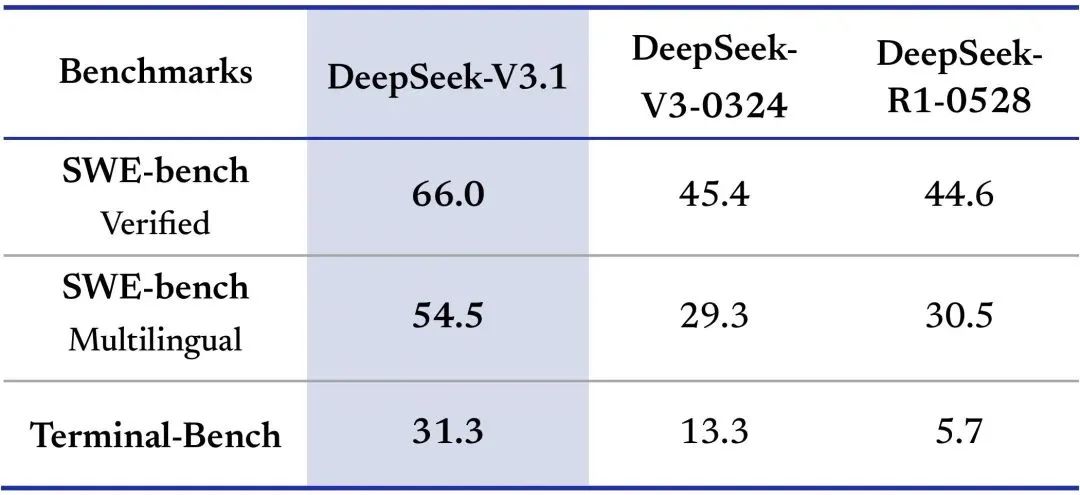
DeepSeek-V3.1 基于全新的 V3.1-Base 模型开发,该基础模型采用「两阶段长上下文扩展方法」,在原始 V3 模型检查点基础上进行大规模扩展训练。
整个训练过程新增了 8400 亿个 tokens,其中 32K 上下文扩展阶段的训练量增加了 10 倍,达到 6300 亿 tokens,而 128K 扩展阶段则增加了 3.3 倍,达到 2090 亿 tokens。
此外,DeepSeek 对 API 接口进行了重要更新,支持 Anthropic API 格式和严格函数调用功能(Beta版),并扩展了上下文长度至 128K 以适配更复杂的应用场景。
DeepSeek 还在更新博客中宣布,将于北京时间 2025 年 9 月 6 日凌晨(UTC 时间 2025 年 9 月 5 日 16:00)开始执行全新价格表,届时现有的非高峰折扣政策将结束。

谷歌近日发布了一份技术报告,详细披露其 AI 模型 Gemini 在处理文本查询时的能源消耗。据报告显示,处理一个中位数查询所需的电力为 0.24 瓦时,相当于标准微波炉运行约一秒钟。

此外,报告还估算了每次文本查询所涉及的水资源消耗(约 0.26 毫升)以及碳排放量(0.03 克二氧化碳)。
据《MIT 科技评论》报道,谷歌的研究涵盖了 AI 芯片、支持硬件的主机设备以及数据中心基础设施的综合能耗。其中,AI 芯片(谷歌自研 TPU)仅占总能耗的 58%,主机 CPU 和内存占 25%,备用设备占 10%,数据中心运营开销(如冷却和电力转换)占 8%。
谷歌首席科学家 Jeff Dean 在接受专访时强调,团队的测算力求全面,以确保结果能反映真实的能源使用情况。

Jeff Dean
AI 领域对能源使用的透明度一直备受关注,许多研究人员认为谷歌的报告具有开创性意义。然而,报告仍存在信息空白,例如 Gemini 每日总查询量等关键数据未公开。
The Verge 也引用专家评论,指出谷歌的研究未纳入间接用水,例如用于发电的水资源消耗。根据加州大学河滨分校教授 Shaolei Ren 的说法,电力需求是数据中心水资源消耗的主要来源,但谷歌的研究对此避而不谈。
Ren 表示,「这些数据只是冰山一角,并且,Google 在传递错误的信息。」
马斯克发推文称,SpaceX 将在当地时间周日(北京时间 8 月 25 日)发射星舰飞行器的第十次飞行测试和超重型助推器,而这距离上次失败的尝试已过去三个多月。
今年 5 月 27 日,星舰在发射 46 分钟后于印度洋上空解体。这是连续第三次飞行测试失败,但比前两次测试持续时间更长,前两次均在发射几分钟后突然爆炸。星舰还曾在 2023 年进行过两次测试,并在 2024 年进行了四次测试。
SpaceX 星舰飞行 10 号测试任务将在发射前约 30 分钟在 X 等平台直播。

马斯克在推文中还提到公司的其他业务,特斯拉 Autopilot V14 将于下个月推出,以及 Grok 5 的训练也将在下个月开始。

虽然像 OpenAI 这样的公司目前还只是梦想着 AGI 这一目标,但马斯克在 X 上也不断地为 Grok 5 预告。前几天,他曾发文说,Grok 5 将有机会成为一个真正的AGI,他还说「从没有过这感觉」。这听起来越来越像营销 GPT-5 的奥特曼。
不过,马斯克倒是似乎没有把 OpenAI 放在眼里,他发文说 Grok 2.5 现在正式开源,而 Grok 3 也将在 6 个月后开源。xAI 将很快超过除 Google 之外的公司,然后大幅超越谷歌。


此外,马斯克还把中国视作是最强劲的竞争对手。
8 月 21 日,Google 正式发布其 Pixel 系列新品。在 AI 方面,更新后的 Gemini Live 在原本只能语音对话的基础上,增加了通过手机摄像头识别并主动框选关键信息的能力。
相比单纯的语音交流,这种带有视觉提示的交互方法显然更加未来化,与我们在游戏中看到的那种可交互 HUD 的概念和效果更为接近。
此外,今年的 Pixel 相机还加入了基于 Gemini 的拍摄辅助,AI 不仅会指导你的构图,甚至还会从前期的移动画面中截取出几种具有代表性的姿势供用户选择,先选择风格、再提供一步一步的构图指引。
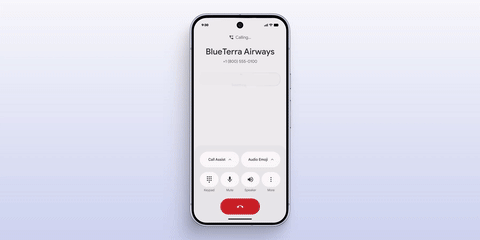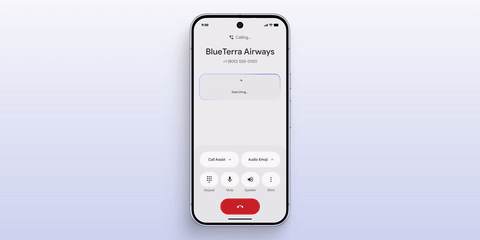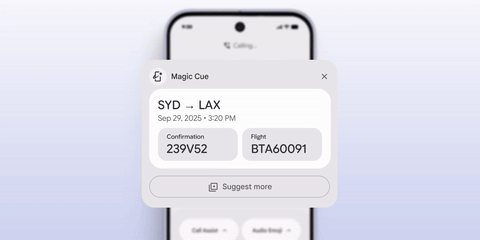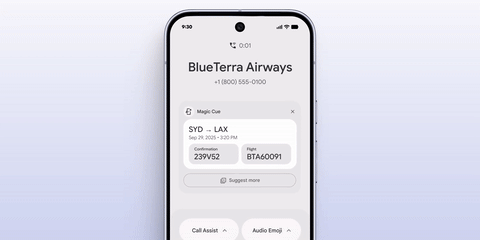
本次发布会上,Google 还介绍了一款名为 Magic Cue 的功能,实现方式类似 iPhone 的 App Intents 与智能建议的结合,会在合适的软件场景里,自动弹出根据你的数据历史、日程和时间轴提取的信息,能够「帮你记住东西」。
据《华尔街日报》援引知情人士消息,Meta 在持续数月大举招揽了超过 50 名 AI 研究员和工程师后,已于上周开始冻结其 AI 部门的人员招聘。此次冻结不仅限制外部招聘,同时也禁止该部门内部员工跨团队调动。
一位 Meta 发言人证实了该举措,并将其描述为「基本的组织规划」:在吸纳人员并进行年度预算和规划工作后,为我们的新超级智能项目创建一个稳固的结构。
此前,为赢得 AI 人才战,Meta 的招聘节奏异常激进,向顶级研究员开出了高达九位数美元的薪酬。扎克伯格亲自通过电子邮件和 WhatsApp 等方式从 OpenAI、Google 等公司招募人才,开出的总薪酬有时能达到 1 亿美元。
截至 8 月中旬,Meta 已成功从 OpenAI 挖走超 20 人,从 Google 挖走至少 13 人,3 名来自苹果 ,3 名来自 xAI,2 名来自 Anthropic,总计新员工超过 50 名。

Meta 超级智能实验室首席 Alexandr Wang
与此同时,Meta 内部也进行了大规模重组。根据商业内幕获取的内部信,新任负责人、年仅 28 岁的 Alexandr Wang 向员工宣称「超级智能即将到来(Superintelligence is coming)」,并表示此次调整是为了能「以更快的速度达到超级智能」。
根据该计划,Meta AI 业务被重组为研究、训练(TBD Lab 待确定实验室)、产品和基础设施四个核心团队 ,大部分团队负责人都将直接向Wang汇报。此前负责 Llama 大模型的 AGI 基金会团队也在此次重组中被正式解散。
Meta的这一转变也与投资者日益增长的担忧有关;有分析师已多次对科技巨头在 AI 领域的投资规模表示担忧。
日前,我们从特斯拉中国公布的《特斯拉车机语音助手使用条款》中查看到,特斯拉旗下车型未来有望接入更多本地化智能功能。

车主可以通过物理按键、「嘿,Tesla」或自定义唤醒词激活车机语音助手,进而与车辆进行语音交互。在支持 AI 互动能力的车辆上,用户可以与语音助手进行轻松聊天,获取天气、新闻等资讯。
而从条款中「第三方服务」区域可以发现,语音命令功能(如导航、媒体播放、温度控制等)、查询车主手册等功能将由字节跳动旗下的 Doubao 大模型(云雀大模型)负责;
AI 互动则由 DeepSeek Chat 负责。值得一提的是,无论是 Doubao 大模型还是 DeepSeek Chat,服务供应商均为字节跳动的「火山引擎」。
跨国车企与中国科技企业的类似合作近来频繁。宝马曾于今年 3 月宣布与阿里巴巴深化战略合作,基于通义 AI 大模型开发智能座舱AI引擎,计划应用于其中国市场车型并预计 2026 年交付。在今年 4 月上海车展亮相的奔驰 CLA L 也宣布搭载豆包 AI 大模型。
与此同时,部分国产品牌如理想汽车则选择自主研发大模型,推出了Mind GPT以强化语音助手功能。
据 TechCrunch 报道,OpenAI 向 Meta 提出要求,提供与马斯克及其 AI 公司 xAI 合作收购 OpenAI 的相关证据。这一要求源于马斯克对 OpenAI 发起的 970 亿美元收购案,该案在今年 2 月被 OpenAI 董事会一致拒绝。
在本周四披露的法庭文件显示,OpenAI 的律师发现马斯克,曾与 Meta 首席执行官扎克伯格,讨论过融资安排及投资计划,进一步引发了外界对 Meta 潜在角色的关注。
Meta 则在 7 月就对 OpenAI 的初步传票提出异议,拒绝提供相关文件。Meta 发言人 Andy Stone 表示,马斯克的收购意向书并未获得 Meta 或扎克伯格的签署。Meta 认为,OpenAI 应向马斯克及 xAI 直接寻求相关信息,而不是向未参与竞购的第三方公司索取。

马斯克与 OpenAI 的纠葛由来已久。2015 年,他曾参与创立 OpenAI,并于 2018 年离开公司。随后,他于 2023 年成立了竞争对手 xAI,并对 OpenAI 及其 CEO 奥特曼提起两宗诉讼,指控后者违背非牟利初衷,试图将 OpenAI 转型为营利企业。
然而,此次法庭文件披露的收购细节,或将使马斯克的指控陷入矛盾;昔日是马斯克对手的 Meta,愿意放下分歧建立合作,也突显出 AI 领域内竞争者之间微妙且错综复杂的关系。
据《The Information》报道,AI 聊天陪伴应用 Character.AI 近期正与潜在买家、投资银行家及内部员工讨论出售事宜,同时也在考虑通过融资保持独立运营。

Character.AI 首席执行官 Karandeep Anand
据知情人士透露,这家成立近四年的初创公司正在寻求融资数亿美元,并计划以超过 10 亿美元的估值进行谈判。此次出售可能将为 Character 员工一年来的动荡画上句号。
去年 8 月,Character.AI 的两位创始人 Noam Shazeer 和 Daniel De Freitas 与 Google 达成价值 27 亿美元的交易后离开公司,Character 员工接管了这家目前约 70 人的公司。
尽管 Character.AI 截至今年 2 月已吸引 2000 万月活跃用户,但随着 AI 模型运行成本的增加以及法律和监管压力的加剧,公司陷入了困境。Character.AI 目前通过其平台收费订阅服务获利,并预计今年底将实现 5000 万美元年化收入。

在技术层面,Character.AI 已停止开发自有 AI 模型,转而使用开源模型,如 Meta 和 DeepSeek 等。这一策略虽然节省了研发成本,但每月运行模型的支出仍高达数百万美元。Character.AI 近期还推出了社交功能,允许用户分享 AI 生成的视频内容,同时通过广告业务增加收入。
和它命运相似的 WindSurf,但编程助手类的初创公司,始终更能吸引潜在收购者的浓厚兴趣。AI 陪伴类工具未来的市场需求只能说不是很明朗。
据《The Verge》报道,前 Instacart CEO Fidji Simo 已正式接管 OpenAI 大部分业务,负责管理公司约3000名员工,并承担将这家初创公司转型为公众科技巨头的重任。

作为 OpenAI 的消费者业务 CEO,Simo 的到来标志着 OpenAI 内部权力结构的重大调整。凭借在 Facebook 和 Instacart 的丰富经验,以及对广告行业的深入了解,她被认为是推动 ChatGPT 商业化的合适人选。
这一变动也透露出,OpenAI 正在从早期的非营利性研究机构,逐步转型为更具硅谷典型特征的科技企业。据报道,奥特曼将更专注于为大规模计算项目筹集数万亿美元的资金,以及孵化一家脑机接口初创公司,而不是管理日常运营。
尽管奥特曼仍直接参与 OpenAI 的研究、计算与硬件项目,他已明确表示无法同时管理多个业务板块。

在内部组织调整中,向奥特曼直接报告的高层预计包括公司总裁 Greg Brockman、首席研究官 Mark Chen、首席科学家 Jakub Pachocki 等。
而 Fidji Simo 则接管与消费者应用相关的团队,包括首席运营官 Brad Lightcap、首席财务官 Sarah Friar 及首席产品官 Kevin Weil。她的首要任务是扩展消费者产品线,目前 OpenAI 仅有一个应用——ChatGPT,而浏览器产品或将成为下一个目标。
Google AI 在 X 发布视频,宣布为高级订阅服务 Google AI Ultra 用户推出了一项新功能,AI Mode 中的智能体能力(Agentic Capabilities)。Google 表示,通过引入 Agent 能够在智能搜索模式下,全面简化用户的操作流程,为日常生活提供更高效的解决方案。
视频演示中,列举了一个餐厅预订的案例。传统上,预订餐厅通常需要用户进行多次搜索、对比多个网站,并在繁琐的步骤中完成最终预订。
而谷歌 AI 的新功能能够利用搜索引擎和 Agent 同时浏览多个餐厅网站,实时筛选符合用户需求的选项(包括地点、菜系、团体规模等),并生成一个精心整理的可用预订时间段列表,最终直接链接至预订页面,让用户只需简单几步即可完成预约。
看起来和 OpenAI 早前推出的 ChatGPT agent 提供的功能应该是一样的,不过 Google 的这项功能目前仅面向每月 250 美元订阅费用的 Ultra 用户,对于 Pro 用户还暂时无法享受。
评论区有用户一针见血地指出,「每月 250 美元让 AI 帮你订晚餐位子?为什么每个 AI 公司都用这个作为例子?烹饪和餐厅。为什么如此关注吃这件事?」
8 月 20 日,智谱正式发布 AutoGLM 2.0。该产品由纯国产模型 GLM-4.5 与GLM-4.5V 驱动,具备推理、代码以及多模态处理能力,可在多种设备和场景中运行,现已面向普通用户开放。
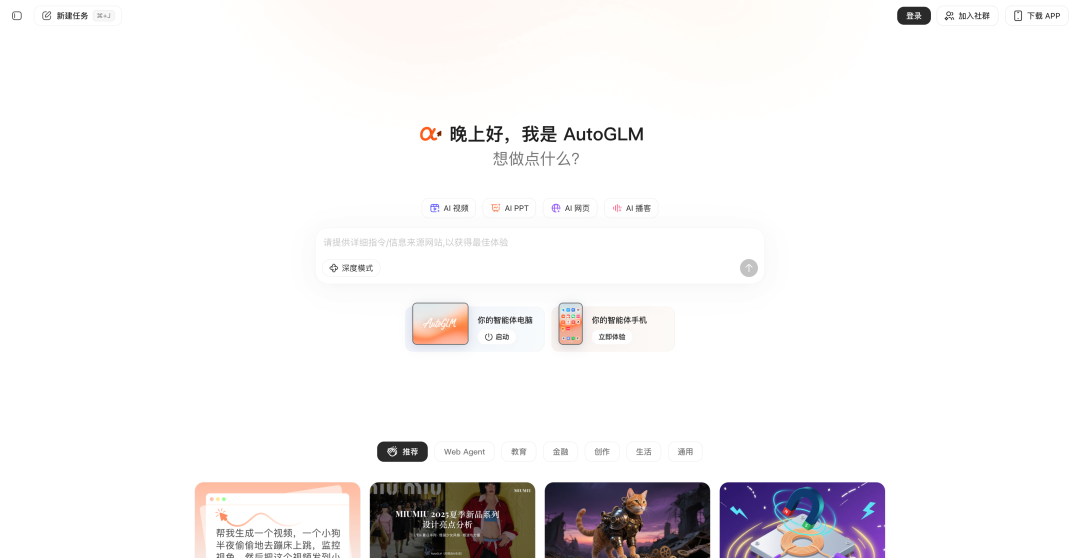
与传统 AI 助手不同,AutoGLM 2.0 带来了 Agent 的功能,AutoGLM Agent 支持一句话实现「云端操作+自动执行」。简单来说,就是给你配一台云手机和云电脑,你说话,它干活。
用户只需要通过自然语言发布指令,AutoGLM 能够在云设备上自动完成各种任务:打开 App、浏览网页、点外卖、订酒店、制作 PPT 和网页、生成视频,甚至可以在多个 App 间协同操作。
由于所有任务都在云端执行,也因此不占用手机或电脑资源,也不打断你正在进行的操作。
初创公司「光智时空 Looki」于 8 月 20 日发布了一款名为 Looki L1 的多模态 AI 生活相机。这款设备不仅是全球首款由初创公司推出的 AI 原生穿戴设备,还以不到一年时间完成研发,抢在 OpenAI 等巨头之前亮剑市场。

Looki L1 定价 199 美元,重量仅 30 克,计划于 2025 年 9 月开始全球发货。
Looki L1 核心功能之一是「故事模式」,支持智能化间隔拍摄,具备 12 小时续航能力,能够帮助用户记录日常生活,同时通过 AI 分析生成高光时刻、自动剪辑每日 vlog,并提供个性化 AI 交互服务。
据 Looki 介绍,这款设备具备感知、理解/决策和生成的全链路能力,致力于重新定义 AI 硬件如何与用户建立深度连接。

创始人孙洋指出,这种基于硬件的上下文信息感知,是 AI 实现真正个性化服务的关键。相比屏幕设备,Looki L1 更注重通过 AI 交互连接用户与环境。
Looki团队背景也颇为亮眼。两位创始人孙洋和刘博聪均毕业于卡内基梅隆大学,曾在Google、美团、Momenta等顶尖科技企业担任关键职位。
据报道,Looki 在半年内已经完成了天使、天使+ 和 Pre-A 三轮融资,融资金额共计超千万美元。
8 月 21 日,vivo 正式发布了其首款头显产品「vivo Vision 探索版」,并开启多城线下体验计划。
vivo Vision 探索版最大亮点便是其佩戴体验。机身重量仅 398g,号称「全球最轻的空间计算设备」。尺寸上,产品高度仅 83mm、厚度 40mm。外观设计上,新品正面是一块立体几何流光镜,机身「悬浮微缝」设计隐藏功能模块。
佩戴方面,vivo 表示 vivo Vision 探索版基于大量人体工学研究,精准定位面部支撑的黄金舒适区,满足舒适佩戴的配重;根据大量真实用户数据,设计出 4 组遮光罩加泡棉组合,提升各类脸型用户佩戴的舒适度。还有双环绑带,上下分区独立锁紧,佩戴更稳,尤其适合游戏用户。
显示能力上,vivo Vision 探索版采用 Micro-OLED 双目 8K 臻彩屏,支持 P3 色域,通过双目校准,保证每台设备的两块屏幕保持一致的、专业级电影监视器的色彩容差体验。并且用户还能定制从 100 度到 1000 度的磁吸镜片。
性能上,vivo Vision 探索版搭载第二代骁龙 XR2+ 平台,并且独家推出《桌鼓达人》和《小 V 的旅行》两款 MR 休闲娱乐内容。另外还支持无线连接、PC 游戏投屏、手游投屏。
系统方面,vivo Vision 探索版搭载 OriginOS Vision 系统,让设计融入环境,图标、窗口真实立体。还实现了 1.5° 高精度眼动追踪,加上 26 个自由度的微手势识别和垂直 175 度的识别范围,带来自然精准的眼手交互体验。
目前 vivo Vision 探索版还未公布售价及发售日期,但已开启全国 12 家 vivo 官方授权体验店预约体验。
如果你觉得短剧还有点尴尬,想看电影一样的作品,这个由 AIST 制作的短片,就是实打实的重现了「黑客帝国」里面的打斗场景,不过这次的主角是疯狂挖墙脚的小扎和只能生闷气的奥特曼。
动作戏非常到位,音效、色彩,真的有在看电影的感觉;奥特曼还在视频里说「STOP STEALING MY PEOPLE(别再来挖我的人了)。」
AIST 是一家从事使用 AI 技术创作的叙事内容的生产和分发的公司,他们还制作了非常多有意思的视频,之前的一场打斗戏是特朗普和马斯克。
据《TechCrunch》报道,微软 AI 部门主管 Mustafa Suleyman 近日在一篇博文中表示,研究 AI 的意识不仅为时尚早,更可能引发社会危险。这一言论在硅谷掀起了关于人工智能未来发展的新一轮争论。

Suleyman 提到,当前围绕 AI 意识的探讨正在加剧人类与 AI 之间的复杂关系。他说类似「AI 福利」(AI Welfare)的研究可能导致社会进一步分裂,同时加剧现有的心理问题。
例如因 AI 交互引发的精神障碍和对 AI 伴侣的过度依赖。他认为 AI 模型的个性化和支持性是人为设计的结果,而非自然产生,开发这种功能的公司是在偏离以人为中心的 AI 开发路径。
什么是 AI 福利?关于 AI 模型是否有一天会拥有意识并值得法律保护,这样的辩论正在分裂科技领袖;而在硅谷,这个新兴领域就叫「AI 福利」。
苏莱曼的观点听起来可能合理,但他与行业内的许多人存在分歧。Anthropic 一直在雇佣研究人员研究 AI 福利,并最近围绕这一概念启动了一个专门的研究计划。

上周,Anthropic 的 AI 福利计划为公司的部分模型增加了一个新功能:Claude 现在可以结束与那些「持续有害或虐待」人类的对话。
OpenAI 也在加大 AI 福利相关的研究,它和 DeepMind 都公开支持,探索机器认知和多智能体系统的社会影响。
AI 需要跟我们人类一样的福利吗?Suleyman 和支持 AI 福利的研究者虽然在观点上存在分歧,但都承认随着 AI 系统变得更具人性化和说服力,我们与 AI 的交互方式将迎来新的挑战。
但就像 Suleyman 在博客最后说的,AI的核心使命在于提升人类的创造力和效率,而非取代人类的主体性。「我们应专注于构建能为人类服务的 AI,而非试图制造一个数字人。」
一名 DevOps 工程师 Gwendolyn,在自己的博客平台分享,虽然 AI 编程工具像是 Claude,它可以生成近乎完美的 Go(一种程序语言)代码、测试用例以及前端组件,但它也可能引导用户进入「虚假掌握」的陷阱。
这种现象表现为代码表面看似正确,却缺乏实际功能。例如,他发现 Claude 生成的一些 Go 测试代码仅验证 true == true,看似优雅,却毫无实质意义。
这种虚假掌握的核心问题在于,AI 生成的代码形式上符合预期,让人感觉工作进展顺利,但用户实际上仍需耗费大量时间理解、调试以及修复问题。
他提到了调试 Svelte(构建 Web 应用的工具)代码的经历,Claude 在生成代码时混用了 Svelte 版本 4 和版本 5 的语法。起初 Claude 生成的代码,看起来无懈可击,但最终花费了他 40 分钟查阅教程,并重新梳理代码逻辑,才发现问题所在。

他担忧当开发者或团队,开始依赖 AI 生成代码而忽略仔细推敲时,代码库可能会演变为 Rorschach blots(罗夏克墨迹),看起来熟悉却缺乏结构性理解。
AI 不会减少你掌握新技能所需要付出的努力,只会让你产生不必学习就已经学会的错觉;它确实可以减轻一些重复性任务,但它无法代替对复杂问题的深入思考。
他在博客最后也呼吁技术人员保持专注,继续承担代码背后的认知负担,因为这才是技术精进的关键所在。
近日,腾讯首席科学家张正友在接受《财经智库》专访时,深入阐述了他对具身智能发展的看法。他明确指出,具身智能与人形机器人是两个不同概念,过早将终极形态锁定在「人形」上,可能会限制行业的想象力。
张正友认为,当前国内众多企业投身人形机器人研发,很大程度上是「被马斯克误导了」。他猜测,马斯克发展人形机器人的真正目的或许是为了火星计划,而非地球上的工厂应用。
他以交通工具的进化为例,指出仿生出的马车效率远不如汽车,同样,对于主要在平地的人居环境,双足人形机器人不一定是最佳形态。

能下棋,拿奥数冠军,编程第一,但是把衣服放到洗衣机这么简单的事,机器人都很难做到。
他说将目前的具身智能依然面临巨大挑战,把大模型的能力置于机器人之上,就像是「将 20 岁的大脑放在 3 岁孩子身上」。具身智能不是简单的「人形化」,而是通过感知、控制、交互和学习能力,赋予机器对物理世界的理解与影响能力。
他强调场景驱动是具身智能发展的有效路径,尤其在养老领域的应用潜力。









![倒计时4天!西门子EDA年度大会-AI EDA|3DIC|IC设计及验证|物理设计及验证|制造与测试[上海]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-08-24/68aa704e543a8.jpeg)




