腾讯ARC Lab 投稿
量子位 | 公众号 QbitAI
让视觉token说话,既能看懂图像,又可以画出图像!

腾讯ARC Lab联合中科院自动化所、香港城市大学、浙江大学等机构提出了一种全新的视觉分词器——TokLIP,即Token+CLIP。
可以将低级的离散视觉Token与高级的CLIP语义相结合,实现多模态理解与生成的高效统一。
不仅支持端到端的自回归训练,还能无缝接入现有LLM框架,极大降低了多模态模型的计算与数据门槛。
训练数据量仅需同类方法的20%,还可以在图像分类、图文检索和多模态理解等多项任务中达成SOTA,有理由相信,TokLIP或将成为构建下一代多模态通用模型的重要基础组件。

下面是更多详细内容介绍。
TokLIP 的结构与核心设计
过去几年里,人工智能的发展已经从单一模态走向多模态,无论是图像、视频,还是文本,人们希望机器能够像人类一样,既能“看懂”世界,也能“说清”所见。
其中关键问题是:如何在同一个模型中实现统一的理解(comprehension)与生成(generation)能力。
目前的自回归多模态大模型对图像的编码大多依赖两类核心部件。
一类是视觉编码器(如CLIP),它擅长把图像转化为高层语义表征,从而实现跨模态对齐,但是难以支持视觉生成任务。
另一类是视觉tokenizer(如VQ-VAE系列),它能把图像离散化成token,使其在形式上与文本一致,方便自回归Transformer联合建模。
比如Emu3和Chameleon采用了全模态离散化的方案,把图像、文本甚至其他模态统一转化为离散token,交给大语言模型直接处理,这种方法在形式上实现了统一,但缺点在于:离散token包含的信息大多为图像底层特征,导致语义信息不足,统一训练的代价高昂,多模态理解任务性能受限。
另一方面,VILA-U等工作则强调通过离散化CLIP特征来增强视觉理解,但往往在语义对齐与底层重建的统一之间产生冲突,加大训练损失的优化难度,可能出现“理解强但生成弱”或者“生成顺畅但语义模糊”的问题。
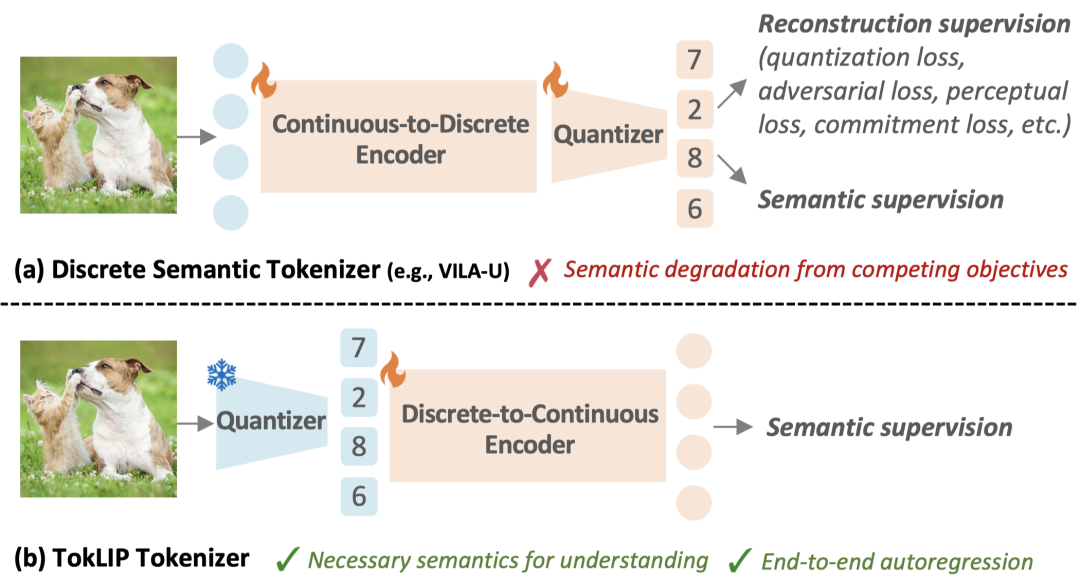
因此,多模态领域迫切需要一种新的方法,能够既保留视觉tokenizer的形式统一性,又融入CLIP级别的语义理解力,从而打破“理解与生成割裂”的瓶颈。
视觉Token语义化:让图像“能说话”
TokLIP的关键创新在于引入CLIP的语义来对视觉token进行语义化处理。
这意味着,图像被分解成的每一个离散token,不仅携带底层结构信息,还被注入了与语言对齐的高层语义信息。
因此后续的自回归模型不再面对“无意义的符号串”,而是直接处理带有语义标签的token,从而在跨模态对齐和任务泛化能力上都显著提升。
换句话说,TokLIP让视觉token不再只是“图像的残片”,而是变成了“会说话的语义单元”。
TokLIP框架与训练流程
在模型架构上,TokLIP采用了视觉tokenizer与ViT-based token encoder相结合的方式,并通过语义监督损失学习图像高层特征。
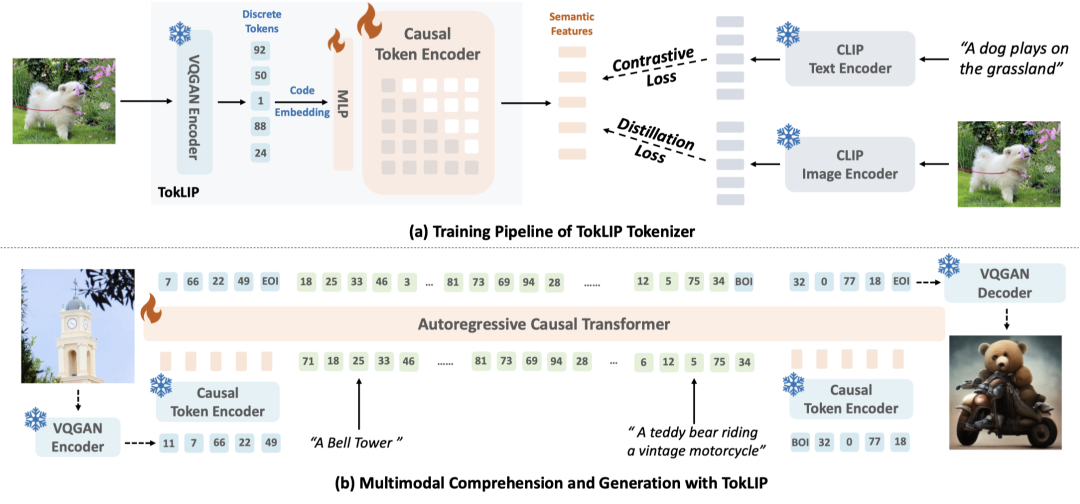
具体而言,图像先经过一个预先加载的VQGAN进行离散化编码,离散Tokens再通过一个MLP层被投影到CLIP初始化的ViT-based token encoder,得到高层语义特征,然后使用蒸馏和对比学习的损失函数优化MLP层和token encoder。
为了保证自回归生成任务的能力,研究人员使用了Causal的Token encoder,保证自回归生成图像过程不存在信息泄漏。
与以往将连续图像高层特征离散化训练的方案不同,TokLIP在训练过程中直接将语义注入到视觉token中,这种设计的好处在于:
不需要专门的重构损失来保证token的可逆性,避免了重构损失和语义监督的训练冲突,降低了训练复杂度; Freeze VQGAN的设计保留了生成能力和框架的灵活替换性,模型能够在训练过程中自适应地调整token的语义表达,使其既保留图像细节,又兼顾语义对齐; 继承预训练的CLIP权重,在相同算力资源下能够更快收敛,整个pipeline更加简洁高效,并取得更优的性能。
这种“轻量而统一”的训练范式,使TokLIP在兼顾理解与生成能力的同时,降低了训练优化难度和资源需求,而且可以随着VQGAN和CLIP的技术更迭得到进一步增强。
另外,训练得到的TokLIP在嵌入MLLM时,研究人员会将low-level的tokens和high-level的clip features进行concat后,送入MLLM进行自回归编码,这样的架构设计在增强视觉tokens语义的前提下,保证了离散化方案的统一理解生成能力。
实验效果
TokLIP基于预训练VQGAN,提供三种版本:TokLIP-B(256×256,VQGAN来自LlamaGen);TokLIP-L(384×384,同样来自LlamaGen);TokLIP-XL(512×512,采用IBQ,26万codebook)。
所有模型都使用16倍下采样,encoder初始化自SigLIP2,并通过两层MLP将VQGAN特征映射到语义空间,训练数据涵盖CapsFusion、CC12M、LAION-high-resolution,其中TokLIP-B额外加入LAION400M子集。
图像分类与图文检索任务
在图像分类与跨模态检索中,TokLIP超越了VILA-U、QLIP等离散语义方法,并超过了部分连续的视觉编码器,证明语义化VQ token的有效性。
更重要的是,TokLIP所需训练数据远少于同类方案,却依然取得领先性能,展现出一种轻量而高效的解决路径。

多模态理解任务
当TokLIP被接入多模态大语言模型(MLLM)时,其语义token能无缝嵌入现有的语言建模框架。
实验中,研究人员在常用的7个下游任务上进行了评估,结果表明:TokLIP在离散化方案中取得了很有竞争力的结构,证明了TokLIP能够提供带有语义信息的输入,使得MLLM在问答与推理时更加准确。

自回归图像生成任务
在自回归生成(AR Generation)任务上,TokLIP的语义化token在这一环节提供了语义信息,实验表明,TokLIP比仅使用VQGAN在不同训练设置下都取得了更低的FID效果,证明了语义信息可以帮助生成任务。

TokLIP通过创新性地将语义化VQ token与CLIP级语义对齐相结合,为离散tokens注入高层语义,有效提升了离散化方案的理解与生成的能力。
凭借独特的架构设计和高效的数据利用,TokLIP在分类、检索、MLLM理解及自回归生成等多模态任务中均展现出优异表现,为统一的理解与生成范式提供了一种轻量而高效的解决方案,也为未来多模态模型的发展开辟了新的方向。
目前,TokLIP的模型和训练代码已经开源,感兴趣的uu可以戳文末链接关注更多详情。
论文链接:https://arxiv.org/abs/2505.05422
代码链接:https://github.com/TencentARC/TokLIP
模型权重:https://huggingface.co/TencentARC/TokLIP
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟










