我们正处在一个关键的初期阶段:AI 正在加速驱动自身的研发,从而开启一个系统性的递归式改进循环。下文将为你揭示其运作的真实图景。
作者:埃里克·德雷克斯勒
日期:2025年8月26日
自动化常规任务,总能为世界拓展出新的可能性。
在自动微分技术诞生前,深度学习的研究者和工程师必须为每一个模型家族手动推导和实现梯度。这整个过程不仅耗时费力,还极易出错。
当 Theano 等工具将这项繁重的数学工作自动化之后,神经网络便从一个高度专业化的领域,转变为一门人人皆可上手的普及学科。
这一关键突破,与海量数据集、GPU 计算的力量相结合,共同点燃了深度学习的革命之火。
如今,我们看到,相似的进步正在整个机器学习技术栈中,从四面八方汇集而来,同时发生。
这并非通用人工智能(AGI)神话中,那种单一实体通过不断修改自己,最终进化成超级智能的所谓递归式自我改进。
它是一个更加宏大和真实的系统性过程。在这一过程中,各种专用工具在自动化常规任务的同时,也让过去遥不可及的新任务变得可行。
研究人员也越来越多地将这些工具巧妙地编排组合,以构建强大的自动化工作流。
我们当下的发展方向,正是迈向一个能够整合、编排各种零散超人能力的系统,并且这个系统的能力范围还在不断扩大。
展望未来,科研任务的全面自动化,已不再是能否实现的问题,而仅仅是何时到来的时间问题。
我们现在所目睹的一切,都还只是序章。在这个领域里,自动化本身,就是加速下一轮自动化的催化剂。
加速的真实结构
几十年来,人们对人工智能驱动自身进步的传统想象,是一个孤立的自我在进行提升,就像这样:
传统观点:

这种过于简单的看法,诞生于现代人工智能兴起之前。而今天的现实,其实更接近下图:
今日现实:
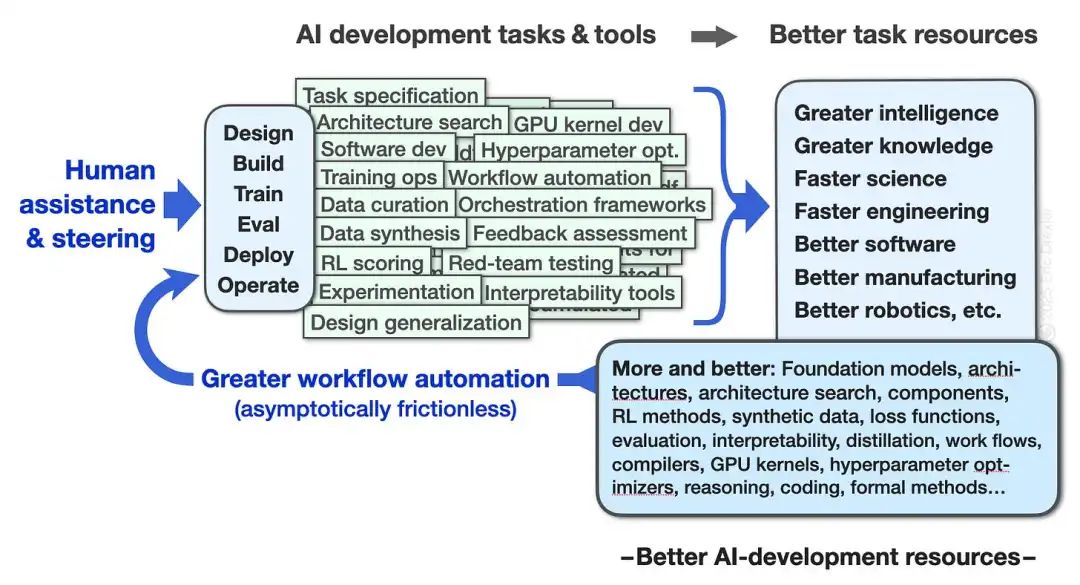
在这个分布式的 AI 研发流程中,人类的智慧和劳动,被日益强大的自动化工作流不断放大。
其根本的驱动机制,在于系统性地减少阻力。点滴的改进汇集成河,让研究的步伐更快,目标更远大,最终拓展了整个领域的可能性边界。^1
研发自动化的范围非常广阔。
一端是 AutoML 平台,它负责编排一系列常规流程:从数据质量评估,到模型选择,再到超参数调优和性能监控。这种从自动化单个任务到管理整个流程的演变,极大地降低了机器学习的应用门槛。
另一端,则是那些能够催生真正创新的前沿工具。例如,神经架构搜索可以为全新的模型构想,找到高效的实现方案。
新的 GPU 内核生成工具,则在不断降低底层优化的技术壁垒。正是这类优化(比如 FlashAttention),才使得许多新架构的大规模应用成为可能。
进步的模式,是能力的持续累积,而非一蹴而就的系统性飞跃,但这些看似微小的增量改进,却能产生惊人的复利效应。
以超参数优化为例,对比传统的网格搜索,先进的贝叶斯方法和多保真度方法,往往能将成本降低一个数量级。
过去需要数千次完整模型训练才能完成的工作,如今只需寥寥数次更智能的探索即可。当创新的成本不再令人望而生畏,研究的节奏自然会更快,视野也会更开阔。
递归的动态循环
一个有趣的现象是,那些用于加速 AI 研究的工具,其本身往往就是 AI 系统[^2]。而这些工具又反过来被它们所加速的研究成果所改进。
这种多渠道、有人类参与和协调的反馈,最终演化成一种系统性的递归式改进。
整个改进的循环非常复杂。在那些共通的瓶颈环节(如编程、数据准备、实验追踪、算力管理)取得的进步,会同时让多个研究领域受益,尽管受益程度各不相同。
更好的实验追踪,能帮助所有领域的研究者从过去的工作中汲取经验;更快的模型训练,让更多的实验探索成为可能。
而更高效的文献分析,则可能揭示出不同领域间的隐藏关联,在不经意间点燃突破性的灵感火花。整个科技平台就这样被参差不齐地、共同抬升了。
一旦我们认识到这个模式,一切似乎都理所当然:
当然,那些能减少研究阻力的工具,会加速 AI 研究,从而催生出更强大的工具。
当然,只解决单个瓶颈,带来的改变是有限的;而一旦所有瓶颈都被打破,一场革命便会到来。
而且,协调不同工具本身也是一项任务。整个系统的进步,并不依赖于任何单一工具的所谓通用性。通用性,本身也可以是整个系统涌现出的特性。
如今,一种集成度更高的通用性,正在类似人类的协作角色中发挥着巨大的杠杆作用。
这种能力体现在:理解任务并提出方案;审查结果并做出判断;理解工具并熟练使用它们。
我们不必将自回归的、基于文本训练的 Transformer 神化为无所不能的架构,但必须承认,最顶尖的语言模型确实提供了强大的通用接口,并展现出媲美人类的能力。
它们可以编程,使用工具,协助训练其他模型。最重要的是,它们能基于对世界和人类意图的丰富情境理解,来回应我们的请求。^3
当一个研发系统能够按需提供高度专业的工具时,我们把由此产生的这种人工智能资源,称为人工的、通用的、智能的,似乎再自然不过了。^4
战略层面的启示
这条通往全面人工智能能力的发展路径,使其未来的轮廓变得清晰可辨,即使我们无法预测每一个细节。
如果我们相信,人工智能终将能在所有技术领域追平甚至超越人类,那么,从文献回顾到提出假说,再到设计实验,整个科研任务的逐步自动化,就是一个必然的推论。
今天的每一步进展,都是在为这条终点日益清晰的道路铺设路基。
递归式自我改进的传统构想,虽然抓住了问题的本质,却完全误解了其实现机制。
超级智能的未来,并非源于某个单一智能体的闭门造车、自我完善;它将诞生于一个由无数能力模块构成的、精心编排的、不断消除整个研发体系阻力的庞大网络。
理解这一真实结构,将彻底改变我们发展人工智能的方式。
问题不再是 AI 是否会递归式改进——它早已在发生了,通过成千上万的工具,在成千上万的任务中,一点一滴地减少阻力。
真正关键的问题是:我们还要多久才能清醒地认识到这个正在发生的现实,并据此做出与未来真正可能性相匹配的明智选择?^5
我们必须先看清脚下的路,才能重新思考远方的目标。
[^1]: 指的是系统性进步中,各个环节相互依赖的关键特性。
[^2]: 一个例子是 AlphaFold。它借鉴了深度学习领域的思想,而它的成功又反过来为生物学领域的机器学习模型开发,提供了全新的思路。
[^3]: 语言模型所展现出的能力,其广度和深度似乎都超出了包括我自己在内的许多研究者的预期。
[^4]: 这与“通用人工智能”的概念形成了对比,后者通常被理解为一个在所有任务上都超越人类的单一系统。
[^5]: 这包括关于风险和治理的决策。这些决策必须建立在对当前及未来系统能力的现实评估之上。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










