点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:阿里巴巴达摩院
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

引言

在大模型时代,Scaling Law是成功的关键因素之一。通过大规模、多样化的数据训练,模型能够在不同领域、任务和场景中实现良好的泛化能力。无论是语言、2D图像还是语音,数据量的扩展在各自的识别领域都证明了这一点。然而,3D视觉领域尚未实现类似的进展,核心问题在于缺乏足够规模和多样化的数据。
我们的目标是利用互联网上海量、丰富的图片数据,填补3D数据的空缺,提出了一种自动化的“2D → 3D”转换流水线,将任何网络图片转化为具有深度、相机位姿和实例/语义标注的3D资产。这不仅为训练提供了充足的数据,也确保了数据的高质量和多样性,为模型的泛化能力打下坚实基础。
我们贡献了两个大规模3D数据集(COCO-3D和Objects365-v2-3D),并在多个任务中取得了显著提升。我们生成的高质量3D资产如下图所示。更重要的是,这一简单又有效的方法在零样本(zero-shot)感知任务中验证了其能力,为空间智能的 scale-up 开辟了新道路。
论文链接:https://www.arxiv.org/abs/2507.18678
项目主页:https://zhanggongjie.github.io/TowardsSSI-page/

背景与挑战
空间智能的时代
从自动驾驶车辆的三维环境感知,到家用服务机器人的室内导航,再到沉浸式 AR/VR 的环境交互,空间智能正成为 AI 的下一个制高点。然而,这些领域获取3D数据的方式有三种:
传感器采集:LiDAR/RGB-D 硬件成本高昂,场景限定且标注耗时,典型数据集规模仅数千至万级。
仿真模拟:游戏引擎生成可扩展,但物理与视觉细节不足,难以缩小“仿真到真实”的泛化鸿沟。
AI 生成:擅长单物体或卡通场景,却难以还原复杂真实环境和多物体布局。
2D 数据的未竟潜力
与此形成鲜明对比的是,COCO、Objects365 等海量 2D 图像数据集已推动 2D 视觉与多模态大模型革命。但它们在空间智能中的“价值挖掘”尚未启动——如何将零散的 2D 视图转换为具备度量尺度与真实纹理的 3D 场景,一直是行业亟待突破的核心命题。

核心创新:可扩展“2D→3D”数据管线
本工作提出的流水线,从单张 RGB 图像出发,直接生成度量真实的 3D 点云、相机参数与实例/语义标注,真正实现了大规模、低成本、高保真的 3D 数据合成。其关键技术亮点包括:

- 双重深度融合
运用 MoGe 相对深度模型细化局部几何结构,结合 Metric3Dv2 的绝对尺度估计,两者加权融合后校准,兼得几何精细度与全局尺度准确性。
同时恢复相机内参(焦距、主点)和外参(位姿朝向),通过两阶段网络分别拟合,让“任意网络图片”都能拥有精确投影能力,确保生成点云在标准坐标系中统一尺度与方向。
投影产生的彩色点云保留原图纹理;专门设计规则剔除天空、地平线等无效点,实现高信噪比的 3D 重建效果。
对于 COCO 这种带分割掩膜与检测框的数据集,我们直接映射生成 3D 实例分割与语义分割的标注;对于无mask标注的图像(如 Objects365),利用SAM和其2D Box标注,先在 2D 上生成分割掩膜,再映射得到 3D标注。
这套流水线首次走通了将海量 2D 资源转化为具备真实世界度量意义、可直接用于训练的 3D 数据的路径,跨越了稀缺的 3D 数据与大模型 scale-up 之间的鸿沟。此外,现有 2D 数据中大量的 caption 描述也可以被有效利用,助力 3D 模态的对齐与理解。

数据里程碑:百万级 COCO-3D & Objects365-v2-3D
基于该管线,论文发布了两个迄今规模最大的合成 3D 数据集:
COCO-3D:约 12 万场景、117 k 训练 + 5 k 验证,涵盖 80+ 类常见物体;
Objects365-v2-3D:接近 200 万场景、365 类物体,涵盖室内/室外多种应用场景。
与 ScanNet(1.5 k 场景)与 Matterport3D(90 个室内场景)相比,COCO-3D/Objects365-v2-3D 在数据量级上分别提升了两个数量级;涵盖的场景、物体类别的多样性更是远超现有的3D数据集,实现了从室内到户外各常见场景的全覆盖。
更重要的是,这些合成数据经过物理尺度验证:COCO-3D中 “人”的实例的高度区间与真实人体高度范围基本吻合;“椅子”“瓶子”等常见物体维度亦同理。由此,数据不仅丰富,更具备学术研究所需的度量可信度。


实验结果:从感知到推理的跨越式跃升
在一系列行业公认基准上的验证,充分证明本方法与数据集的学术价值:
- 3D 实例 & 语义分割
为了确保通用性和泛化性,我们采用了Uni3D作为骨干网络,并且没有依赖于特定领域的超参数调整(例如体素化网格大小、点的数量、学习率等)。在语义分割(semantic segmentation)任务中,我们使用了SpUNet、PTv2和Uni3D作为骨干网络,并通过两层MLP进行特征提取。在实例分割(instance segmentation)任务中,我们则使用了Mask3D作为实例分割的头部,从而保证了模型的通用性和跨任务的适应能力。
预训练于 COCO‑3D 后再微调 ScanNet:实例分割 mAP + 4pts、语义分割 mIoU +30%,如下表所示【表1–3】。 


Zero‑shot泛化:仅用COCO‑3D 训练即可在ScanNet、S3DIS、Matterport3D 上实现可用精度,对“厕所”“椅子”等类别的分割效果超 60% mAP,如下图所示。


2.3D refering segmentation
结合文本指令定位实例,仅用合成数据训练模型即可在真实 ScanNet 上完成目标引用,Fine‑tune 后准确率提升 6% 以上。

用 COCO‑3D 预训练的 3D 大模型,在 ScanQA 等任务上 BLEU‑4、CIDEr 均有显著增长,性能可媲美或超越 7B 参数级专用模型,如下表所示。 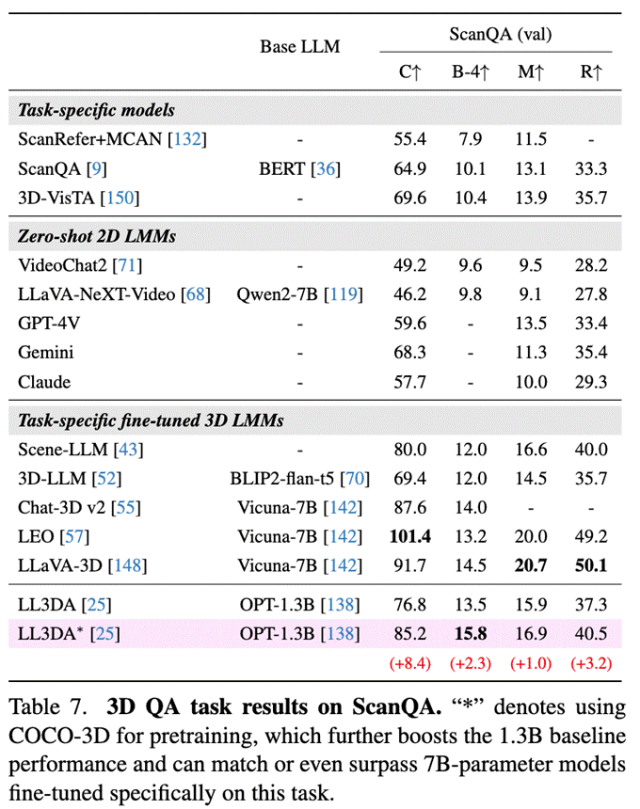
数据规模>模型规模的范式:中型模型在大规模合成数据上训练后,展现出前所未有的空间理解与推理能力。
这些结果表明,合成 3D 数据不仅能替代部分实测数据,还在多任务、多场景中提供了更强的泛化与鲁棒性。它为跨模态感知与推理提供了统一基础,打开了将视觉、几何与语言紧密耦合的新局面。

影响与展望
1.迈向 3D“ImageNet”
COCO-3D/Objects365-v2-3D的发布,意味着我们已经具备了百万量级、多类别、大场景的 3D 数据基座。这一规模将加速涌现空间智能模型的深度学习时代——就像 ImageNet 对 2D 视觉的意义,未来几年空间智能领域将涌现无数革新工作。
2.统一空间感知与语言推理
本工作将视觉感知与语言推理的数据需求集中到同一套合成数据上,为 3D 多模态大模型的发展铺平道路。研究者可在同一框架下探索从点云分割到语言交互的一体化方法,开启 AI 对 3D 世界的“概念化理解”与“语言化表达”。
3.机器人与 AR/VR 应用跃升
具备大规模现实纹理和度量真实性的合成 3D 场景数据,为机器人导航、抓取与环境交互提供了多样化训练场景,也为 AR/VR 场景理解与虚拟物体摆放提供了更真实的环境基底。应用端的模拟到现实闭环将更高效、更可控。
4.数据范式的根本变革
从硬件采集 → 仿真模拟 → AI 生成,再到2D图像“抬”升为 3D,学界迎来了全新一代数据生产范式。它让任何已有的 2D 图像资源,都可在几分钟内转化为具备学术与工程价值的 3D 数据,极大降低数据成本并消解领域壁垒。
笔者也注意到近期一些工作(如 MoGeV2、VGGT、π³)与我们的思路有相似之处:它们把“点图(point map)”作为核心监督或输出;而我们的路线是直接在数据侧合成含点图、深度与相机参数的完整标注,用合成数据把监督一次性做足。我们的数据合成框架可以融合近期优秀的工作合成更具高质量的数据。
3D视觉1V1论文辅导来啦!

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











