点击下方卡片,关注“大模型之心Tech”公众号
上海AI Lab又发力了!刚刚推出了开源多模态模型InternVL 3.5,在通用性、推理能力和推理效率方面显著推进了InternVL系列的发展!与前代产品相比,InternVL3.5系列通过我们提出的级联强化学习(Cascade RL)框架实现了更优的性能,该框架通过离线RL阶段实现稳定收敛,并通过在线RL阶段进行精细对齐。这种由粗到细的训练策略在下游推理任务(例如MMMU和MathVista)上带来了显著提升。为了优化效率,我们提出了一种视觉分辨率路由器(ViR),它能动态调整视觉标记的分辨率而不会损害性能。结合ViR,我们提出的解耦视觉-语言部署(DvD)方法将视觉和语言处理组织成一个异步的三阶段流水线,从而实现重叠执行并最大限度地减少流水线停顿。在一系列基准测试中,InternVL3.5在通用多模态能力、数学和多模态推理、文本理解、图形用户界面(GUI)代理、具身代理和真实世界理解任务上均取得了领先表现,显著缩小了与GPT-5等顶级商业模型的性能差距。我们相信,我们的开源模型和代码将推动多模态AI研究及其在现实世界中的应用。更多前沿大模型信息,欢迎加入大模型之心Tech知识星球~

代码链接:https://github.com/OpenGVLab/InternVL 模型链接:https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B

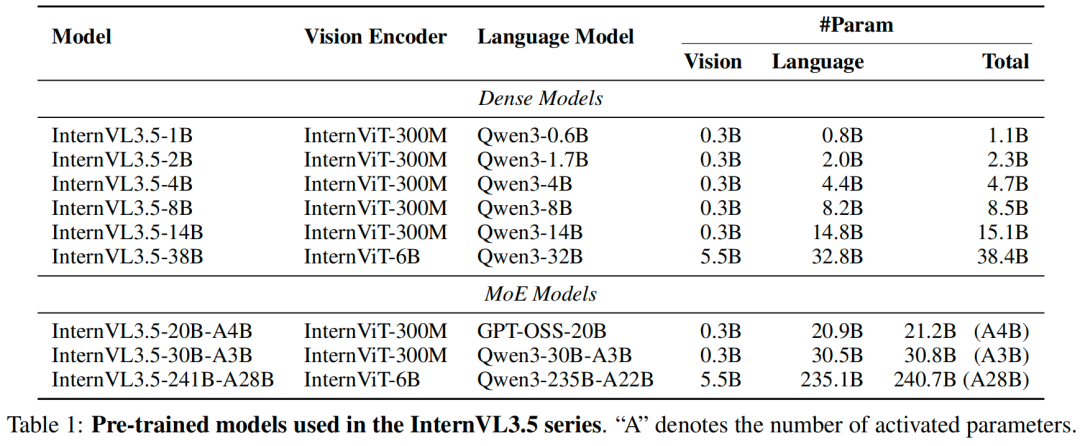
模型架构

InternVL3.5 的整体架构如图 2 所示,主要由三个核心组件构成:动态高分辨率文本分词器、InternViT 视觉编码器,以及一个连接视觉与语言模态的连接器。该模型采用两阶段训练范式,包括大规模的预训练阶段和多阶段的后训练阶段。在预训练阶段,模型通过联合优化文本和多模态语料库来学习通用的视觉-语言表示。在后训练阶段,我们采用三阶段策略:监督微调(SFT)、级联强化学习(Cascade RL)和视觉一致性学习(ViCO),以进一步提升模型的指令遵循、推理和视觉理解能力。
动态高分辨率文本分词器:我们采用 Qwen3 或 GPT-OSS 分词器,能够处理高达 32K 的上下文长度,以适应长文本理解与推理任务。 InternViT 视觉编码器:我们使用 InternViT-300M 或 InternViT-6B 作为视觉编码器,将输入图像或视频帧编码为一系列视觉标记(visual tokens)。 视觉-语言连接器:该连接器负责将视觉编码器输出的视觉标记与文本分词器生成的文本标记进行对齐和融合,从而实现跨模态信息的交互。
预训练
训练目标:在预训练阶段,我们联合更新模型的所有参数,使用大规模的文本和多模态语料库进行训练。具体而言,给定一个由多模态标记序列 组成的任意训练样本,我们对每个文本标记计算下一个标记预测(Next Token Prediction, NTP)损失:
其中 是要预测的标记,前缀标记 可以是文本标记,也可以是图像标记。
数据:预训练语料库可分为两类:(1) 多模态数据:主要来源于 InternVL3 的训练语料库,涵盖图像描述、通用问答、数学、科学学科、图表、光学字符识别(OCR)、知识接地、文档理解、多轮对话和医学数据等多个领域;(2) 纯文本数据:基于 InternLM 系列 的训练语料库构建,并进一步增广了开源数据集。预训练语料库包含约 1.16 亿个样本,对应约 2500 亿个标记。纯文本数据与多模态数据的比例约为 1:2.5。最大序列长度设置为 32K 标记,以适应长上下文理解与推理。
后训练
在预训练阶段之后,我们采用三阶段的后训练策略:
监督微调(Supervised Fine-Tuning, SFT):该阶段保持与预训练相同的训练目标,但利用更高品质的对话数据来进一步增强模型的能力。与 InternVL3 相比,InternVL3.5 的 SFT 阶段包含了更多高质量和多样化的训练数据,来源包括:(1) 来自 InternVL3 的指令遵循数据,用于保留对各种视觉-语言任务的广泛覆盖;(2) 处于“思考”模式下的多模态推理数据,用于赋予模型长链推理能力。这些数据通过大规模推理模型采样生成,包含详细的推理过程。我们不仅验证答案的事实正确性,还对推理过程本身实施严格的过滤措施,包括评估推理的清晰度、剔除冗余信息以及确保格式一致性。这些问题覆盖数学和科学等多个专业领域,从而强化模型在不同推理任务上的表现。
级联强化学习(Cascade Reinforcement Learning, Cascade RL):该方法结合了离线和在线强化学习的优点,以促进模型的推理能力。离线强化学习算法(如 DPO)基于现有生成结果进行训练,效率较高,但性能上限通常低于在线强化学习方法。相比之下,在线强化学习算法(如 PPO)通过与环境的交互进行探索,能有效提升性能,但训练成本高昂且不稳定。为解决此问题,我们提出 Cascade RL,其包含一个离线阶段和一个在线阶段。离线阶段作为有效的预热,确保后续在线阶段生成高质量的推理路径,从而实现模型推理能力的渐进式提升。实践中,Cascade RL 表现出良好的可扩展性和稳定性(如图 5 所示)。
级联强化学习的目标函数(LGSPO)定义如下:
其中重要性采样比率 定义为每个标记比率的几何平均:

这里 $\pi_\theta(y_i \mid x, y_{i,<t})$ 和="" $\pi_\theta(y_{i,t}="" \mid="" x,="" y_{i,<t})$="" 分别表示在策略模型参数为="" $\theta$="" 时,生成完整响应="" $y_i$="" 和单个标记="" $y_{i,t}$="" 的概率。<="" p="">
视觉一致性学习(Visual Consistency Learning, ViCO):该方法旨在将视觉分辨率路由器(Visual Resolution Router, ViR)集成到 InternVL3.5 中。ViR 主要由 OCR 和 VQA 示例构成,富含视觉信息,有时需要高分辨率理解。这使得分辨率路由器能够学习如何根据视觉信息动态决定每个图像块是否可以被压缩。
测试时扩展
测试时扩展(Test-time scaling, TTS)已被实证证明是一种有效的方法,可增强大语言模型(LLMs)和多模态大语言模型(MLLMs)的推理能力,尤其适用于需要多步推理的复杂任务。在本研究中,我们实现了一种全面的测试时扩展方法,该方法同时提升了推理的深度(即“深度思考”)和广度(即“并行思考”)。需要注意的是,除非另有说明,第3节中报告的实验结果均未应用TTS。目前,我们仅将TTS应用于推理基准测试,因为我们发现模型在感知和理解能力方面已表现出色,而启动TTS并未带来显著提升。
深度思考(Deep Thinking):通过激活“思考”模式,我们引导模型在生成最终答案之前,有意识地进行逐步推理(即将复杂问题分解为逻辑步骤,并验证中间结论)。这种方法系统性地改善了复杂问题(尤其是需要多步推理的问题)解决方案的逻辑结构,并增强了推理深度。
并行思考(Parallel Thinking):沿用InternVL3的方法,对于推理任务,我们采用Best-of-N(BoN)策略,使用VisualPRM-v1.1作为评判模型,从多个推理候选中选择最优响应。这种方法提升了推理的广度。
基础设施
训练框架:模型训练主要基于 XTuner 框架进行。
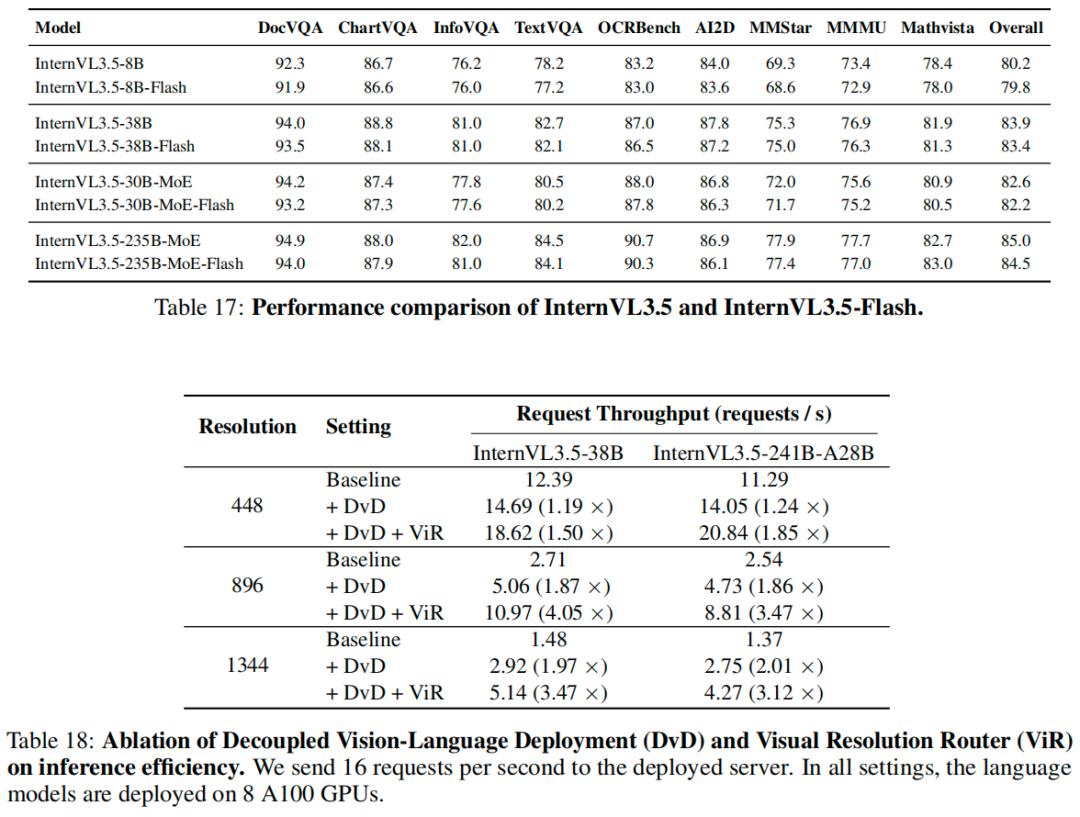
解耦的视觉-语言部署(Decoupled Vision-Language Deployment, DvD):在大规模在线部署多模态大语言模型(MLLMs)时,视觉和语言模型常常相互阻塞,导致额外的推理开销。为解决此问题,我们提出 DvD 框架。该框架通过将视觉编码和语言解码过程解耦,实现了视觉和语言模块的硬件成本优化,并促进了新模块的无缝集成,而无需修改语言服务器的部署。

实验结果
与其他多模态大模型的综合对比

多模态推理与数学

OCR, Chart, and Document Understanding

多图理解和真实世界理解

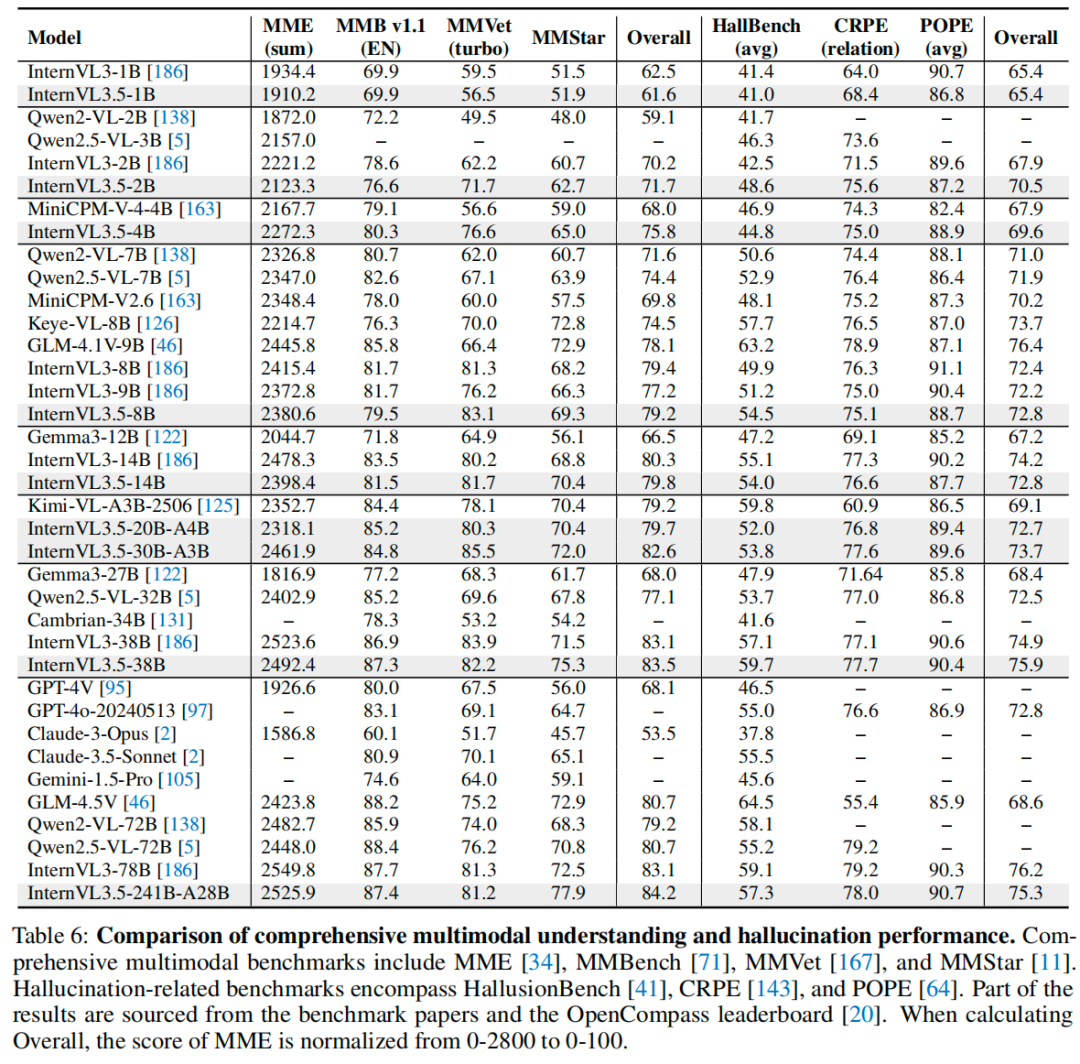
综合多模态理解和幻觉评测
visual grounding

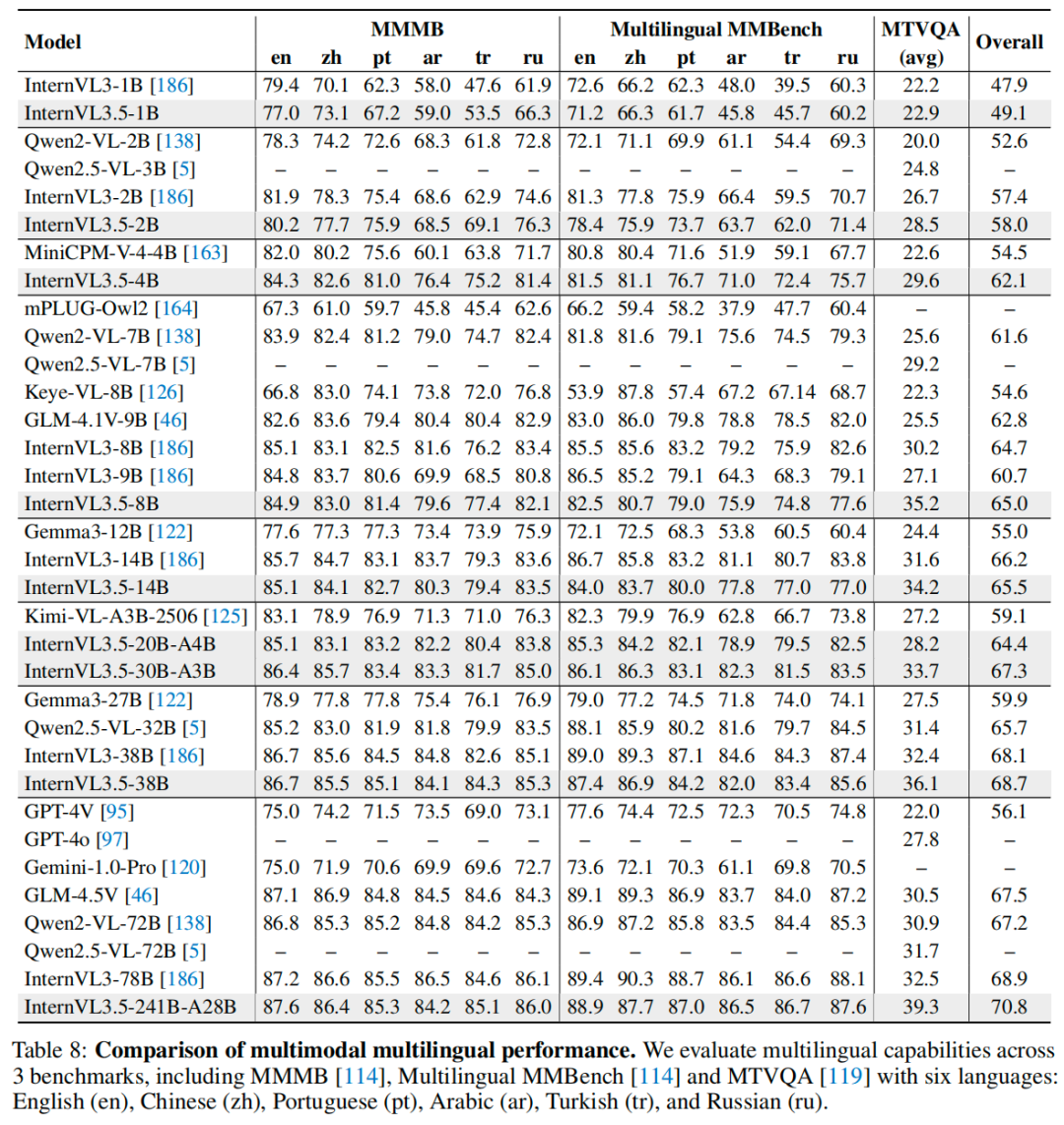
多模态多语言理解
视频理解

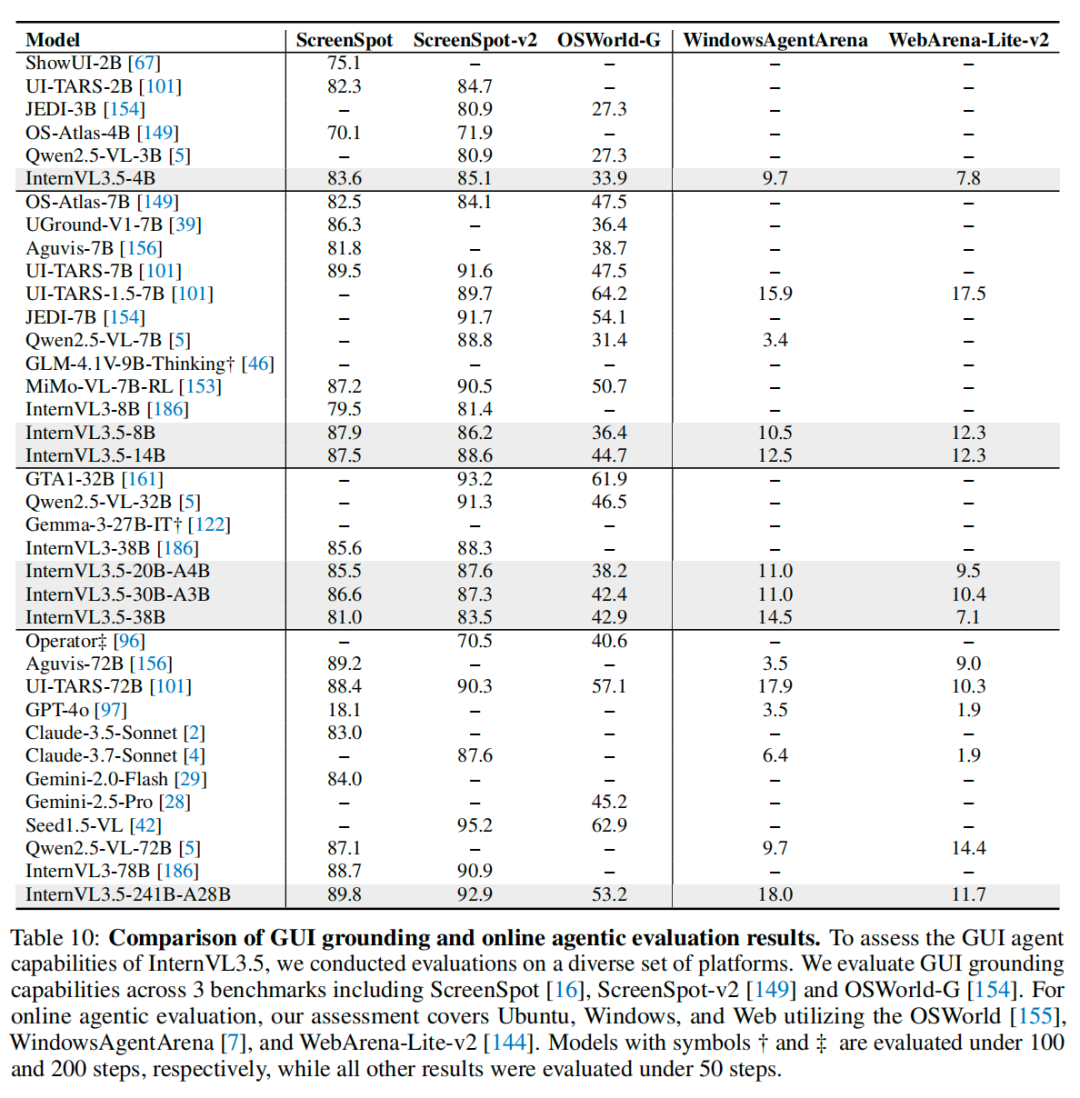
GUI Agent Tasks
具身智能体任务

SVG任务


消融实验



结论
在本研究中,我们推出了InternVL3.5,这是InternVL系列的最新一代模型,展现了在广泛任务上更强的通用性能和更快的处理速度。InternVL3.5采用了一种新的强化学习(Reinforcement Learning, RL)框架,即级联强化学习(Cascade RL),该框架结合了离线和在线RL方法的优势,以提升模型的推理能力。此外,我们还引入了两种新技术来降低InternVL3.5的推理成本,分别是视觉分辨率路由器(Visual Resolution Router, ViR)和解耦的视觉-语言部署(Decoupled Vision-Language Deployment, DvD)。得益于这些创新,与InternVL3相比,InternVL3.5在整体推理性能上提升了+16.0%,推理效率提高了4.05倍。此外,InternVL3.5在多功能性方面相较于InternVL3也有显著提升。具体而言,InternVL3.5-241B-A28B在主流开源多模态大语言模型(MLLMs)中,于多模态通用、推理、文本和智能体任务的综合得分上达到了最高水平,显著缩小了与GPT-5等顶级商业模型之间的性能差距。我们相信,我们的开源模型和代码将推动多模态人工智能的研究及其在现实世界中的应用。
更多前沿大模型信息,欢迎加入大模型之心Tech知识星球~