公众号记得加星标⭐️,第一时间看推送不会错过。

昨日,我们分享了Hot chips2025首日的重磅分享,详情可参考文章《一文看遍热门芯片》。到今天,来自英伟达、Ayar Labs、Lightmatter 、Celestial等传统巨头和新贵做光芯片上也做了详细的分享。我们整合如下,以飨读者。
英伟达的CPO光学器件
这是 Hot Chips 2025 大会上令人兴奋的一个环节。我们听到了 Gilad 关于千兆级共封装硅光子交换机的演讲。
在演讲中,NVIDIA 首先讨论了共封装光子学的需求,以及它如何显著提升 AI 工厂的规模。该公司提到,与传统的云数据中心相比,AI 工厂的光功率消耗大约是其 17 倍,这主要是因为 GPU 集群的增加需要数十个光收发器来与其他 GPU 通信。因此,仅网络光子学的成本就占 AI 工厂总计算能力的 10% 左右,而 NVIDIA 计划通过 Spectrum-X 以太网光子学技术来降低这一巨大的成本。

NVIDIA 将数据中心视为计算机,而不是单个 GPU。

BlueField-3 DPU 被设计为接入网络的 NIC。

人工智能需要零抖动通信,因为它们规模庞大、复杂,而且跨越很远的距离。

以太网架构有很多种。虽然它们都是以太网,但其要求和目标却各不相同。

NVIDIA Spectrum-X 以太网旨在允许大型 GPU 集群使用以太网。
据介绍,Spectrum-X 以太网光子学是一种独特的实施方案,据称是首个采用 200 G/通道 SerDes 的技术,这是电信号传输领域的尖端标准。与可插拔收发器相比,Spectrum-X 光子学具有更好的信号完整性和更低的 DSP 要求,因为在该实施方案中,光子引擎 (PIC) 紧邻交换机 ASIC。这意味着无需较长的 PCB 走线,激光器数量也大幅减少。例如,1.6 Tb/s 链路的激光器数量从 8 个减少到 2 个,这意味着更低的功耗和更高的传输可靠性。

Spectrum-X 旨在为 AI 工作负载提供低抖动通信。AI 网络中的抖动会导致 GPU 在大量 GPU 之间处于空闲状态。这不仅效率低下,而且 GPU 空闲成本高昂。NVIDIA 正在端到端设计这一设计,以便所有功能不再仅仅集中在交换机上。

Spectrum-X 提供更高的 NCCL 性能。NVIDIA 希望确保大型基础设施上同时执行多个作业时,它们不会相互干扰。例如,如果一台交换机上有一项作业,但同时还有其他作业,则您肯定不希望这些作业干扰其他作业的性能。

这是今年的新产品,表明 Spectrum-X 对于混合专家模型的调度性能比标准以太网更好。

以下是 Spectrum-X 对多租户数据中心的影响。

NVIDIA 的硅光子解决方案采用硅光子 CPO 芯片,传输速率高达 1.6T。该解决方案集成了 MRM(微环调制器),可提供更高的带宽,同时降低功耗和占用空间。更重要的是,NVIDIA Photonics 率先在光子层和电子层之间采用 3D 堆叠技术,从而降低了布线复杂性并提高了带宽密度。Green 团队与台积电在硅光子领域展开合作,因为这家台湾巨头是满足光子学需求的首选。
据称,数据中心采用的 NVIDIA 光子技术相比光学标准,其能效提高了 3.5 倍,弹性提高了 10 倍,运行时间提高了 1.3 倍。这表明,一旦光子技术成为主流互连,AI 计算将获得巨大的发展。该公司还展示了其首款集成光子技术的全尺寸交换机 Spectrum-6 102T,这将是 Team Green 的旗舰产品。以下是它的主要功能:
2倍吞吐量
63倍信号完整性
激光器数量减少 4 倍
1.6倍带宽密度
激光可靠性提高 13 倍
取代 64 个独立的收发器
以下是 Spectrum-X 以太网与现成的(Broadcom)以太网的不同之处的摘要幻灯片。

由于光纤网络元件会消耗大量电力,因此扩展也成为一个挑战。

这是下一代 Spectrum-X 以太网光子技术。它无需耗费电力来连接可插拔的光学引擎,从而节省了大量电力。

NVIDIA Photonics 是一款 1.6T CPO 芯片,配备新型微环调制器。NVIDIA 也专注于可拆卸光纤连接器。您可能在图片中看到,Spectrum-X 和 Quantum-X 的 CPO 连接方式有所不同。这是由于解决方案的演进。

实现此功能需要许多组件的配合。需要注意的是,本设计中有一个可插拔激光器。

NVIDIA 展示了其在现场运行的功能。

NVIDIA 有一个 102T 交换机,即集成硅光子学的 Spectrum-6 102T 交换机。

这样,可靠性就会上升,但功率会下降。

NVIDIA 拥有 Quantum-X 和 Spectrum-X 交换机,并且即将推出 CPO。需要说明的是,我将在未来尝试更详细地探讨这些交换机。

纵向扩展、横向扩展,现在又到了横向扩展。如果要扩展到数据中心之外,你不仅需要拥有高质量的网络,还需要极快的速度。

Spectrum-XGS 是该公司将横向扩展网络扩展至横向扩展的方法。这意味着现在不仅需要硬件,还需要距离感知算法。

NVIDIA 表示,使用该技术可以使横向扩展性能提高 1.9 倍,并且还有进一步提升的空间。

这是一项大规模运行的训练工作。

目标是允许多站点 AI 训练,以便训练不受单个站点的能力和资源的限制。

跨规模网络的起始距离约为500米。超过500米后,需要调整算法以适应距离变化。我迫不及待地想看到这些产品面世。如果我用几句话来概括上述技术,NVIDIA Photonics 旨在降低功耗,确保更轻松地扩展,更重要的是,通过利用光子的能量来加速互连过程。共封装硅光学器件支持在 ISO 功率下将 GPU 性能提高 3 倍,并将激光器总数减少约 4 倍,这意味着您的大量功率将从网络转移到实际的板载 GPU 集群,从而提高性能。
有关英伟达的CPO更多介绍,请参考我们此前的文章《英伟达CPO,路线图披露》。
Celestial AI的光子Fabric模组
在 Hot Chips 2025 大会上,我们有机会看到 Celestial AI 的光子结构链路。这项技术能够利用光连接下一代海量 GPU 和加速器的芯片,取代目前使用的电连接。

Celestial 的想法不仅仅是进行共同封装光学器件,而是将其带入具有正确封装和散热的大型 GPU。

目前重点关注的是下方带有中介层的HBM。Celestial AI PFLink拥有一个包含无源和有源元件的硅光子层。Celestial将SerDes与通道匹配,以实现极高的能效。该公司还在构建自己的光学MAC(OMAC),以实现RAS功能。

该公司使用的调制技术与其他公司不同。我们之前看到过很多环形调制器。从热学角度来看,EAM被认为更好。

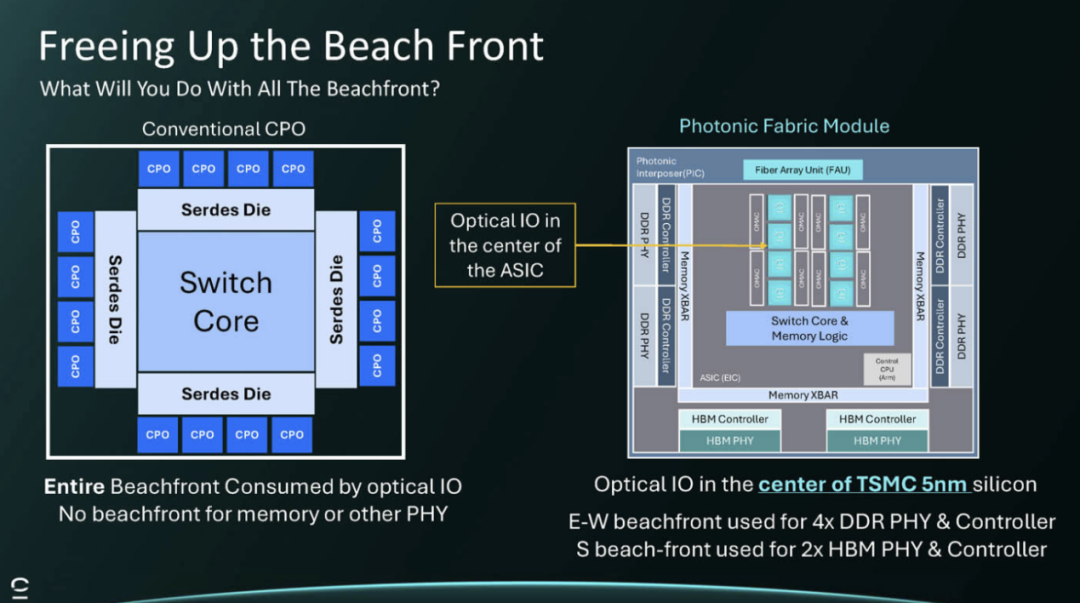
带宽和计算带宽的扩展速度并不相同。随着多芯片封装尺寸的增大,封装外 I/O 的周长空间呈线性增长,但面积却是平方的。

这是有关beachfront优势的幻灯片,它可能会影响芯片中缓存的构建和使用方式。

它的一个用途是进行package to package的互连。

我们的想法是,这种光子技术可以释放前沿阵地。传统的CPO更像是博通的CPO交换机模型。而有了Celestial AI,光I/O可以发生在ASIC的中心。然后,芯片的其余部分可以用于电气I/O,例如HBM。
这是 CoWoS-L 芯片组的样子,该芯片组包含 EIC、OIMB 和光学多芯片互连桥。在制造过程中,仅仅保证光学接口的安全就是一项挑战,因此 Celestial AI 表示他们拥有解决封装问题的技术。

在光子结构模块 Gen1 中,它被用于带有交换机连接内存的 16 端口交换机中。

这里有一些关于模块和设备的清晰统计数据。

该公司已完成四次流片。

这是封装。

Ayar Labs UCIe 光学 IO 重定时器亮相
Ayar Labs 在 Hot Chips 2025 上展示了一款 UCIe 光纤 I/O 重定时器,其基本思路是制作一个 UCIe 芯片组,使其能够轻松地将光纤 I/O 集成到封装中,因为它是基于标准的。由于该芯片组是 8Tbps 级设备,因此它还能提供大量的封装外带宽。

当今最大的挑战之一是,如何从数千个芯片连接成一个大型集群,扩展到数百万个芯片的规模。这使得互连变得至关重要。这主要发生在人工智能领域。

一个巨大的挑战是每个机架的功率密度。

Ayar Labs 有一个光学 I/O 芯片,可帮助使用光学技术进行横向扩展。

这是 Ayar Labs TeraPHY 光学 I/O 芯片和 SuperNova 光源。

该公司拥有一款UCIe光学I/O芯片。UCIe是一种基于标准的方式,企业可以根据通用规范构建软件包,以便于集成。

UCIe chiplet 的组织方式如下。
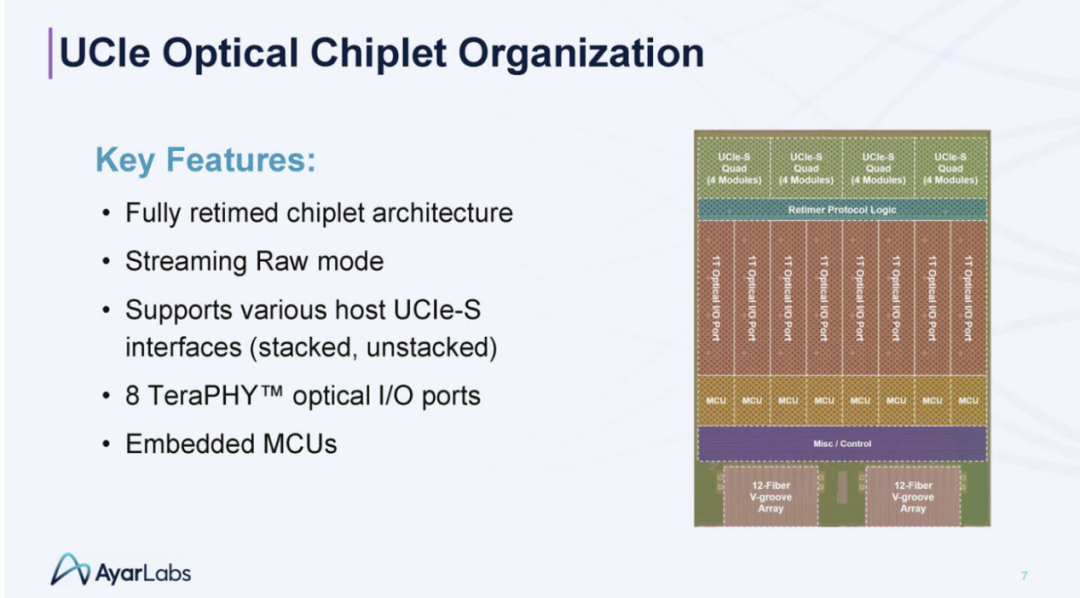
架构如下:

有了UCIe接收器,数据会被重新定时,然后进入光端。这有助于解耦光信号和电信号传输的挑战。

这是端口架构。

我们已经关注Ayar Labs很多年了。现在他们的chiplet速度已经达到了8Tbps,而且看起来更加精良。

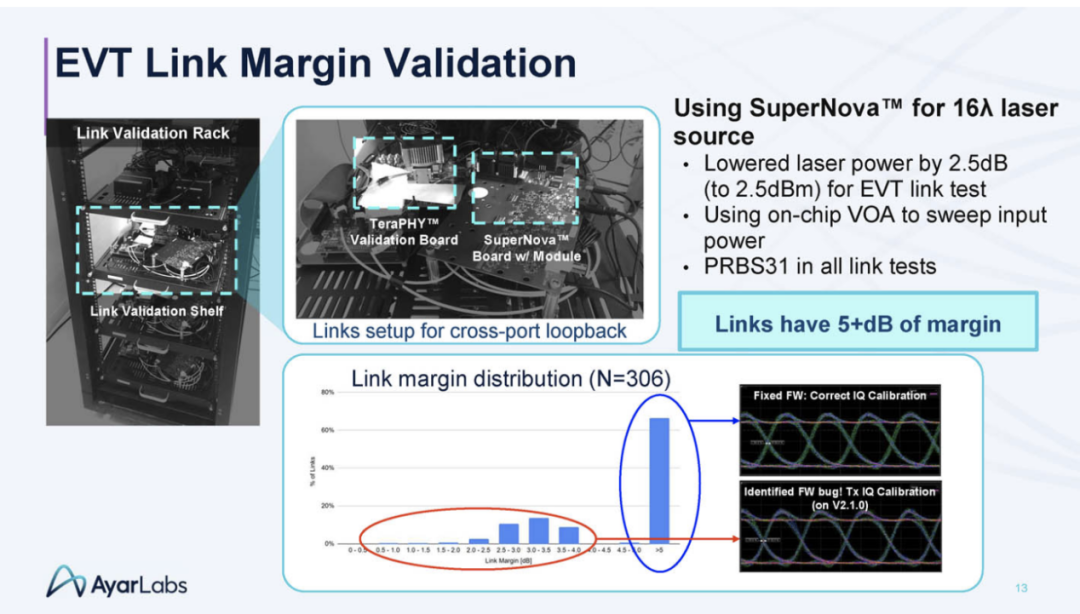
以下是 UCIe 链接测试结果:

以下是链接边距验证:
该公司还正在测试长期链路稳定性。

这是热循环。这很重要,因为芯片加热和冷却会导致材料膨胀和收缩,这实际上会改变光在通道中的传播方式。

这是一款一体封装的 500W 设备。这更像是现代 CPU 的 TDP,而不是如今通常是 2-3 倍的 AI 加速器的 TDP。

这是一个模拟热斜坡测试:

这是端到端链路设置。Ayar Labs 表示,虽然他们在这里展示的是 EVT,但他们现在已进入 DVT 阶段,即将实现量产。

这是进行端到端测试的 10 小时链路测试结果。

这个想法是,使用光学 I/O,互连可以增长,因此系统可以比使用电气 I/O 时变得更大。

最后,他们做了一个总结。

有了UCIe,这很有意思。同时,如果现在还不能大规模生产,我们明年购买的芯片中也不太可能看到它。尽管如此,业界对电气I/O的需求依然巨大,一个非常有效的方法就是使用UCIe对芯片进行标准化,使其更容易被集成到封装中。
Lightmatter Passage M1000 亮相
在 2022 年的 Hot Chips 34 大会上,Lightmatter介绍了Passage,它将共封装光学器件和硅光子技术带入了 Chiplet 时代。三年后,他们推出了 Passage M1000。

按照他们观察,计算的扩展速度比互连的速度更快。
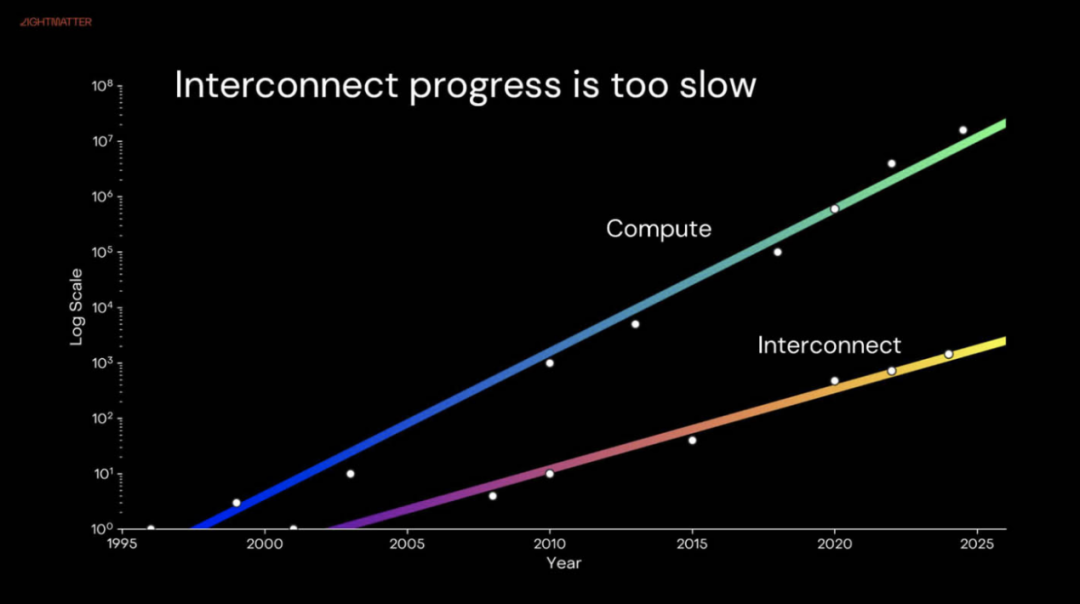
最大的挑战之一是芯片外围存在用于片外 I/O 的边界。这种物理区域限制限制了 I/O 的执行量。

Lightmatter 正在探讨将硅光子技术更贴近芯片的优势。第一代硅光子技术将类似于英特尔硅光子 100GbE QSFP28 500m 光纤。

Lightmatter 的新解决方案是 Passage M1000。

这个想法是,可以在 Passage 光学中介层上封装计算和内存芯片。

新设计承诺最高可达 114Tbps,即每个方向 57Tbps。

采用 3D 堆叠芯片后,光发射器/接收器需要紧凑。GPU 芯片连接到 SerDes,而 SerDes 又连接到 Passage M1000 的光端。挑战在于,您需要让光学元件与电 SerDes 的物理尺寸相匹配,以便在整个封装中保持密度。
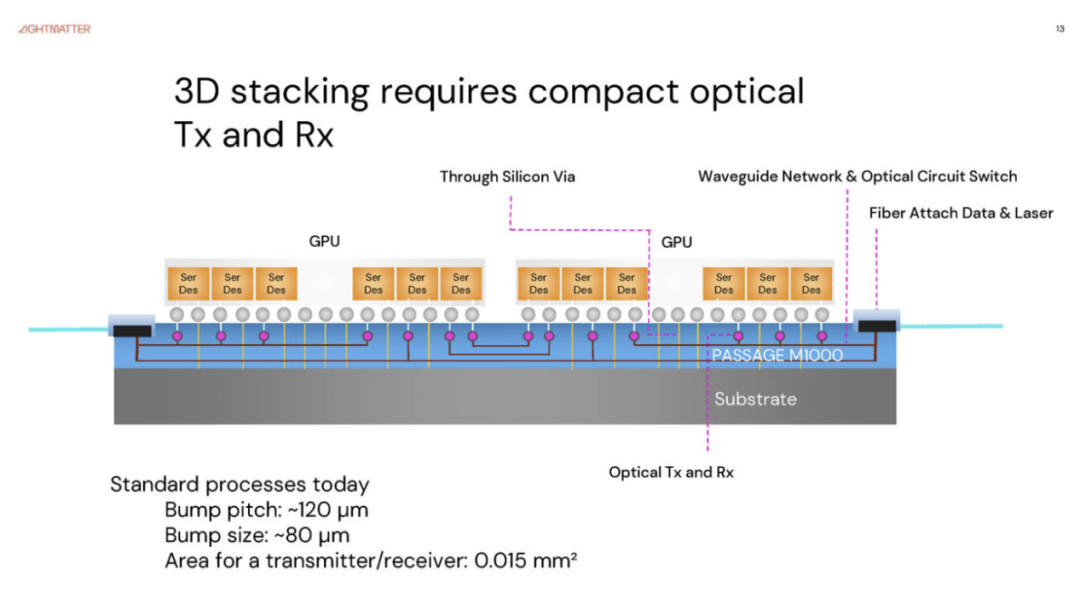
Lightmatter 使用硅微环来调节光。

这些微环可实现非常紧凑的光学 I/O。

这很有趣。Lightmatter 正在演示为什么微环是最好的。Celestial AI两次演讲前也发布过类似的图表,解释了为什么使用 EAM。

Lightmatter 有自己的 16 种波长激光,称为Lightmatter 指南。

Lightmatter 有一个参考平台。

这是顶部配有CoolIT液体冷却器的 Passage M1000 的外观。

这是晶圆上芯片组装后的样子。

这是彩色版本。

Passage M1000 还具有一定的可重构性。

这里详细介绍了具有 16 条水平总线的块设计以及它们如何连接到片外链路。
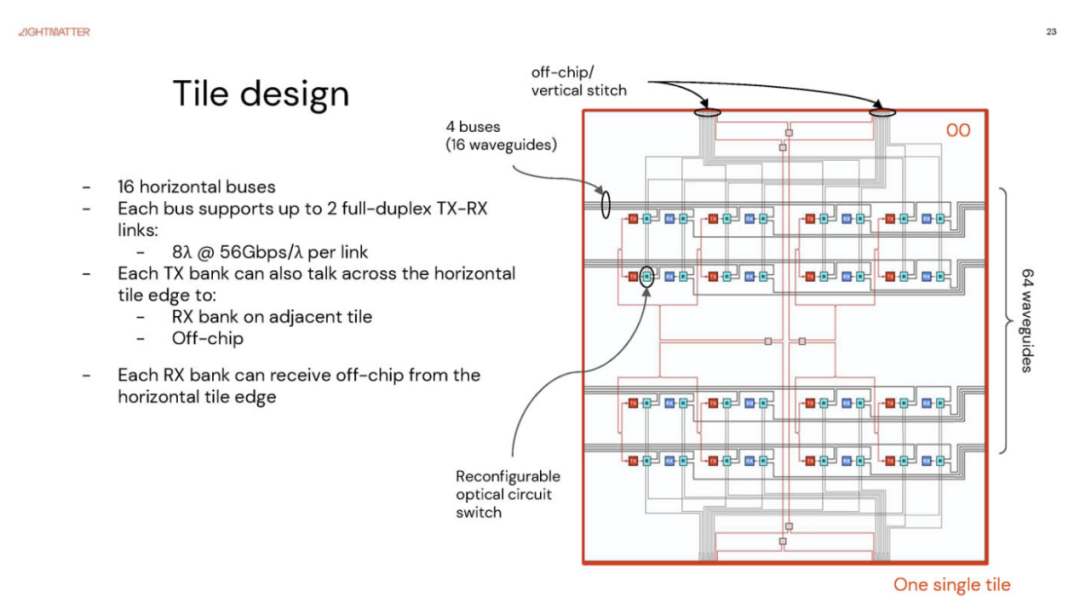
这是用于电气连接的十字形金属缝线。

Lightmatter 表示,它具有光路交换功能,可以实现冗余。

这是一个施加了功率和热负荷的测试台。

这是该设备的顶视图。

这是参考设备正面的 16 个光纤连接器。

这是两者连接在一起的样子。

中介层平台上启用了大量带宽。

M1000 是迈向拥有超过 200Tbps 的 XPU 和超过 400Tbps 带宽交换机的第一步。仅供参考,高端的博通 Tomahawk 6 是一款 102.4T 的交换芯片。

Lightmatter 表示其已做好生产准备。

让我们再看看它可能是什么样子。

我一直认为Lightmatter的平台非常出色。对我来说,最大的问题不在于这个想法是否好。我更大的问题是它什么时候才能真正投入使用。该公司表示,它将在今年的SC25大会上进行公开演示。
One more thing
其实关于“光芯片”,并不仅仅是上述企业,例如本土公司曦智科技就联合燧原科技推出国内首款xPU-CPO光电共封芯片,具体可参考文章《GPU CPO,国内首创》。
近日,数据中心互连设计和制造初创公司OpenLight Photonics Inc.表示,在从母公司 Synopsys Inc. 分拆并完成 3400 万美元 A 轮融资后,它希望加速向硅光子学的过渡。
OpenLight 的目标是成为硅光子学设计和制造领域的关键参与者,硅光子学是一种新型数据中心互连技术,用于连接数千个图形处理单元和其他类型芯片的集群,为人工智能和高性能计算工作负载提供动力。
硅光子技术可以解决一个紧迫的瓶颈:人工智能的处理能力不再受制于计算能力的限制,而是连接能力。当今最先进的人工智能模型由庞大的GPU集群驱动,这需要它们能够快速地相互通信。但它们无法跟上这种速度,因此新的瓶颈就在这里。根据Xscape Photonics去年的一项研究 ,由于网络限制,大多数人工智能开发人员只能利用大约25%的GPU容量。
问题在于,大多数现有数据中心依赖于电子互连,但这些 互连的吞吐量不足以跟上当今最强大的处理器。因此,GPU 经常处于空闲状态,需要等待其他处理器的消息才能进行下一个计算,从而减慢了 AI 的响应速度。硅光子技术摒弃了电子信号,而是依靠光的操控,以更快的速度在芯片之间传输数据。
OpenLight 设计并构建了所谓的光子专用集成电路 (PASIC),为这些新型光互连提供动力。PASIC 可以被认为是专用集成电路 (ASIC) 的光子等效物,而专用集成电路 (ASIC) 是当今大多数电子设备和计算机运行的核心,能够优化性能、成本和效率。OpenLight 相信其 PASIC 将成为下一代数据中心互连的核心推动者,但它们也可以用于其他应用,例如电信、汽车和工业传感以及量子计算。
首席执行官亚当·卡特 (Adam Carter) 告诉 SiliconANGLE,PASIC 可以帮助使现有的基于光子学的互连速度比目前快得多。
他解释说:“传统硅光子学的性能上限约为每波导 200 Gbps,但 OpenLight 的异构集成,尤其是与磷化铟的集成,使得高性能 200G 和 400G 调制器能够直接内置到芯片中。这实现了高密度、可扩展的光互连,功耗更低,带宽更高,这对于 AI 工作负载至关重要。”
Carter 表示,这家初创公司专注于设计和构建 PASIC,并提供三种不同的服务, 包括设计服务。设计服务与客户合作,根据客户的具体用例需求创建定制的 PASIC。此外,OpenLight 还通过其工艺设计套件 (PDK) 提供设计支持,使客户能够设计自己的 PASIC。OpenLight 的 PDK 基于磷化铟和硅光子学的异构集成,并提供涵盖集成激光器、放大器、调制器和探测器的广泛的有源和无源组件库。
设计完成后,OpenLight 便可与 Tower Semiconductor Inc. 合作,为客户生产实体 PASIC。Tower Semiconductor 已验证其 PDK,以确保每个设计都已准备好投入生产。换句话说,这家初创公司允许客户使用经过验证的构建模块快速设计和构建 PASIC,从而加快产品上市时间。
卡特解释说,能够定制其 PASIC 是一个关键的区别因素和强大的优势,因为每个客户和应用对所使用的单个组件(例如激光器、调制器和半导体放大器)都有非常特殊的要求。
“OpenLight 并非打造一刀切的芯片。相反,我们提供强大且可立即投入生产的 PDK 以及硅和磷化铟组件库,使客户能够设计自己的 PASIC,并根据其特定应用进行量身定制,”Carter 说道。“我们的客户购买的不仅仅是芯片;他们还构建了一套工具包,并拥有构建自身芯片的灵活性。这种敏捷性在快速发展的市场中尤为重要,因为标准仍在形成中(例如 CPO),它使客户能够比使用现成的解决方案更快地进行创新和差异化。”
卡特表示,OpenLight 的客户涵盖半导体公司、网络设备制造商、系统集成商和超大规模数据中心运营商。“我们还为激光雷达、高速计算、工业传感和量子计算等相关市场的客户提供支持,”他说道。“我们的首批客户将于 2025 年底开始生产,并在 2026 年为 OpenLight 带来首笔专利费收入。预计届时将发布公告。”
这轮早期融资是在 OpenLight 从芯片设计公司新思科技 (Synopsys)的子公司转型为独立公司几周后进行的。OpenLight 表示,目前已准备好满足人工智能数据中心对更快、更高效数据传输日益增长的需求。Carter 表示,OpenLight 受益的不仅仅是这笔资金,还有投资者的专业知识。他指出,投资者在半导体行业根基深厚,这些人脉将有助于 OpenLight 围绕其技术打造一个可行的生态系统。
他表示:“这笔资金将使我们能够扩大业务规模,深化研发力度,并更快地将突破性产品推向市场。我们相信,异构集成硅光子技术将彻底改变数据的处理和传输方式,我们很高兴能够站在这场革命的前沿。”
OpenLight 计划扩展其 PDK 库中的有源和无源元件数量,并计划为客户提供速度更快、传输速率高达每秒 400 GB 的调制器和更先进的片上激光技术。Carter 表示,目标是为客户提供业内最灵活的元件设计库。同时,他还计划扩大公司团队规模,以支持早期采用者逐步实现 PASIC 的量产。
Capricorn 管理合伙人 Dipender Saluja 表示有信心,由于 AI 模型对数据的需求不断增加,以及人们持续希望降低基础设施成本,光互连的快速采用是不可避免的。
他表示:“OpenLight 的异构架构在性能、可靠性和成本这三个方面均表现出色,而这些方面此前一直阻碍着光互连的普及。OpenLight 所建立的强大代工厂关系和 PDK 为满足下一代 AI 硬件的大规模需求创造了理想的机会。”
让我共同期待光时代的到来。
如有硅光流片需求,
欢迎扫码,将有专人对接。

*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4138期内容,欢迎关注。
推荐阅读

加星标⭐️第一时间看推送,小号防走丢













