8月28日晚上,由DISCOVER实验室主办的第四十九期AIR青年科学家论坛如期举行。本活动有幸邀请到香港中文大学(深圳)的助理教授,蒋理博士,为AIR的老师和同学们做了题为“通向空间智能:面向三维场景的世界模型与空间推理”的精彩报告。
讲者介绍

蒋理,香港中文大学(深圳)助理教授,校长青年学者,国家级青年人才。她于香港中文大学获得博士学位,曾在Max Planck Institute担任博士后研究员。他的研究方向包括计算机视觉、人工智能,如三维场景理解、自动驾驶、空间智能、世界模型、表征学习和多模态学习等领域。她的工作在CVPR、ICCV、TPAMI等顶会顶刊中发表并多次选为oral presentation,google citations超过12000。
报告内容
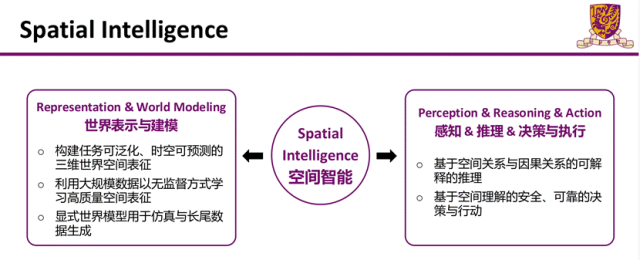
近年来大语言的出现极大地改变了人们日常的工作学习方式。这些由大模型带来的交互方式的变革目前仍停留在数字世界中。为了将人工智能带到真实的三维物理世界中,我们需要发展空间智能(Spatial Intelligence),来让人工智能能够理解真实三维世界中的复杂性并适应与三维世界的交互。蒋理博士认为,空间智能有两个重要的方向:1.世界的表示与建模,2.三维空间中的感知,推理,决策及执行。在本次报告中,蒋理博士介绍了团队近期在空间智能两个方向上的探索与研究成果。
面向自动驾驶的基于全方位场景建模的世界模型
蒋理博士首先提到了当前自动驾驶模型在训练分布外场景中表现欠佳的问题,而世界模型从原始传感器数据中以自监督的方式直接学习通用世界知识,为此问题提供了潜在解决方案。但是现有方法在表征学习的泛化性研究以及世界模型到实际驾驶任务中的迁移研究仍然有限。针对这一问题,蒋理博士团队提出了一个基于全方位场景建模的世界模型DriveX。 DriveX可分为三个模块:(1)全方位场景建模Omni Scene Modeling (OSM) 模块:这一模块学习通用世界知识并编码到潜在的BEV空间,可作为一种自监督、通用的端到端模型预训练策略。(2)解耦世界模型学习策略Decoupled Learning Strategy:将表征学习与预测场景未来发展分离,提升动态场景理解能力。(3)未来空间注意力机制Future Spatial Attention (FSA):以一种统一的范式聚合 DriveX 的未来预测信息,增强下游任务性能。
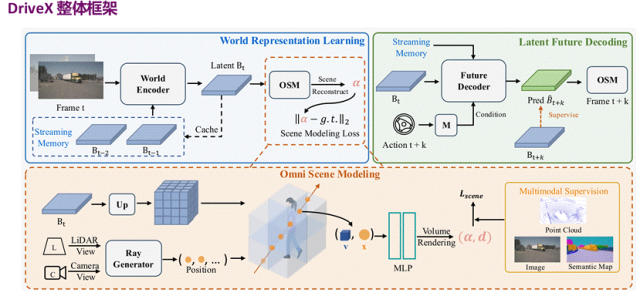
在Omni Scene Modeling (OSM) 模块中,它通过自监督学习的方式将时序图像编码到包含丰富多模态世界知识的鸟瞰 (BEV) 隐空间,随后从BEV隐空间中解码出多模态信息。该模块用了多种场景任务作为监督来学习,包含了3D 点云预测任务(几何结构信息),2D 语义渲染任务(语义信息),图像生成任务(视觉信息)。
过往的世界模型往往会将表征学习和对未来动态学习耦合在一起,这样就导致了优化过程更加困难。 DriveX将这个两个任务解耦开,分别进行学习。世界编码器 (World Encoder) 专注于基于OSM模块进行表征学习,未来解码器 (Future Decoder) 直接利用优化好的世界表征,专注于学习世界动态而无需被表征学习的复杂性所困扰。未来解码器的学习过程由隐空间监督与 OSM 监督共同指导。
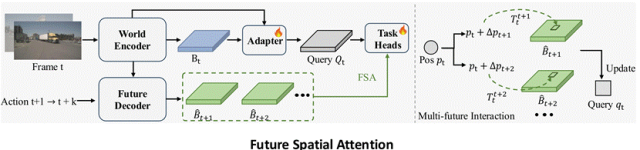
当DriveX基于当前时刻世界表征和动作条件生成未来BEV特征时,一个轻量级适配器将通用世界表征映射到不同的特定下游任务,下游任务利用未来空间注意力机制 (FSA) 动态聚合预测的未来时空特征,对于不同的任务,模型会自动关注最相关的未来空间位置,提升任务性能。这种动态注意力的设计使得模型可以在统一的框架下处理不同的下游任务。

实验结果表明了DriveX在基于NAVSIM测试集的轨迹规划任务和基于nuScenes验证集的点云预测任务上都有明显提升。
基于推理的三维空间感知
在介绍了自动驾驶的世界模型DriveX之后,蒋理博士又介绍了团队的基于推理的三维空间感知的工作。现有的3D LLM存在着对复杂描述的物体在三维空间中难以定位的问题。针对这一问题,蒋理博士团队提出了两个改进的方向:(1)在模型层面,提出了两段“思维链式”推理机制。(2)在数据层面,推出了3D ReasonSeg复杂推理场景数据集。
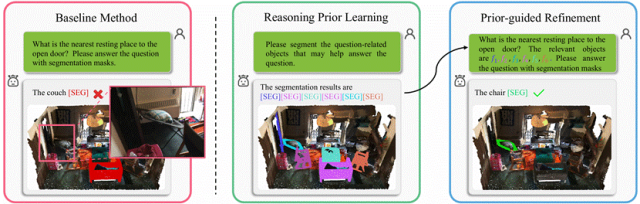
复杂空间推理困难 通过“两步式”推理过程实现物体关系与空间理解
除此之外,还提出了一个针对3D LLM的空间推理能力的Benchmark。Baseline model部分,首先用了一个Visual Backbone来提取场景点云super-point特征,接着用Q-Former根据场景特征与语言指令信息将场景信息提取至latent queries,再通过LLM来生成 LISA-style [SEG] token,最后用SAM-style的Decoder来分割解码。

在baseline model基础上,进一步提出了Relevant Reasoning Segmentation。第一步:Reasoning Prior Learning根据相关物体查询得到空间推理先验,提供上下文信息。第二步:Prior-guided Refinement 根据推理先验优化hidden representation,进行准确的目标定位。
在数据层面,为3D点云场景的推理任务提供数据,加强及评估3D MLLM的空间推理能力,提出了3D ReasonSeg: A Reasoning-based Segmentation Dataset。它的关注重点在物体功能,视觉特征,和空间关系。数据集的构建方式:a)利用大模型,给定场景中的物体描述、位置、大小来生成 question-reasoning-answer 数据并指明target-relevant objects. b)根据规则来进行合规数据筛选,如对不符合prompt格式要求的数据进行清除,对涉及 “largest”, “nearest”的物体描述根据物体尺寸与位置来进行检验。

从实验结果中,我们能看到在加入了3D ReasonSeg作为训练数据以及使用了Relevant Reasoning Segmentation推理框架后,提升了模型的性能。
在报告结尾,蒋理博士分享了她关于世界模型未来探索方向的几个观点:1.当前的世界模型并没有特别清晰的定义,我们可以在基于Latent Space来做世界推演,来帮助下游的感知、规划、预测等任务,也可以基于Observation来做世界推演,来生成Corner Case的数据帮助端到端闭环仿真任务。2.为了保证世界模型的时空一致性,可以考虑在世界模型中引入3D的Implicit/Explicit的空间表征。3.世界模型也可以理解为是3D的表征学习,怎么去更好地利用视觉信息来帮助学习得到更好的3D表征也是非常重要的研究方向。
AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR










