大家好,欢迎来到立芯嵌入式。
搞嵌入式的同学,对缓存这东西肯定不陌生。无论是 ARM Cortex-M 的指令 Cache,还是 Cortex-A 的多级数据 Cache,它们在系统性能里都扮演着举足轻重的角色。但要说真正理解 CPU Cache 的一致性机制,恐怕很多人都只是停留在一知半解的阶段。今天我们就来聊聊关于 Cache 的一些常见误区。
为什么要关心 CPU Cache
有些人可能觉得,Cache 一致性这种玩意更多是操作系统、编译器或者分布式系统工程师该操心的事。实际上,对于嵌入式开发同样重要。
Cache 一致性跟我们常说的分布式系统里 强一致性 和 最终一致性 的概念是一脉相承的。硬件里的研究成果,反过来能帮助我们更好地理解多核、多任务系统下的数据一致性问题。

很多关于并发和竞态条件的错误认知,都会直接导致设计失误。比如有人会说:并发编程难,是因为不同核心的 Cache 里存的值可能不一样;或者认为在 C 语言里加上 volatile,就是强制让数据每次都写回内存,避免被 Cache 掉。

这些说法听起来有点道理,但其实并不准确。误解如果被带到项目设计里,很可能导致你以为自己规避了并发 Bug,实际上却埋下了隐患。

再比如,很多人担心 volatile 变量会拖慢速度,以为它真的每次都要绕过 Cache 去主存。要真是这样,那访问一次主存比 L1 Cache 慢两百倍,程序早就跑不动了。事实上,大多数情况下 volatile 变量的读写开销和 L1 Cache 差不多,远没有想象中可怕。
Cache 到底是怎么保持一致的
既然多核 CPU 每个核心都有自己的私有 Cache,那大家同时写同一块数据的时候,不就一定会乱套吗?
其实不然。现代的 CPU,比如常见的 ARM Cortex-A 或 Intel x86,都有复杂的硬件协议来维持各级 Cache 的一致性。Cache 并不是简单的存储单元,而是带有逻辑和状态机的复杂部件。它们之间不断交换信息,保证多个核心在读写同一地址时不会出现莫名其妙的错乱。
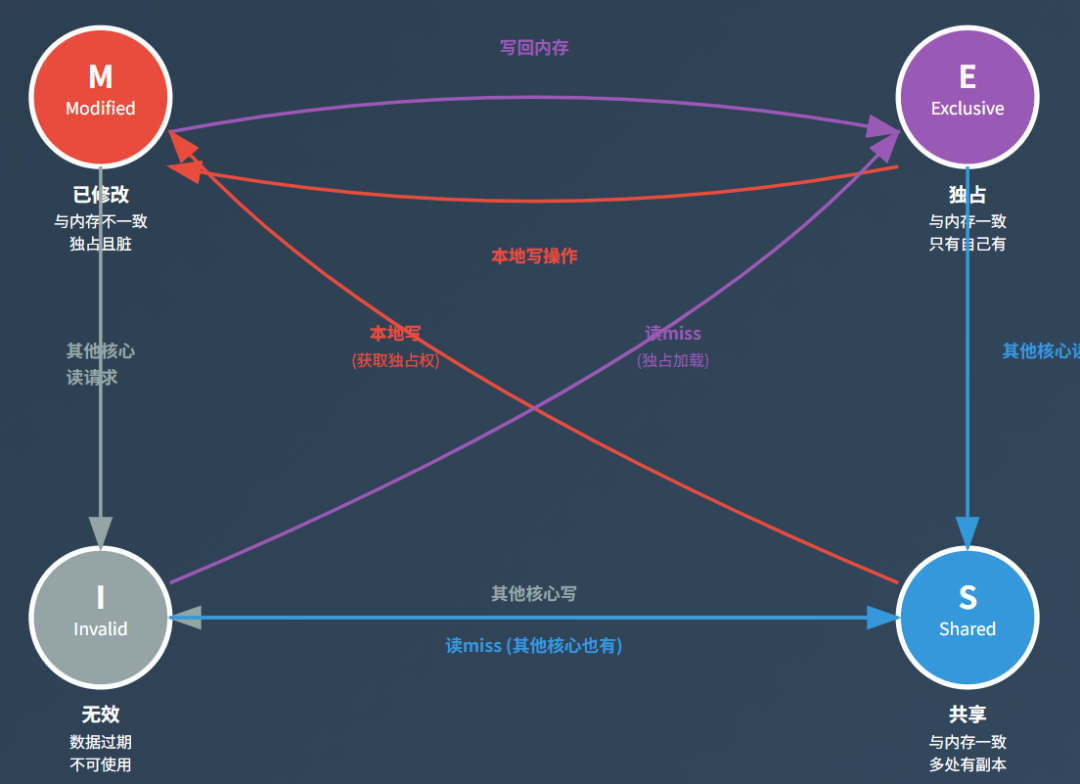
这里面最经典的协议就是 MESI 协议。简单来说,每一行 Cache Line 都会被标记为下面几种状态之一:
M 状态(Modified):数据被修改过,与主存不一致,这一份是权威版本 E 状态(Exclusive):数据没被修改,和主存一致,只有本 Cache 拥有 S 状态(Shared):数据没被修改,可以和别的 Cache 共享 I 状态(Invalid):数据无效,不能使用
通过这几个状态的转换,Cache 之间就能协调好谁该读、谁该写、谁该失效,从而保证一致性。
举个例子,如果 Core1 要往某个地址写数据,而 Core2 的 Cache 里正好也有这个地址的旧副本,硬件会自动发出 失效通知,让 Core2 的那份数据标记为无效。这样一来,下一次 Core2 需要用这个地址,就会重新从最新的数据源加载,而不会傻乎乎用旧数据。
这一切都在硬件里悄无声息地完成,软件层几乎感知不到。对于我们写程序的人来说,看到的始终是一个一致的存储空间。
多核一致性 ≠ 没有并发问题
有人会问:既然硬件已经保证了缓存一致性,那是不是意味着我们写多线程代码就不用担心共享变量的同步了?
答案当然是否定的。
问题在于,CPU 的寄存器并不参与缓存一致性。编译器为了优化,会随意把变量加载进寄存器、延迟写回,甚至重排序指令。这些行为在单线程下没毛病,但在多线程环境里就可能导致严重的竞态问题。
因此,语言层面才需要提供各种同步手段,比如 C11 的原子操作、FreeRTOS 的任务通知、或者我们常用的信号量和互斥锁。至于 volatile,在 ARM 编译器里更多是告诉编译器不要随便优化,而不是让你“强制绕过 Cache”。
换句话说,硬件帮你解决了缓存一致性,软件还得自己处理并发控制。两者缺一不可。

小结
CPU Cache 看似离我们嵌入式软件开发很远,其实和日常写代码息息相关。理解硬件一致性协议的原理,能帮助我们少掉进很多误区。特别是在 FreeRTOS、Linux 这种多任务环境下写程序的时候,记住一点:
硬件能保证缓存一致,但不能替你处理并发控制。
锁、信号量、任务通知这些同步手段,永远是我们必须掌握的武器。











