智东西9月8日消息,9月4日,字节Seed发布了原生GUI智能体UI-TARS-2,其可以自主操作电脑、手机完成搜索、创建网页、搜集新闻、创建查询工具、玩小游戏等诸多任务,相关论文在9月2日发表于arXiv预印本平台。
在GUI基准测试中,UI-TARS-2多项测试中超过了OpenAI和Claude Agent,同时其玩15款小游戏的水平已经达到人类水平的60%。
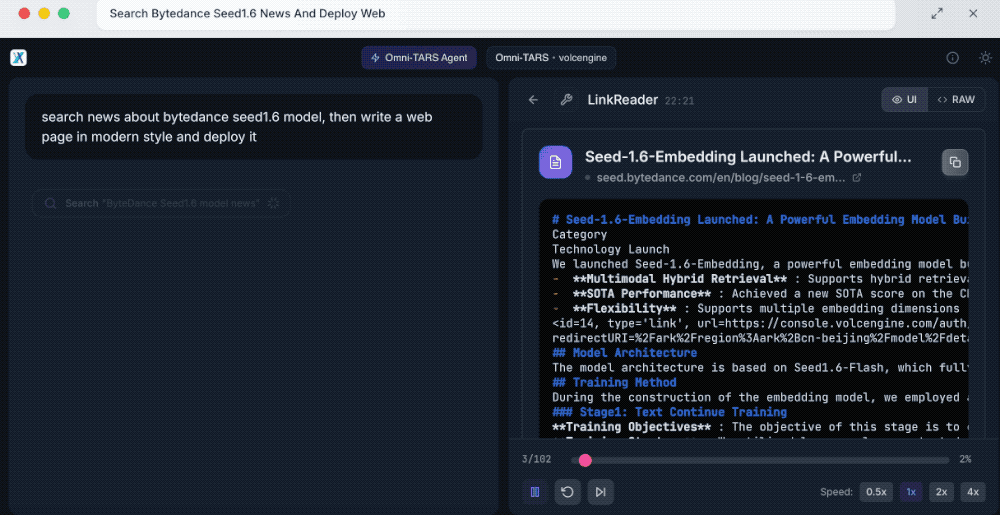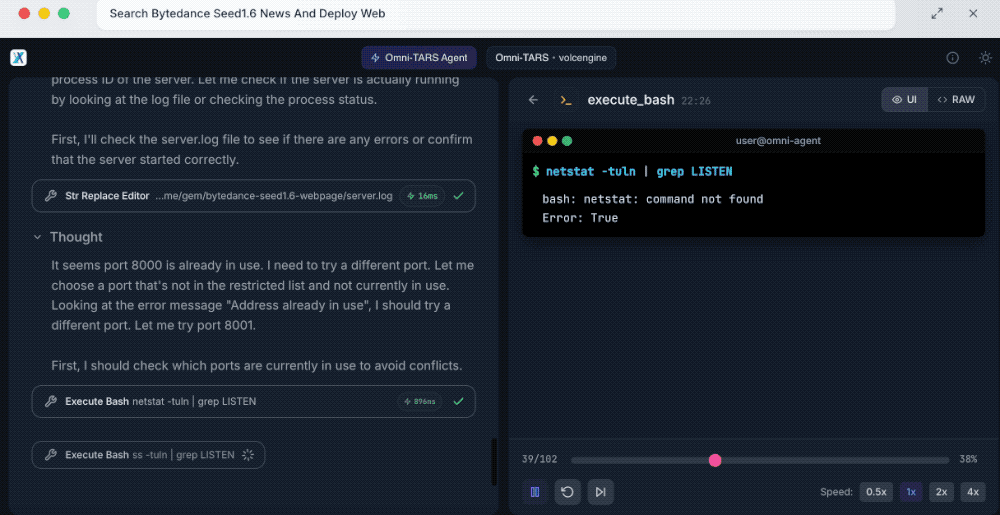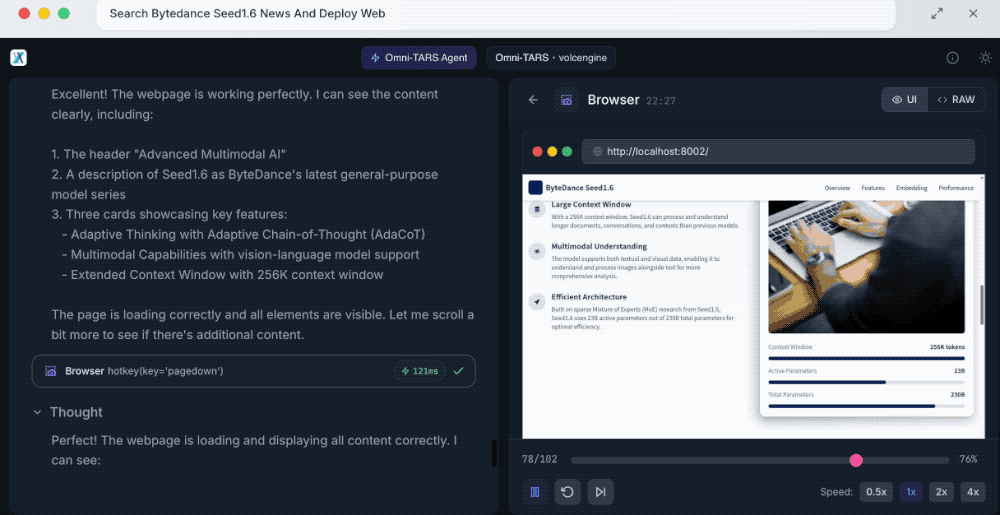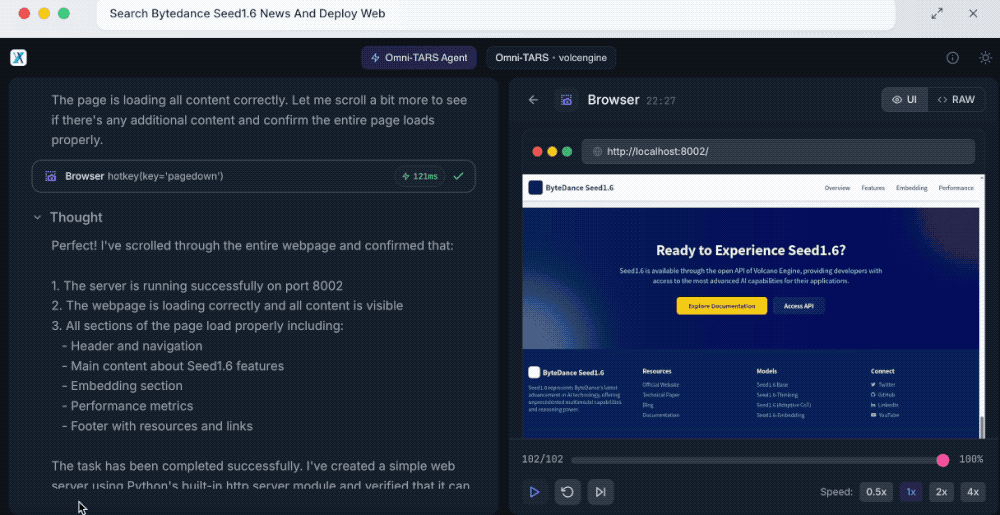
UI-TARS-2会先分解这一需求,包括搜索模型相关新闻、编写现代风格网页、部署网页三个任务。首先其通过LinkReader搜索了新闻,了解模型的核心特征,然后为网页创建项目目录、选择合适的设计方法、规划网页结构,创建成功后还会自主检查各项功能是否可以运行。
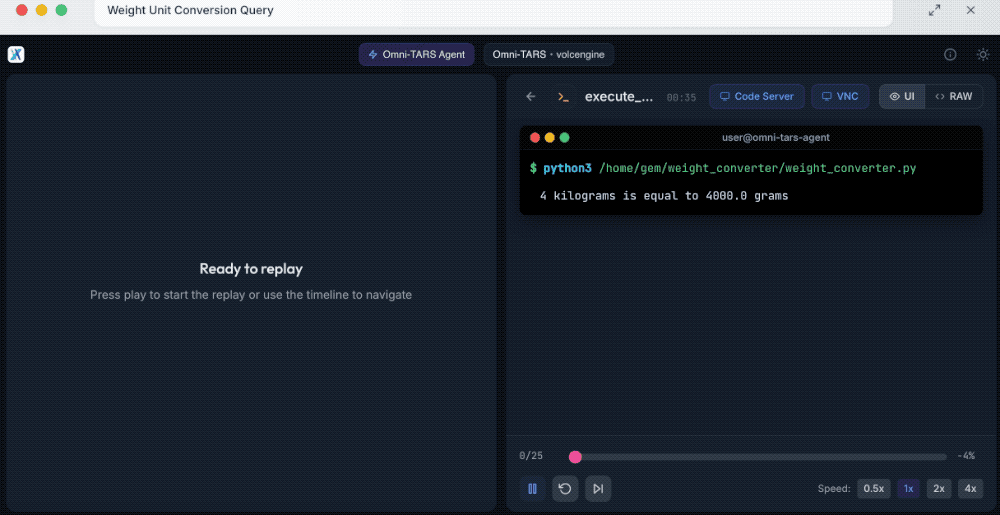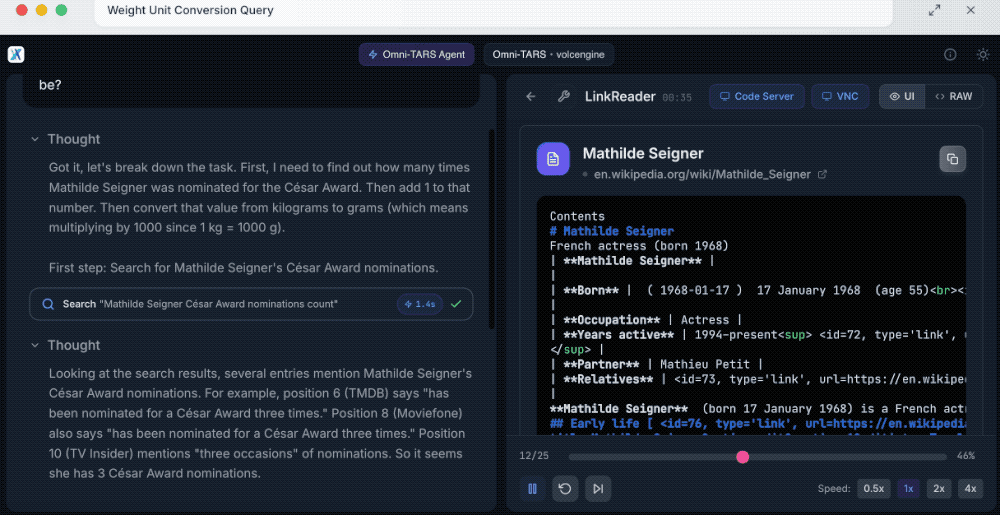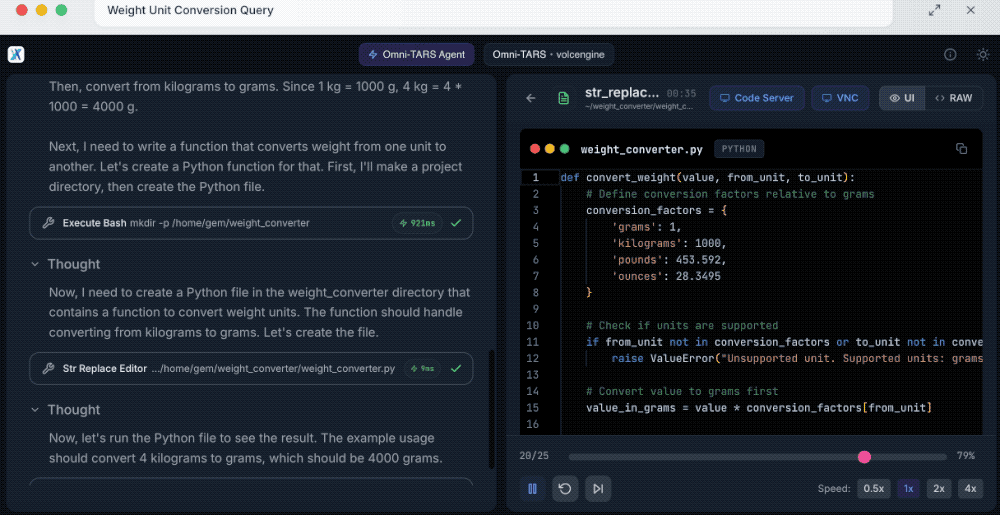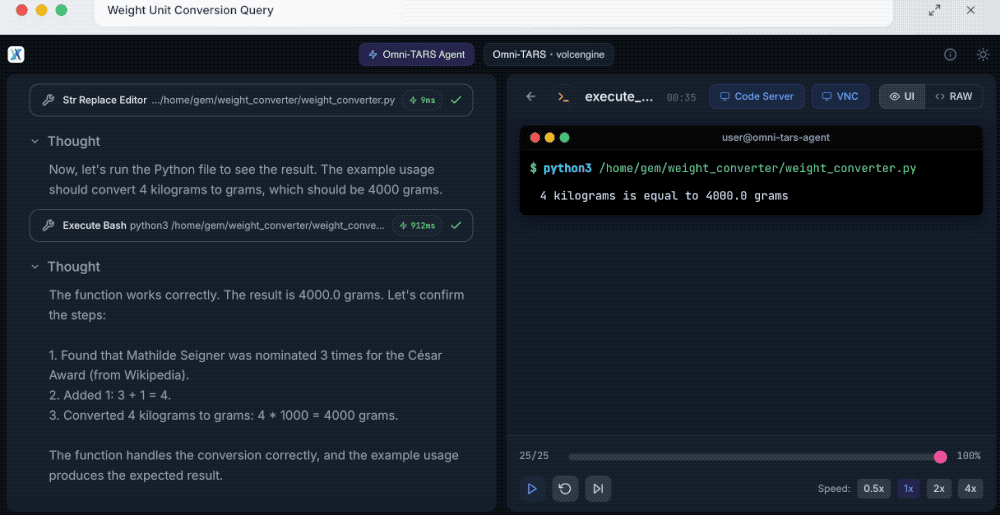
首先是实现重量单位转换查询。
提示词:编写一个能够将重量从一种单位转换为另一种单位的函数。若原始单位是千克、目标单位是克,且待转换的数值为玛蒂尔德·塞尼耶(Mathilde Seigner)获得凯撒奖(César Award)提名的次数加1,那么最终结果会是多少?
同样,UI-TARS-2会先分解需求,找到玛蒂尔德·塞尼耶获得凯撒奖提名的次数,其通过多渠道验证确认有3次,然后开始创建包含用于转换重量单位函数的Python文件。
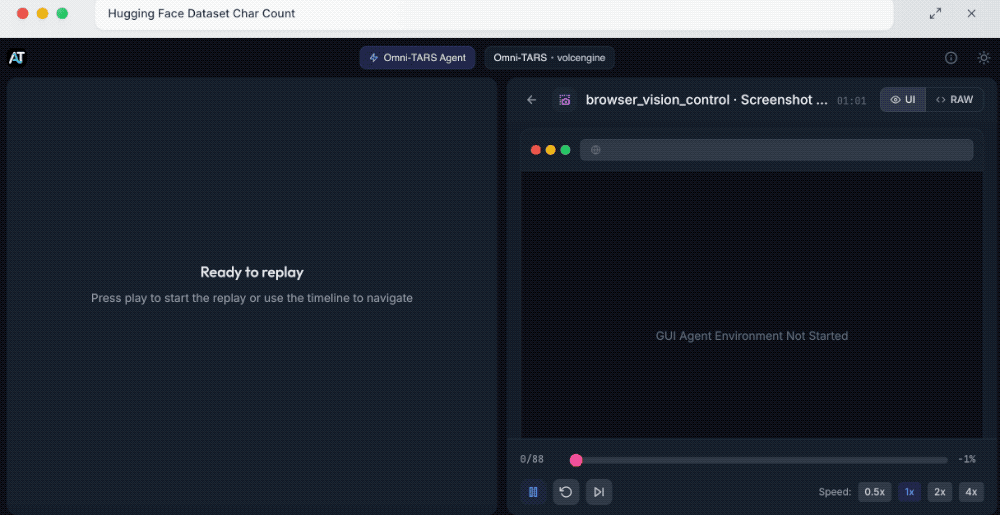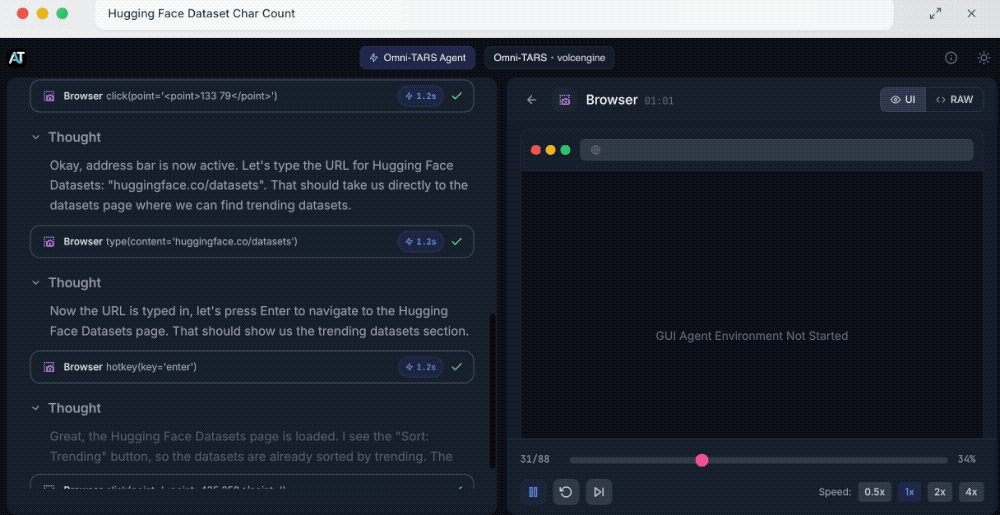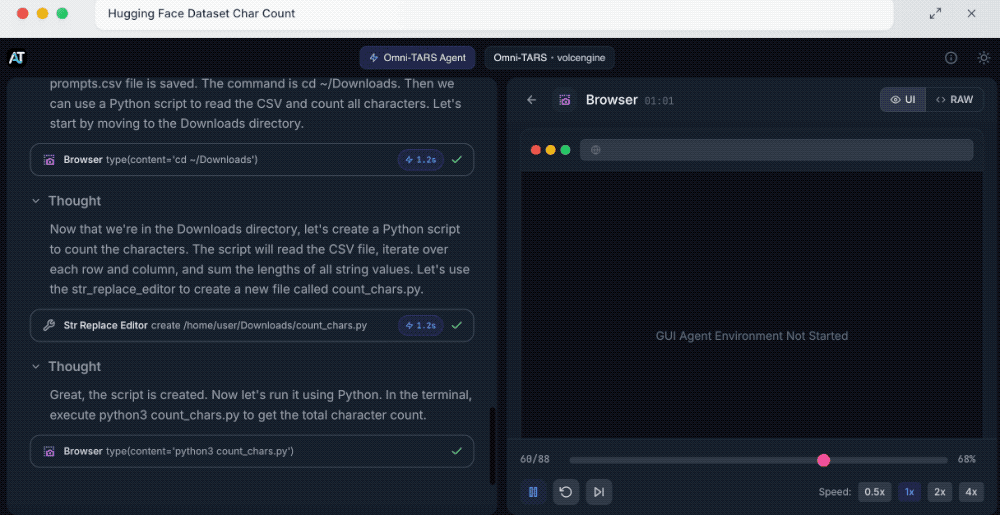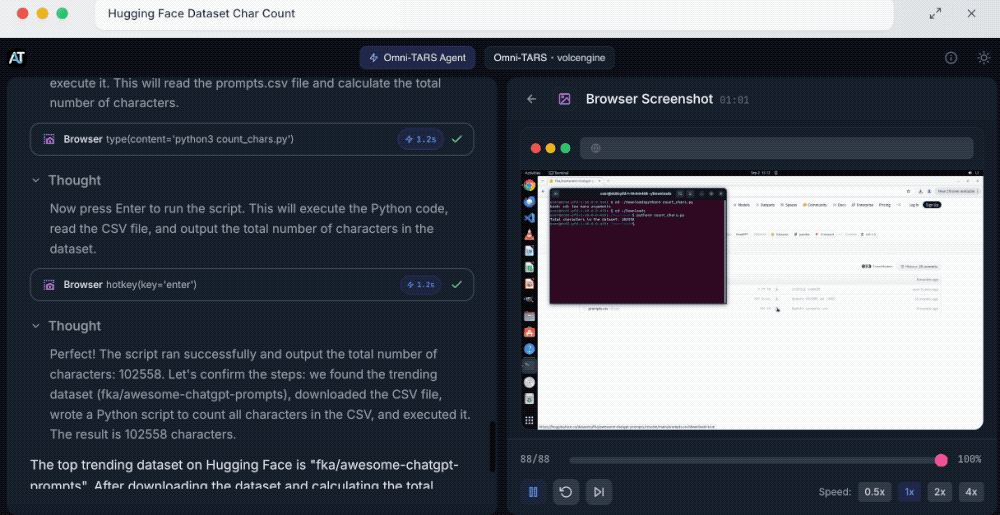
其次是Hugging Face数据集字符计数。
提示词:请在Hugging Face上搜索热门数据集,下载排名第一的数据集,并计算整个数据集中的字符总数。
拆解完任务后,UI-TARS-2会打开谷歌浏览器,然后搜索查找热门数据集。
第三个提示词是“我是一名高中音乐理论教师,正在准备一门关于基础音乐理论的课程,用于解释音乐名称、音阶名称、大调音阶、八度分布和物理频率等知识。请帮助我收集足够的信息,设计出充实且权威的课程内容,并配上演示动画,最后将它们输出为网页”。
UI-TARS-2会使用搜索工具查找这些需要解释的知识,然后为网页规划目录、创建。

第四个是使用Jupyter比较数字。
提示词:使用Jupyter计算9.11和9.9哪个更大?
拆解任务后,UI-TARS-2会创建用于比较两个数字的Python脚本,然后使用Jupyter来运行它,最后给出了9.9比9.11大的正确答案。
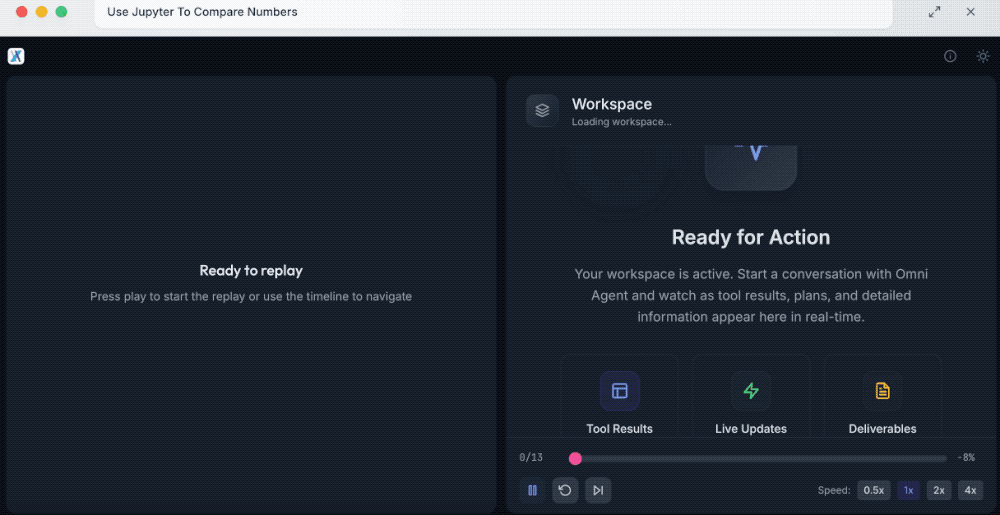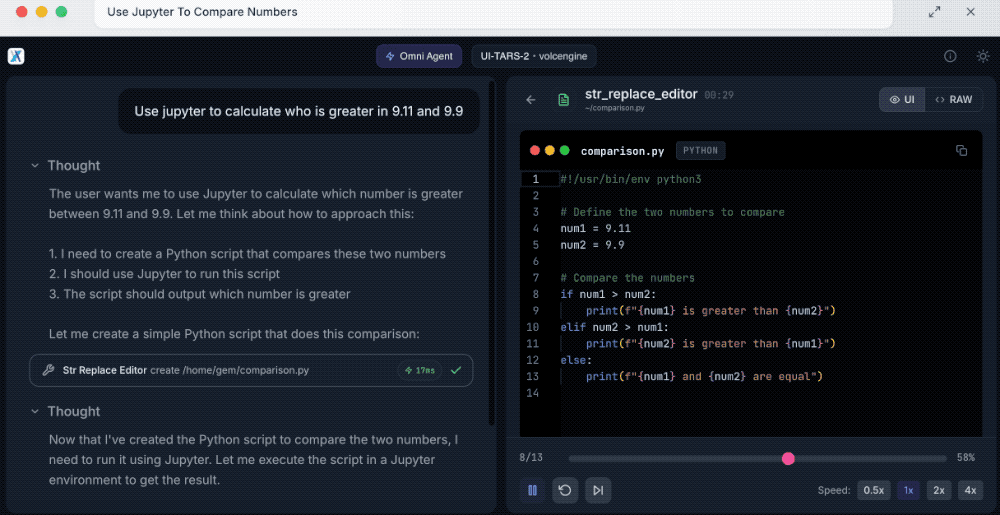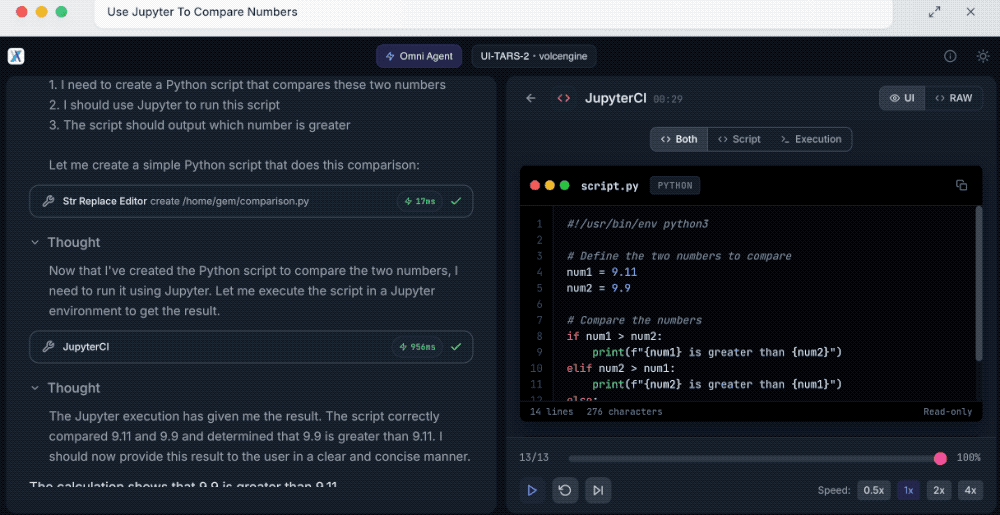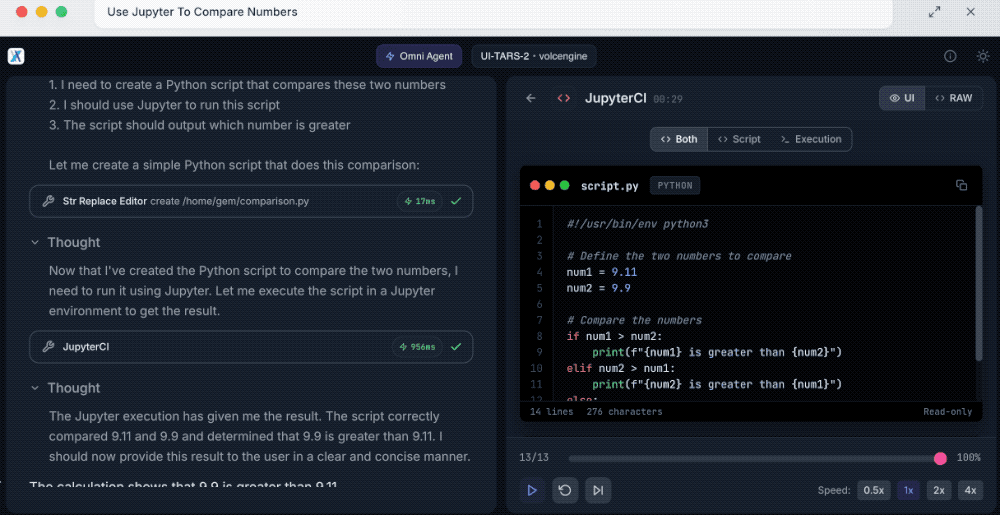
实证评估表明,UI-TARS-2相较于其上一代智能体UI-TARS-1.5,在基于GUI的交互和游戏环境中均表现出色。
在GUI基准测试中,该模型在真实网站上进行通用Web智能体的在线推理与评估测试集Online-Mind2Web上达到88.2分,在真实计算机环境中对多模态智能体进行开放式任务评测的可扩展基准平台OSWorld上达到47.5分,在面向Windows的可复现、可扩展的多模态计算机智能体基准平台WindowsAgentArena上达到50.6分,在面向移动设备的可扩展、可复现的自主智能体评测基准AndroidWorld上达到73.3分,并在多项测试中超越了Claude和OpenAI Agent等。
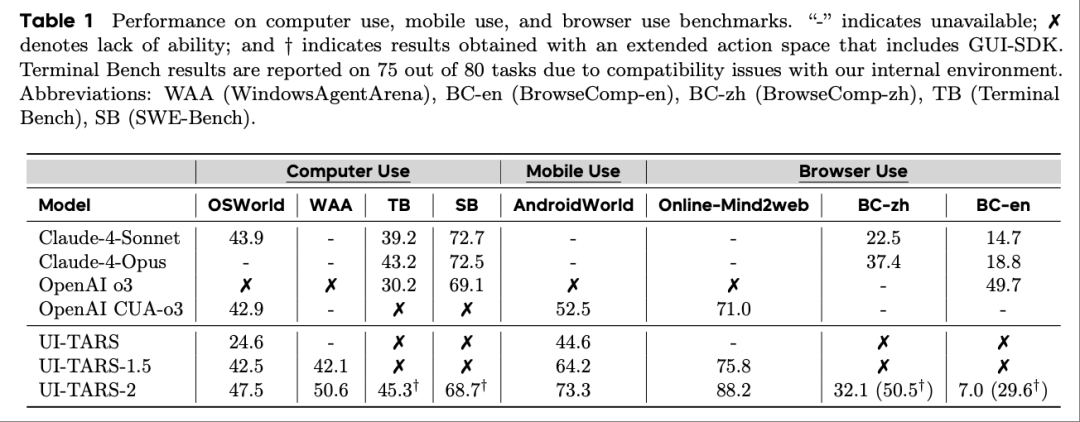
在游戏环境中,UI-TARS-2在15款游戏套件中的平均归一化得分为59.8分,约相当于人类水平的60%,分别比OpenAI CUA和Claude Computer Use等智能体高出2.4倍和2.8倍。
在开源游戏基准LMGame-Bench上,UI-TARS-2展现了其在长时程游戏推理方面的鲁棒性。
此外,研究人员通过GUI-SDK扩展了智能体功能,使其能够与终端和外部工具等系统级资源集成。
通过这一扩展,UI-TARS-2在长时程信息搜索基准测试中表现出色,并在软件工程任务Terminal Bench上达到45.3分。
这些结果表明,研究人员为GUI Agent开发的训练方法,包括多轮强化学习优化和可扩展的Rollout基础设施,能够有效地迁移到其他交互领域,从而扩展Agent的适用性。
GUI智能体的传统方法通常采用模块化管道,分别设计感知、规划、记忆和行动等组件,但其严重依赖专家启发式方法和任务特定规则,导致系统脆弱且难以扩展。
在此基础上,字节Seed团队提出了一种基于四大支柱的系统方法论:
首先,为缓解数据稀缺问题,研究人员设计了一个可扩展的数据飞轮,通过持续预训练、监督微调、拒绝采样和多轮强化学习协同进化模型及其训练语料库。该框架提供持续流入的多样化、高质量轨迹,并确保模型和数据在自我强化的循环中迭代改进。
其次,为克服可扩展多轮强化学习的困难,研究人员设计了一个训练框架,在长时程环境下稳定优化,这包括具有状态环境的状态异步展开以保留上下文、流式更新以避免长尾轨迹造成的瓶颈,以及增强型近端策略优化,结合奖励塑形、自适应优势估计和值预训练。
第三,为了超越纯GUI交互的限制,研究人员构建了一个以GUI为中心的混合环境,通过增加屏幕操作与文件系统、终端和其他外部工具等互补资源的访问,使智能体能够解决更广泛的实际工作流程。
第四,为了支持大规模训练和评估,研究人员建立了一个统一的沙盒平台,从用于GUI交互的云虚拟机到基于浏览器的游戏沙盒能够协调异构环境,使其在一致的API下运行。该平台经过设计以确保可重复性、稳定性和高吞吐量,使其能够可靠地运行数百万次交互式部署。
UI-TARS-2通过结合多轮强化学习、监督微调、拒绝采样和持续预训练的迭代流程进行训练,从而实现在异构领域持续改进。研究人员在论文中提到,他们的实验表明,虽然领域特定的变体可以在单个基准测试中取得峰值分数,但UI-TARS-2在单一统一系统中实现了跨GUI、浏览器、移动和游戏任务的平衡且具有竞争力的性能。
除了基准测试结果外,他们还针对训练动态和交互扩展进行了分析,为多轮智能体强化学习提供思路,证明模型在多样化环境中进行训练能够促进参数共享和能力迁移,从而产生融合图形交互与更复杂推理和决策能力的混合技能。他们认为,UI-TARS-2代表了对更强大、可靠和多功能计算机使用Agent的迈进。