
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。然而,现有 VLA 基座模型的能力仍存在很大不足,在进行目标场景应用时需要采集数十乃至数百小时目标本体数据完成后训练(Post-Training),特别是当目标场景本体和预训练本体存在差异时,预训练和后训练阶段的动作分布出现严重失配,从而引发了 VLA 模型跨本体适配(Cross-Embodiment Adaption)挑战。在后训练阶段通过堆叠目标本体数据对抗这种失配的边际收益迅速递减,也难以有效拟合目标场景动作分布。
为了解决该问题,中国电信人工智能研究院(TeleAl)具身智能团队提出了一种 “对齐 - 引导 - 泛化”(Align then Steer, ATE)的 VLA 跨本体泛化框架,破解了 VLA 后训练难题。其核心思想是在潜空间中对齐跨本体动作分布,从而在后训练利用统一潜空间梯度引导 VLA 策略的更新方向。无需改动现有 VLA 主干架构,实现了 VLA 模型后训练从调架构向调分布的范式转移,适配 Diffusion 和 Flow-Matching 等主流的 VLA 模型,极大减少 VLA 跨本体适配的数据需求。
论文题目:Align-Then-Steer: Adapting the Vision-Language Action Models through Unified Latent Guidance
论文地址:https://arxiv.org/abs/2509.02055
项目地址:https://align-then-steer.github.io/
开源代码:https://github.com/TeleHuman/Align-Then-Steer
研究动机:从分布一致性突破 VLA 的跨本体泛化训练瓶颈
在面向特定具身场景的操作大模型应用中,决定 VLA 能否进行跨本体迁移的关键并非参数规模或主干架构的复杂度,而是预训练阶段与后训练阶段的目标本体和任务的动作分布的一致性。特别地,当目标本体的机械臂构型、执行器形态、关节自由度与本体物理约束等发生变化时,目标动作分布不可避免地偏离预训练阶段 VLA 学得的动作分布域。单纯地通过采集大量真机数据在后训练阶段弥补这一鸿沟,面临迅速递减的边际收益,即单纯数据堆叠难以有效地引导策略抵达目标域。
为了解决 VLA 的跨本体泛化适配问题,目前学界采用的方法主要从以下两个角度开展,构建统一的、语义级别的潜在动作表示,或通过运动学重定向(Retargeting)手动将跨本体数据构建到统一的动作空间。然而,这些路径普遍存在两类局限:一方面,目标动作分布与原分布相差过大时(如预训练采用单臂数据,目标场景在双臂),上述的方法难以准确刻画目标本体的可行子分布;另一方面,现有方式依然面向自回归范式,并没有考虑扩散 / 流匹配类策略的条件生成结构。为了解决该问题,TeleAI 具身智能团队提出了 “对齐 - 引导 - 泛化”(ATE)框架,在统一的潜空间中先对齐动作统计,并在后训练阶段引入可微的引导项牵引策略更新,仅利用少量样本便可以将模型适配到目标本体。

研究方法
ATE 框架
ATE 框架的核心思想是先在潜空间中对齐动作分布,再利用潜空间的分类器引导去牵引后训练策略更新方向。ATE 框架如上图所示,共分为两个阶段。
第一阶段先构建一个与跨本体的统一动作潜空间,将预训练数据所蕴含的跨任务、跨环境结构性信息编码到潜空间,再利用目标域的有限样本将目标潜空间嵌入到预训练潜空间。在完成潜空间的对齐后,第二阶段在统一的潜空间上设计引导函数,并利用由此得到扩散 / 流匹配 VLA 模型的分类引导,在后训练阶段显式地将微调过程牵引至期望的目标分布,而无需更改 VLA 模型主干模型结构。
在 ATE 框架中,“对齐 — 引导” 都从分布的角度出发:先把目标域的动作潜分布嵌入到预训练动作潜分布的某个模态中,随后用一个可微的分类器引导项把策略输出的生成分布朝目标分布持续推近。第一步等价于在潜空间上完成一次分布投影;第二步等价于在生成过程中为分布流添加一个外部力场,沿着统一潜空间定义的能量梯度推进去噪,使最终的边缘分布更接近适配数据分布。
这种 “从调模型到调分布” 的范式迁移具有如下优势。第一,样本效率提升:潜空间对齐将策略搜索范围约束在包含目标分布域的流形上,显著降低了拟合到可行动作分布所需的数据量。第二,训练效率提升:分布引导避免模型全参数重训练,能够在既定训练预算内获得更快的有效收敛。第三,工程可复用性增强:潜空间引导只作用于动作专家模型后训练,与顶层模型解耦,具备即插即用的特性,可适配目前主流分层 VLA。
第一阶段:动作潜分布对齐

在对齐阶段,ATE 框架分别构造了两个小型变分自编码器模型(VAE)来对齐两阶段数据的动作空间。具体而言,首先构建一个统一动作潜空间,将预训练和适应阶段的动作数据嵌入到同一潜空间中。该方法通过训练一个 VAE 在预训练动作数据上,获得一个固定的动作潜先验分布。接着,对适应阶段的动作数据,训练第二个 VAE,并通过反向 KL 散度约束,将适应动作的潜分布嵌入到预训练潜分布的特定模式中。由于反向 KL 散度的模式寻找特性(mode seeking),能够将适应动作的潜表示紧密嵌入到预训练分布的主模式中,使适配数据的潜变量分布 逼近预训练潜分布
逼近预训练潜分布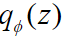 某一模态,从而把目标域的动作分布嵌入到预训练域已经学到的潜空间中,得到统一的动作潜空间 Z,从而实现高效的跨实体和跨任务适应。此外,该方法仅需对 VAE 进行训练,无需修改原始 VLA 架构,具有低计算开销和高适配性。
某一模态,从而把目标域的动作分布嵌入到预训练域已经学到的潜空间中,得到统一的动作潜空间 Z,从而实现高效的跨实体和跨任务适应。此外,该方法仅需对 VAE 进行训练,无需修改原始 VLA 架构,具有低计算开销和高适配性。

第二阶段:动作潜分布引导

在引导阶段,设计了面向主流 VLA 框架的引导机制,通过能量函数和分类器,衡量生成动作与目标动作分布的差异,并将引导梯度整合进模型的训练目标函数中。这一过程无需额外数据,仅依赖细调数据的噪声样本作为参考,即可在保持预训练模型通用性的基础上,高效地将模型输出引导至与新任务和实体相匹配的动作分布。具体的,ATE 在潜空间内构造 classifier guidance 函数,度量当前去噪时间步的策略输出动作块(action truck)与目标动作块在潜空间的距离,其梯度 被直接加到扩散过程的分数函数或流匹配的速度场更新式中,从而在每个去噪 / 流动时间步对生成轨迹的分布施加 “拉力”,把概率质量往目标分布牵引。通过引入分类器引导函数无需通过改变 VLA 的主干结构和动作空间,却可以改变训练时优化的分布方向。
被直接加到扩散过程的分数函数或流匹配的速度场更新式中,从而在每个去噪 / 流动时间步对生成轨迹的分布施加 “拉力”,把概率质量往目标分布牵引。通过引入分类器引导函数无需通过改变 VLA 的主干结构和动作空间,却可以改变训练时优化的分布方向。

引导机制充分利用了统一潜空间的优势,既解决了跨实体和跨任务的适应性问题,又保留了预训练阶段习得的通用视觉 - 运动先验知识,显著提升了模型在新环境下的适应效率和性能。
实验结果
ATE 算法在 ManiSkill 与 RoboTwin 1.0 等多任务仿真评测中,相较于直接后训练,平均多任务成功率最高提升 9.8%。而在真实机器人跨本体现实场景中,ATE 带来最高 32% 的成功率增益,且表现出更稳健的收敛行为与对光照、干扰的鲁棒性。这些结果表明:ATE 框架在统一潜空间中引导学习,使得 VLA 跨本体与跨任务泛化在有限数据下得到提升,而无需额外的数据与大规模重训练。
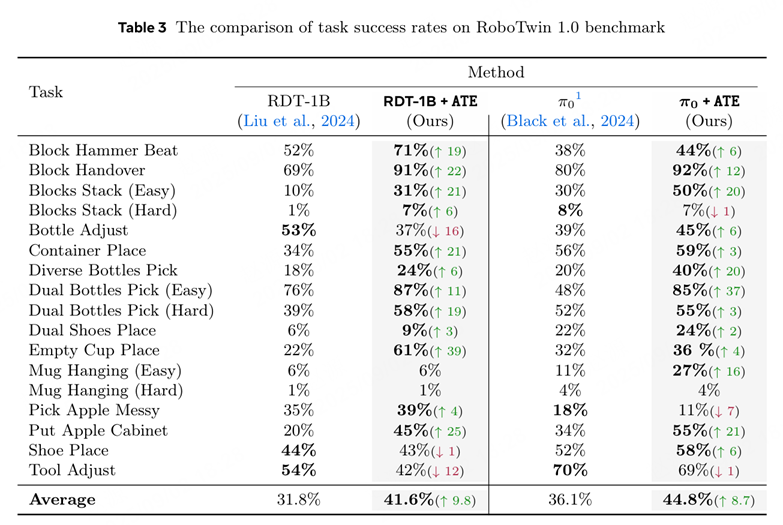
上表汇总了 17 个机器人操作任务上,ATE 框架下 RDT 和 PI-0 在 RoboTwin 1.0 上的性能对比。ATE 框架对 RDT 与 PI-0 的平均提升分别约为 + 9.8 与 + 8.7 个百分点,显示出跨任务的一致增益与较好的可迁移性。尤其在基线困难的长程任务中,单项增益明显:例如,RDT 在 Empty Cup Place 任务成功率由 22% 提升到 61%(+39),Pi 0 在 Dual Bottles Pick (Easy) 任务上成功率由 48% 提升到 85%(+37),反映了潜空间对齐与引导在动作空间分布失配较大的场景中效果更显著。与此同时,个别任务出现了小幅下降,如 RDT 在 Bottle Adjust(-16)、Tool Adjust(-12)、Shoe Place(-1),Pi 0 在 Pick Apple Messy(-7)、Blocks Stack (Hard)(-1)、Tool Adjust(-1)。这类现象通常表现为目标域动作分布较窄。从样本效率与收敛速度角度,ATE 在 70k 步即可超过传统 RDT 的 90k 步效果,说明 ATE 框架的对齐 — 引导机制,不仅提高任务成功率,也显著提升了任务成功率。
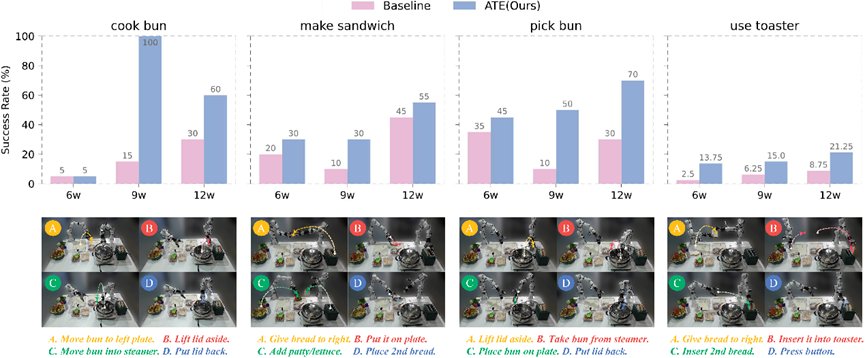
为了验证模型的跨本体泛化能力,我们自行搭建了双臂睿尔曼实验环境,该实验平台从未在预训练数据中出现过,且双臂的动作空间和预训练数据有明显不同。进而,构建了多个分钟级长序双臂协同操作任务,包括制作三明治、蒸包子等复杂协作任务,以及制作酸奶、烤面包等工具使用类任务。通过采集少量真机数据进行后训练,ATE 算法能够将基座 RDT 和 Pi-0 等 VLA 模型快速适配到目标本体上。上图呈现了四个真机任务在不同训练步数的成功率与整体平均,展示了在有限数据与分钟级长程任务下 ATE 框架的性能。可见在需要双臂协同、时序规划与多阶段配合的任务上,在统一的潜空间引导下 ATE 框架能使模型更快地收敛到目标域动作分布。

上图可视化了空间泛化(初始位姿随机偏移)、视觉干扰(放置未见过的杂物,如水果)、人为扰动(在关键点迫使策略重试)。ATE 框架在未见的光照、杂物干扰、空间偏移与外部干预下仍能维持任务相关注意与恢复能力。
研究总结
在 VLA 基座模型尚不具备直接泛化能力的情况下,TeleAI 提出的跨本体 ATE 后训练框架为数据稀缺与跨本体泛化后训练难题提供了可行答案。面对数据预算、训练窗口与算力上限的三重约束,无需寄望于数据堆叠或昂贵的全参重训,而是以最小工程代价引入潜空间对齐与分布引导,实现快速、稳健的跨本体泛化适配。换言之,ATE 框架可以作为一个即插即用的模块,成为兼容各种主流 VLA 模型的后训练阶段的对齐引导方案,用于提升后训练的跨本体泛化能力,成为破解数据与训练瓶颈的实践路径。
作者简介:本文由 TeleAI 三名研究实习生:清华大学博士生张扬、港中文硕士生王陈炜、西工大硕士生陆欧阳作为共同第一作者,成果由 TeleAI 联合清华大学、港中文、西工大合作完成,本文通讯作者为 TeleAI 具身智能团队负责人白辰甲博士和 TeleAI 院长。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










