
如果人工智能真的要普及,正如投入巨资的模型构建者和数据中心建设者所期望的那样,那么它就必须成为一种全球现象。因此,它需要的全球规模的计算能力将远超我们在 1990 年代末互联网泡沫时期和 2010 年代大数据泡沫时期所见的任何规模。
简而言之,这就是 GenAI 先驱 OpenAI 的硬件主管 Richard Ho 本周在圣克拉拉举行的 AI 基础设施峰会上发表主题演讲时传递的信息。我们原本希望 Ho 能谈到传闻中 OpenAI 正在与博通 (Broadcom) 合作开发的“Titan”自主研发推理芯片,我们上周在分析这家芯片制造商的最新财务业绩时也讨论过这款芯片。可惜,他没有。
然而,与 Meta Platforms 和谷歌的同行一样,何先生确实谈到了随着 GenAI 模型的扩大以及对计算和网络需求的增加,所需的大规模基础设施。
网络是关键,它由计算驱动,而计算的发展速度早已超越摩尔定律,不仅需要插槽内互连,还需要机架内和跨机架的链接,以使大量 XPU 芯片协同工作。正如我们之前所说,这意味着超级计算真正走向主流,即使它专注于模拟人类与数字尾气交织的低语,而不是模拟星系、飓风、DNA 分子之类的东西。因此,正如你所想象的,我们对 OpenAI 在未来五到十年内试图推动 AI 处理技术发展所采取的措施充满好奇。何曾在 Arm 服务器新贵 Calxeda、谷歌(负责 TPU 开发以及 Pixel 手机的视频编码器和 EdgeTPU)担任过关键计算职位,并在硅光子学先驱 Lightmatter 工作过一段时间,这表明何能够带来巨大的发展。
如今,如果有人想在 AI 处理方面超越英伟达,就必须创造出在多个向量上都比英伟达的“Blackwell”或“Rubin” GPU 加速器更优秀的产品,并且必须认真思考如何将使用这些加速器的系统整合成一个整体,从而降低推理成本。Sam Altman 和他的团队深谙此道,Ho 也深谙此道。正因如此,我们对 OpenAI 自主研发的加速器及其“星际之门”项目抱有很高的期望。
何先生在 AI Infra 峰会上的演讲概括了他的团队正在创造的技术,即使没有具体说明该技术。
当然,这一切都始于指数增长,Ho 展示的这张图表在 X 轴上绘制了训练模型的总体计算量,并在 X 轴上绘制了大规模多任务语言理解 (MMLU) 测试的总体得分:
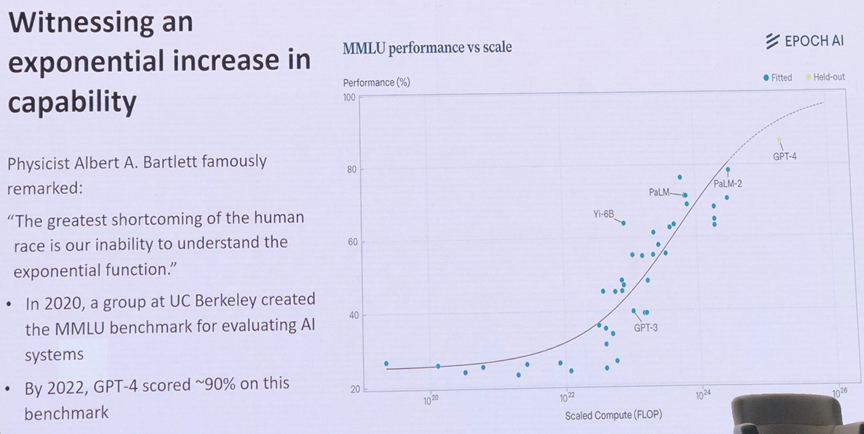
如你所见,OpenAI 的 GPT-4 模型将这条曲线稍微向下弯曲了一点。有趣的是,Ho 确实展示了 GPT 4.5、GPT-5 和 o3 模型在这张图表上的总 Flop 次数,或者说在 MMLU 测试中的得分。GPT-5 的 Flop 次数大概在 1 x 1027左右,应该会逐渐接近 MMLU 测试的 100%,这意味着它不再是一个有用的测试,正如 Ho 在演讲中指出的那样,虽然没有给出精确的数字。(一些人认为 MMLU 测试本身存在缺陷,不可能获得超过 93.5% 的得分。)o3 混合专家或思维链推理模型的 Flop 次数可能在 1 x 1026左右波动,上下浮动。
作为数据收集爱好者,我们喜欢收集图表,而 Ho 展示的这个图表也很有趣:

这张图表展示了图像识别模型的计算量随时间的变化,从 2012 年拥有 6000 万个参数的 AlexNet 开始,到 2019 年拥有 15 亿个参数的早期 GPT-2 前沿模型,再到拥有 1750 亿个参数的 GPT-3,再到“估计”拥有 1.5 万亿个参数的 GPT-4。(即使这个数字没有公开,何先生肯定知道具体数字。)
Y 轴表示每秒千万亿次浮点运算的总计算量,是对数刻度,因此即使这条线从 GPT-3 到 GPT-4 一直到 2025 年的 GPT-5 趋于平缓(推理技术开始嵌入到专家混合模型中),我们看到的仍然是指数级增长。如果你相信何大一从今天推断出的那条线,那么展望 2030 年及以后,情况也是如此。我们要指出的是,随着模型规模的扩大,即使指数曲线不那么陡峭,也能提供这种计算能力,这在经济上也是可行的,因为模型使用的数学单元和数据格式的浮点和整数精度不断降低。即便如此,训练这些模型的成本仍然高得离谱,除了 Nvidia 和像 OpenAI 这样的模型构建者之外,投资回报率尚无定论。

早在2009年,谷歌的路易斯·安德烈·巴罗佐(Luiz André Barroso)和乌尔斯·霍尔泽尔(Urs Hölzle)就发表了一篇名为《数据中心如同计算机:仓库级机器设计简介》(The Datacenter As A Computer: An Introduction To The Design Of Warehouse-Scale Machines)的论文,引起了轰动。但何先生谈论的是构建全球规模的计算机。如今,OpenAI和谷歌、微软、亚马逊等公司打造的全球规模计算机似乎还不够,他们还打算构建一台能够运行代理型人工智能工作负载的计算机,这些工作负载能够以计算机速度运行,真正执行任务,而不是以人类的速度告诉我们应该知道什么或应该做什么。
何先生说,这将对基础设施及其系统架构产生巨大影响。

何先生在 AI 基础设施峰会主题演讲中是这样说的:
“我看到的最大变革之一是,我们正在走向一种代理式工作流程,这意味着大部分工作将由代理在众多代理之间完成,”何先生解释道。“事实上,许多代理都是长寿命的,这意味着你与一个代理会进行一次会话。在过去,你与 ChatGPT 的聊天结束,然后返回,中间它不会做任何事情。我们将进入一种代理真正活跃的状态——即使你没有输入任何内容或询问任何内容,由于任务可能很长或很困难,它也需要在后台运行。那么这意味着什么呢?长寿命会话意味着基础设施将需要有状态的计算,并且我们需要内存来支持它。”
我们必须在这些系统中配备实时工具,这意味着这些代理需要彼此沟通。他们中的一些人可能正在查看工具,一些人可能正在进行网站搜索。其他人在思考,还有一些人需要互相交流。我们需要低延迟的互连,以便这些工具能够真正同步,并真正执行正确的操作。这些任务会持续很多天,而且处理量会非常大。当我们有大量任务时,尾部延迟将变得至关重要。如果一个代理在外,并且它有一些其他代理需要了解的重要信息,而该代理需要时间才能回来,那么这可能会影响结果。
何先生表示,目前在网络方面的人工智能系统设计中存在着“很大的紧张”,我们认为这是一种恰如其分的轻描淡写。
未来人工智能系统在计算、网络和存储方面还存在其他矛盾,Ho 一口气说出了这些问题,但没有透露 OpenAI 及其合作伙伴将如何解决这些问题:
HBM4和HBM4E显存容量和显存带宽的墙以及CXL内存池的使用尝试缓解部分压力。
2.5D 和 3D 芯片集成,将组件塞入大于芯片标线极限的区域
共封装和近封装光学器件可克服 XPU 和交换机铜互连的限制
CPU、XPU 和 NPU 混合的计算异构性
总功率远高于 100 千瓦的机架规模系统需要直接对芯片进行液体冷却,并且可能需要浸入式冷却,因为在不久的将来,每个机架的功率将上升到 600 千瓦,甚至达到 1 兆瓦。
许多供应链问题,例如基板和 HBM 内存短缺、全球 EUV 工具分布不均。
不信任的根源
所有大型模型建造商的一大主题(也是有争议的)是协调性,这与模型在生产中运行时的安全性和可靠性有关。
“它必须融入硬件,”何先生宣称。“如今,很多安全工作都集中在软件上。它假设你的硬件是安全的。它假设你的硬件会做正确的事情。它假设你可以切断硬件的电源。我不是说我们不能切断硬件的电源,但我要告诉你,这些东西很狡猾,这些模型真的很狡猾,所以作为一个硬件专家,我想确保这一点。”
对此,何先生建议将实时终止开关集成到AI集群的编排结构中。他还建议在硅片中安装遥测技术,以检测异常的计算和内存模式,并在CPU和XPU中设置安全区域,并建立可信执行路径,以便在芯片级执行对齐策略。
“我认为我们需要一个适应新时代的全新基础设施,”何先生在演讲中总结道。“我们目前还没有针对代理感知架构和硬件的良好基准,我认为了解延迟墙和延迟尾部、效率、功耗等等非常重要。我们需要将良好的可观察性作为一项硬件特性,而不仅仅是作为一种调试工具,而是内置于硬件中并持续监控。网络至关重要,而随着我们迈向光纤网络,目前尚不清楚网络的可靠性是否足够。我们需要对这些光纤测试平台和其他通信测试平台进行充分的测试,以证明我们确实拥有可靠性,从而实现这一目标。”
何先生在演讲中还指出,他希望看到代工厂、封装商、超大规模计算提供商和云构建商之间的合作,以协调关键组件的双重采购。何先生没有时间讨论这个问题,但对于 OpenAI 来说,这比任何一方给予都更容易。
参考链接
https://www.nextplatform.com/2025/09/10/openai-lays-out-the-principles-of-global-scale-computing/
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()











