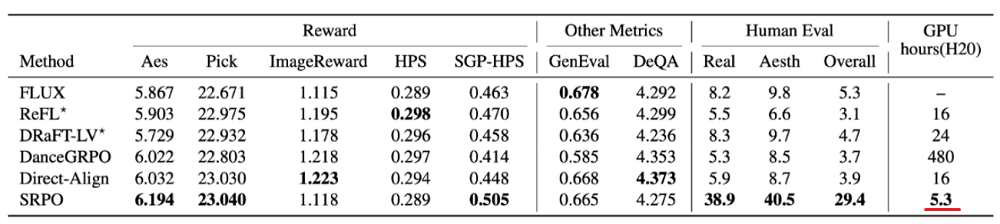
训练效率提升75倍。作者 | 陈骏达编辑 | 心缘那些画风“油腻”的AI生图,终于有救了?智东西9月16日报道,腾讯近期开源势头太猛了,最新发布的图像模型算法SRPO登上Hugging Face趋势榜首,并在趋势榜前3占2。目前Hugging Face模型趋势榜前6中,有5个均来自国内企业,被腾讯、百度、阿里包揽。SRPO由腾讯混元生图团队联合香港中文大学(深圳)、清华大学联合开发,9月13日开源,已发布完整训练代码及技巧,社区量化版本下载量达1.6万次,Github Star数量超过600。SRPO的全称是Semantic Relative Preference Optimization(语义相对偏好优化),旨在解决当前开源社区中热门AI生图模型Flux生成人像时皮肤质感差、过于油腻的问题。通过在线调整奖励偏好、优化早期生成轨迹等手段,SRPO可改善图像生成效果,能将模型生成图片的真实度、美学优秀率的人类评估提升超300%。▲Flux与SRPO生成效果对比在取得更好效果的同时,SRPO大幅提升了训练效率,在32卡设置下,仅需10分钟(5.3GPU卡时)就可以完成训练,效率相比DanceGRPO提升了75倍。开发者可在ComfyUI中使用SRPO,仅需将下图导入ComfyUI即可获取完整工作流,或者直接加载SRPO-workflow的JSON文件。目前,SRPO已被上传至Hugging Face、Github等开源托管平台,相关技术报告已发布。论文链接:https://arxiv.org/abs/2509.06942项目主页:https://tencent.github.io/srpo-project-page/GitHub:https://github.com/Tencent-Hunyuan/SRPOHugging Face:https://huggingface.co/tencent/SRPO开源社区还在其基础上制作了多个量化版本。量化版本链接:https://huggingface.co/wikeeyang/SRPO-Refine-Quantized-v1.0https://huggingface.co/befox/SRPO-GGUFhttps://huggingface.co/rockerBOO/flux.1-dev-SRPO01.引入新型采样策略给去噪提供“标准答案”在SRPO中,研究团队引入了一种用于扩散微调的新型采样策略Direct-Align,可以有效地恢复高度噪声的图像,从而使优化过程更加稳定且计算要求更低,尤其是在初始时间步骤中。当前主流的方法主要依赖多步采样器(如DDIM)结合直接梯度反传来将生成过程与奖励偏好对齐,计算成本高且容易出现梯度爆炸和优化不稳定。因此,现有方法通常只能优化生成轨迹的后半段。这种“仅优化后半段”的策略极易导致奖励模型在高频信息上的过拟合问题。实验结果表明,模型会逐渐学会“钻奖励模型的空子”——具体表现为:HPSv2奖励模型会偏好偏红色调的图像,PickScore倾向于紫色图像,而ImageReward则容易对过曝区域给出过高评分。SRPO的研究团队发现,解决采样瓶颈的秘密就在于扩散模型的前向公式:中间图像是噪声和干净图像的插值。这一发现表明只要掌握噪声先验的参考信息,就可以通过精确插值重建扩散轨迹上的任意中间状态。基于这一理论发现,该团队创新性地提出了Direct-Align方法:首先对输入图像进行可控的噪声注入,随后通过单步模型推理,最后借助预先注入的噪声作为“参考锚点”进行图像重建。这种带有“标准答案”的去噪方式,相比ReFL等直接依赖模型预测的传统方法,显著降低了重建误差,实现了更精准的奖励信号传导。02.有效避免奖励破解给模型加上“语义方向盘”SRPO的研究团队改进了直接利用奖励信号进行反向传播的方法(例如ReFL和DRaFT)的训练策略,并直接使用负奖励对模型进行正则化,无需KL散度或单独的奖励系统。同时,该团队还首次在模型中加入了动态可控的文本条件,能够在奖励模型范围内动态调整对风格的奖励偏好。上述调整的原因是,文生图的在线强化学习方法(如ReFL、DRaFT)通过直接采样图片并反传可微奖励梯度,训练效率高,但高度依赖预训练奖励模型,这些模型难以满足多样化、高质量的后训练需求。例如,用旧奖励模型优化新架构(如SD3、Flux)或提升特定美学维度时,效果有限。传统做法需大量离线优化、微调奖励模型或手工设计复合奖励函数,耗时且难以快速应对新需求。SRPO的研究团队发现,当前主流的图像-文本双分支奖励模型,可以视为以文本分支的输出为模型参数关于图片特征的函数。这样一来,通过调整文本分支的语义特征,就能有效引导整个奖励模型的偏好方向。基于此,SRPO的研究团队性提出了“语义引导偏好”机制,通过为奖励模型添加特定的控制提示词(如“真实感”)来定向调整其优化目标。实验结果显示,某些精心设计的控制词能够增强奖励模型在真实感等特定维度的优化能力。然而,研究团队进一步发现,单纯的语义引导仍存在奖励破解(reward hacking)的风险,而奖励偏差主要源自图像分支(因为文本分支不参与梯度反传)。针对这一问题,团队提出了创新的“语义相对偏好优化”策略:同时使用正向词和负向词作为引导信号,通过负向梯度有效中和奖励模型的一般性偏差,同时保留语义差异中的特定偏好。在具体实现上,为了平衡训练效率和负向词强度,团队采用了加权奖励公式的设计,其实现机制类似于无分类器引导(classifier-free guidance)。实验结果显示,SRPO显著增强奖励模型在真实度等特定维度的优化能力。这一突破性方法为长期受困于高质量数据获取难题的研究者,提供了一条更加直接高效的优化路径,有望显著降低模型优化的门槛和成本。03.美学优秀率、真实度提升超300%未出现明显奖励破解SRPO的研究团队在HPDv2基准测试上对方法进行了评估。HPDv2是一个文生图领域广泛使用的基准,用来衡量模型生成图像的质量,特别是与人类偏好(human preferences)对齐的程度。在测试中,Direct-Align方法在Aesthetic predictor v2.5(AE)、PickScore等主流评测指标上均已达到SOTA水平,而结合SRPO后,在AE和PickScore等关键指标上更是取得明显提升。在人类评估方面,与Direct-Align等直接优化奖励偏好的方法不同,SRPO不会因奖励破解而牺牲真实感,能够在不依赖额外训练数据的情况下,将模型的美学优秀率从8.2%提升至38.9%,提升幅度超过300%,图像感知真实度提升同样超过300%。用SRPO增强后的FLUX.1.dev超过了最新的开源模型FLUX.1.krea,仅需不到1500张图像即可实现有效训练。更为关键的是,SRPO未出现明显的奖励破解现象,验证了Direct-Align的设计能够有效去除奖励偏差,模型真实感显著提升。在主流奖励模型上,SRPO也未出现偏色等奖励破解问题。SRPO具备细粒度的人类偏好优化能力,通过引入控制词能够显著提升在常见风格(如亮度调整、漫画、概念艺术)上的可控性,但在低频风格(如赛博朋克)中则受到奖励模型识别能力的限制。最后,研究还发现Direct-Align具备类似监督微调的拟合特性,当结合真实照片作为离线数据时,SRPO能进一步增强图像真实感。04.结语:系统提升扩散模型真实感可控性与可解释性将成优化方向与单纯的数据拟合方法不同,SRPO同时整合了人类偏好信号与强化学习优化。SRPO研究团队认为,这是首个大规模扩散模型中系统性提升真实感的完整方法。不过,SRPO在可控性和可解释性上仍存在一定局限。该团队计划通过更系统的控制策略、可学习的控制词以及针对控制信号优化的视觉语言模型奖励来提升方法的可控性与泛化能力。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)