
近期,西安交通大学陕西省大数据知识工程重点实验室刘欢团队提出并发布了LibEER,这是一个专门针对脑电情绪识别(EEG-based Emotion Recognition, EER)领域的全面实验基准及开源算法库。LibEER整合了多个常用EEG情绪数据库,并在统一框架下复现和评测了17种代表性算法,旨在为EER领域提供系统化、标准化、可复现的研究平台。

西安交通大学刘欢副教授为第一作者。西安交通大学计算机科学与技术学院博士研究生张玉哲和杭州电子科技大学张大林教授为共同通讯作者。西安交通大学为第一作者单位和通讯单位。论文得到了清华大学刘永进教授和上海交通大学吕宝粮教授的大力支持。
该论文已发表在IEEE Transactions on Affective Computing,题目为《LibEER: A Comprehensive Benchmark and Algorithm Library for EEG-based Emotion Recognition》,DOI:10.1109/TAFFC.2025.3605833。
01
研究背景
脑电图(EEG)因其非侵入性、低成本和高时间分辨率的特点,在情感计算、脑机接口、心理健康等领域具有重要价值。基于EEG的情绪识别是其中的核心任务之一。然而,该领域长期面临三方面挑战:
·缺乏统一基准:不同研究在数据预处理、训练/测试划分和评估指标上差异显著,导致结果难以直接比较,甚至可能出现“数据泄漏”。
·缺乏系统化复现:许多方法仅停留在论文层面,代码没有开源或仅部分开源,给后续研究带来极大复现困难。
·缺乏大规模分析:虽然已有综述性工作总结了不同方法,但缺少在统一实验框架下的大规模实证对比。
这些问题使得EER的研究存在结果不可复现、难以公平比较的困境,严重制约了领域的发展。基于此,研究团队提出并构建了LibEER,为该领域奠定了统一的研究标准。
02
实验基准构建
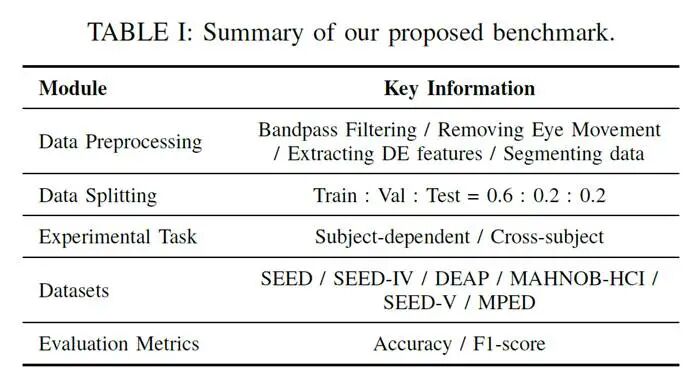
表1.所提出实验基准汇总

表2.所选基线方法的详细信息
为实现公平、可复现的比较,研究团队设计了一个系统化的统一实验基准,如表1中所示,具体包含以下几个部分:
·基线方法选择(Baseline Selection):研究团队先系统梳理近一年在该领域高水平会议和期刊发表的60篇高质量论文,汇总得到205个常用对比方法,按被选择为基线方法的次数排序筛出前20个方法并添加了部分最新的方法进行复现;在确保各类型(CNN、RNN、GNN、DNN、Transformer)模型都包含的前提下,以“复现实验结果相对原文误差不超过10%”为硬性标准最终确定17个代表性模型作为基线方法,具体模型如表2所示。
·数据预处理与划分(Data preprocessing and Splitting):研究团队制定统一且可复现的预处理流程:先对原始脑电实施0.3至50赫兹带通滤波,再以主成分分析法去除眼动伪迹,随后在五个标准频段(0.5–4、4–8、8–14、14–30、30–50赫兹)提取差分熵特征并用线性动态系统进行平滑,最后按1秒无重叠滑窗切分形成样本;数据划分统一采用训练、验证、测试三段式比例为0.6、0.2、0.2(考虑试次数较少且类别较多的情形,SEED-V按三等分执行),并严格遵循跨试次不泄漏原则,确保同一试次的样本不会同时出现在训练、验证或测试之中。
·实验任务(Experimental Tasks):研究团队聚焦于两类最具实际意义的任务设定:被试内(Subject-dependent)与跨被试(Cross-subject)。被试内在同一被试范围内按试次完成训练、验证与测试,用于衡量个体化建模上限;跨被试则将训练、验证与测试严格置于不同被试之间,以检验跨个体的泛化能力。
·数据集(Datasets):研究团队在统一基准中纳入六个最常用且质量可靠的公开数据集,覆盖多种情绪范式与采样设置:SEED、SEED-IV、DEAP、MAHNOB-HCI、SEED-V与MPED。这些数据集覆盖了不同的实验范式、采集条件和被试群体,保证了结果的多样性和代表性。
·评价方法与指标(Evaluation Methods and Metrics):所有模型的最终测试结果均来自“在验证集F1值最高的那一轮权重”在测试集上的表现,避免“逐epoch在测试集取最好”的不当做法;每次实验固定随机种子为2024,并报告Accuracy与F1的均值±标准差,从而在模型选择、结果统计与随机性控制三个层面同时保证公平性与可复现性。
03
研究结果与分析
1.模型复现(Model Reproduction)
 表3. 所有基线模型的复现实验结果
表3. 所有基线模型的复现实验结果研究团队首先对17个基线模型进行了复现实验验证,即严格按照原论文汇报的实验设置进行实现结果复现。结果如表3所示,大多数模型的复现表现与原论文差异较小,平均误差仅为3.85%,最大差异不超过10%。这证明了LibEER在模型代码复现上的可靠性。
2.模型对比(Model Comparison)

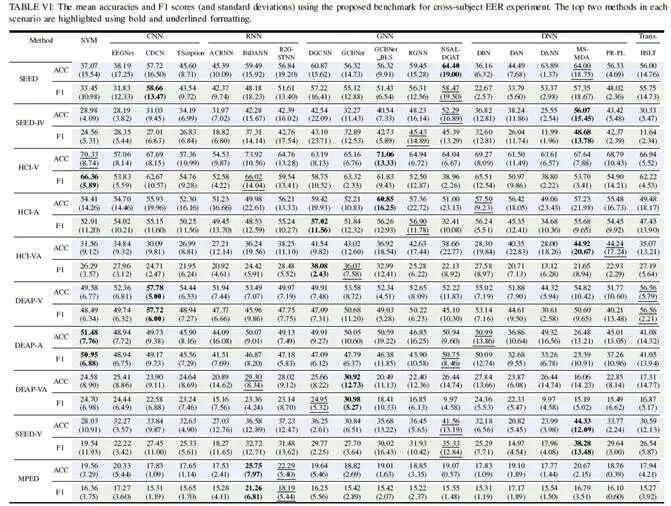
表4.所有基线模型在所提出的统一实验基准下的对比实验结果
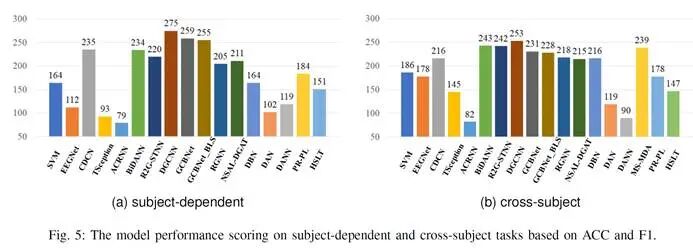
图1. 统一实验基准下各基线模型性能评分
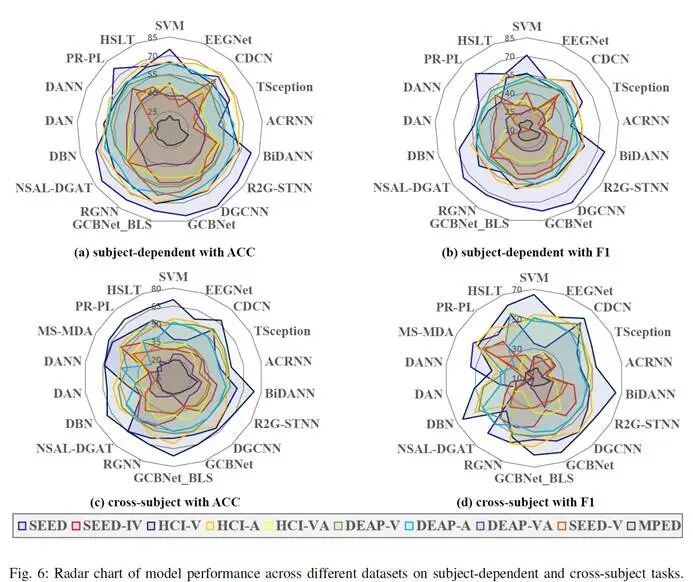
图2. 基线模型在不同数据集上的表现雷达图
基于所提出的统一实验基准,研究团队对所有基线方法进行了对比实验,实验详细结果如表4所示。为更直观地进行对比和分析,将各基线模型按照在各场景下的性能排名进行评分,结果如图1所示。此外还展示了基线模型在不同数据集上的表现雷达图如图2所示。通过大量的对比实验结果,研究团队总结出以下关键发现:
·时空建模与迁移学习是当前的关键突破方向。从图2中的评分结果可以发现,能够显式建模通道关系与时间动态的模型表现出显著优势。其中,基于图神经网络的模型(如DGCNN、GCBNet)以及基于循环神经网络的模型(如BiDANN、R2G-STNN)取得了最好的综合性能。同时,迁移学习的引入有效缓解了跨被试差异,显著提升了模型在跨场景下的泛化性能。因此,建议优先采用兼具脑电时空建模能力并结合迁移学习的技术路线。
·跨被试差异仍然是当前的核心挑战。研究团队在“被试内”与“跨被试”两种主流设定下的对比结果可以看出:被试内结果的标准差普遍高达约15–20%,而跨被试的整体准确率与F1值明显偏低。这说明现有方法尚未从根本上解决因个体差异引起的性能不稳定和退化问题。要实现进一步突破,需持续致力于个体差异建模、鲁棒适配方法以及稳定验证协议的研究。
·数据规模不足制约了深度表示学习的效果。研究团队在多数据集上的对比显示,在训练样本有限且缺乏严格验证集控制的情况下,部分深度学习模型的性能甚至不及传统SVM方法。其根本原因在于脑电数据规模较小、标注成本高且模型容易过拟合。可行的改进路径包括:在统一基准框架下系统引入数据增强、正则化与早停/验证策略,同时结合更高效的参数化方法与预训练机制,以增强深度模型的表征学习与泛化能力。
·数据采集范式直接影响任务难度与性能上限。研究团队通过多数据集的雷达性能图分析发现,在标注清晰、类别分布均衡的数据集(如SEED系列)上,各类方法整体表现更稳定、F1值更高;而在DEAP和HCI这类涉及连续效价-唤醒评分、标签主观性强、刺激预期不受控的数据集上,模型性能普遍下降;MPED则因情感类别划分最为细致,成为检验现有方法泛化能力的难点场景。这一结果提示,未来的评测体系与方法设计需同时关注更准确的标注规范、更严格的数据采集协议,以及更丰富的情感粒度刻画。
3.实验设置讨论(Discussion of Experiment Settings)
研究团队围绕实验设置中的四个关键因素开展了系统对比,主要结论如下:
·样本划分时长:在被试内设定下,较短的划分时长(如1–3秒)通常能够带来更高的ACC与F1值,因为这显著增加了可用的训练样本量;而在跨被试设定下,不存在统一最优时长,需在样本数量与时窗稳定性之间进行权衡。
·特征与预处理方法:微分熵(DE)与功率谱密度(PSD)两类特征在基线模型中表现接近,但经局部域自适应(LDS)处理后,两者性能均显著提升。在跨被试场景中,原始DE特征的劣势更为明显,进一步凸显了“LDS+频谱特征”这一组合的优越性。
·训练与评估策略:采用验证集最佳性能作为模型选择依据的方案最终获得的性能的整体稳定性最高,平均性能最优;相比之下,仅使用末轮训练结果或简单早停阈值策略容易受到随机偶然性和过拟合的影响。
·随机种子稳定性:随机种子对模型结果具有实质性影响,不同模型在不同种子下的性能波动可达10%–20%。因此,统一并公开随机种子设置是保证公平比较和结果可复现性的必要条件。
04
结论
研究团队所提出的LibEER为脑电情绪识别领域研究建立了一套清晰、统一且合理的实验基准。该基准在六个常用公开数据集上规范了数据预处理流程,采用严格的被试内与跨被试划分方式,并统一了训练、验证、测试的评估路径,同时以验证集性能最优为依据进行模型选择。此外,LibEER还在PyTorch框架下复现了17个具有代表性的深度学习方法,确保了横向对比的公平性和透明度。基于该基准所进行的大规模复现实验、系统对比与关键实验设置的对比分析,共同揭示了当前EER领域各类方法的优势与局限,为后续模型设计和技术应用提供了可靠的实证依据与参考标准。该研究为EER领域奠定了新的标准化基础,标志着脑电情绪识别研究向规范化和透明化迈出了关键一步。未来,LibEER会进一步扩展更多数据库和算法,支持跨数据集、跨任务等实验设计,并推动EER在教育、心理健康、临床诊断和人机交互等应用中的发展。
仅用于学术分享,若侵权请留言,即时删侵!
欢迎加入脑机接口AI星球
获取更多脑机接口+AI等领域的知识和资源。

加群交流、商业合作请添加微信:RoseBCI【备注:姓名+行业/专业】。
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBCI
点击投稿:脑机接口社区学术新闻投稿指南
2.加入社区成为兼职创作者,请联系微信:RoseBCI


一键三连「分享」、「点赞」和「在看」
不错过每一条脑机前沿进展










