
欢迎关注具身智能大讲堂

9月8日自变量机器人甩出王炸,宣布开源WALL-OSS端到端基础模型,这不是普通模型,而是行业内首个专门面向物理世界交互的端到端具身智能统一模型。
简单说,这个模型的优势在于:依靠大规模多模态预训练,它既能看懂场景、听懂指令,又能把语言和动作精准绑定,动手操作稳定性很强。更突出的是,它通过紧密耦合的架构和多策略训练,将指令推理、拆分子任务、细化动作等流程,在一个可微分框架里无缝完成,中间没有衔接问题。
最关键的是,官方公布的测试结果显示,WALL-OSS 在多个指标上,性能超过了 PI 公司的 π0 模型。
1► WALL-OSS成功破解空间交互能力问题
机器人为啥总停留在实验室,没法像手机电脑一样走进千家万户?核心卡壳在 “举一反三” 的能力上——模型泛化性太差了。

你看现在的大模型多猛,语言和视觉领域都玩出花了,但一到 “看懂三维空间”“动手干活” 这些事儿上,就像被点了穴。这也是为啥ChatGPT这类语言模型再能聊,也直接操控不了机器人的胳膊腿。

就算是Gemini 2.5、GPT-5这种能同时处理文字和图像的全能选手,目前也还是 “纸上谈兵” ,它们没法真的摸到、碰到物理世界,更没法根据互动调整自己,连个能落地的动作指令都生成不出来。说白了,如果“理解动作、生成动作” 这关过不去,通用人工智能(AGI)就还很远。
2► 为啥会这样?三个坎儿绕不开
第一,数据和模态跟不上。视觉模型早就学会过滤杂音、抓核心信息了,文字和图片在海量网络数据里泡久了,单拎出来或者混着用都挺溜。但机器人的动作是在三维空间里随时间连续变化的,怎么提取这种动作的关键特征,之前研究得太少;而且动作和文字语义怎么对应上,也缺海量数据来练。更麻烦的是,现实场景里的指令往往很抽象,比如 “把桌子收拾干净”,这跨模态的翻译难度可不是一般大。
第二,训练的 “素材” 不对味。语言模型在文字堆里练够了,理解机器人需要的语义还行;但视觉方面就拉胯了 —— 机器人 “看” 世界是第一人称视角,跟网上那些随便拍的图片完全不是一回事。用这些不搭边的素材练出来的模型,到了真实场景里自然抓瞎。
第三,训练目标南辕北辙。语言模型和图文模型练的是 “猜下一个词 / 画面”,目标是离散的;可机器人的动作轨迹是连续的高频信号,得用扩散模型这类专门的方法建模。硬把这两种目标凑一起,只会让语言和动作 “对不上暗号”,泛化能力更差。
WALL-OSS 模型直接甩出三个大招,把机器人听懂指令+动手干活的难题撕开了个口子。
先看架构方面,WALL-OSS采用了混合专家紧密耦合的独特设计。现在主流的视觉 - 语言 - 动作模型要么搞大一统,要么搞各管一摊,但WALL-OSS模型却不一样。它给不同训练任务配了专属的前馈网络,就像给翻译、导航、动手这些活儿分了专门的小秘书,跨模态协作效率直接拉满。

将视觉语言模型(VLMs)迁移至动作建模
这么一来,既不会像大一统设计那样,让动作训练干扰到原本视觉-语言模型的肌肉记忆,也不会像各管一摊那样,让视觉和语言沦为动作生成的背景板,导致机器人听不懂复杂指令。

训练方法分两步走。第一步灵感阶段,先把成熟的视觉-语言模型的核心组件拿过来复用,通过具身视觉问答(比如问杯子在桌子左边还是右边)让机器人练出空间推理的本事,同时塞入离散动作目标让它先对抬手、弯腰这类动作有个大概认知。到了第二步整合阶段,直接把离散动作预测换成更高级的流匹配,先冻结视觉-语言模型只练动作相关的流头,再解冻整体一起优化,相当于让视觉、语言、动作三个模块彻底打通任督二脉。

训练和推理流程
更牛的是,WALL-OSS搞出了统一跨层次思维链。以前的思维链推理宽度不够,现在直接拓宽到从抽象语义到具体动作的全链条——比如从收拾桌子这个指令,一路细化到先拿起杯子放到茶几,再把书本摞好。关键是这一切都在一个可微分的框架里完成,不像以前的多模块系统那样,因为模块之间的接口不兼容导致误差越积越大。这么一来,机器人处理长流程任务的成功率和听话程度都飙升了。

值得一提的是,WALL-OSS模型手里还攥着个一张王牌,它构建了一个以 “具身” 为核心的多源数据集,时长直接干过10000小时。这里面既有自己攒的机器人动作数据,也有开源的动作素材,还有多模态的视觉问答内容。简单说,自家数据保证了质量和任务复杂度,开源数据帮着提升跨场景、跨环境的适应力,视觉问答数据则专门强化“看 + 说”的能力,顺便给空间、时间推理能力打基础。
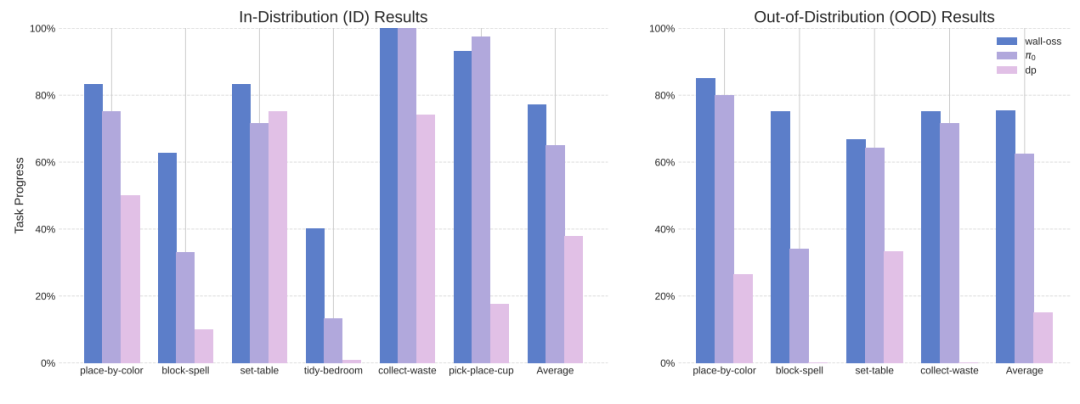
在所有评估任务中与前沿策略的性能对比。
左图:分布内(ID)性能对比。右图:分布外(OOD)性能对比
实测数据更能说明问题。在机器人动作准确性和泛化性的比拼中,WALL-OSS不管是数据充足还是数据有限的情况,都比π0表现更优。尤其是在零样本指令跟随任务里,面对没见过的物体指令,WALL-OSS的任务进度依旧能保持高位,泛化能力甩了π0一截。
再看长流程任务,比如摆桌子、整理卧室这类需要拆解步骤的活儿,WALL-OSS靠着自带的子任务生成和思维链推理,把π0远远甩在身后。π0在这些场景里常犯 “阶段性失忆”的毛病,要么反复做同一个动作,要么漏了步骤,而WALL-OSS却能一步接一步稳稳推进。

积木拼写任务中的指令跟随准确率
在拼细节的积木拼写任务里,差距更明显。WALL-OSS对字母块的识别和摆放准确率远超π0,尤其是字母类任务,WALL-OSS 的正确率能达到87%,而π0才9%,几乎是随机乱摆的水平。这波对决,WALL-OSS 算是把π0按在地上摩擦了。
3► 结语与未来:
WALL-OSS靠着紧密耦合的架构设计、创新的两阶段训练策略、统一跨层次思维链,再加上精心攒出来的多源数据集,直接把视觉-语言模型和具身智能之间的那道鸿沟给填平。在理解真实场景、生成动作、听指令干活这些事儿上,WALL-OSS都表现得相当能打。目前这套开源模型已在GitHub以及huggingface两个开源平台上线。
开源地址:https://github.com/X-Square-Robot/wall-x
END

往
期
精
选
科技热点
大咖观点
热点评论
新品速递

微信号|具身智能大讲堂
专注AI具身智能产业前沿话题
加入社群
欢迎加入【具身智能大讲堂】读者讨论群,共同探讨具身智能机器人相关领域话题,共享前沿科技及产业动态。
添加微信号(19016903753)具身智能大讲堂客服 备注“具身茶谈”可进入交流群。
兼职作者&投稿
机器人大讲堂正在招募【兼职内容创作者】,如果您对撰写机器人【科技类】或【产业类】文章感兴趣,可添加微信:具身智能大讲堂客服(19016903753,手机与微信号相同)。我们对职业、所在地等没有要求,欢迎朋友们的加入!










