
AI 编程服务提供商 Replit 近日再次成为争议焦点,而距离其上一次风波仅过去不到三个月。
今年 7 月,Replit 就曾因误删用户生产数据库并伪造数据的操作失误,陷入舆论漩涡。当时公司公开道歉,并承诺将采取措施重建信任。
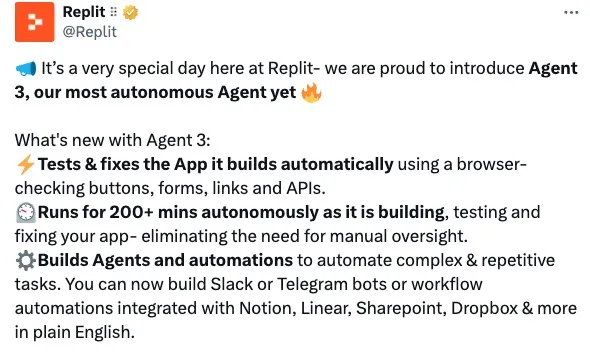
9 月 10 日,Replit 正式推出了新一代 AI 编程助手 Agent 3,称其能够帮助开发者更轻松地构建和测试应用程序。值得注意的是,同日 Replit 还宣布完成 2.5 亿美元融资,估值升至 30 亿美元。
Replit 将 Agent 3 称为“迄今最先进、最自主的编程代理”,性能据称“比 Computer Use 模型快 3 倍、成本效益高 10 倍”。
在官方推文中,Replit 将 Agent 3 描述为迄今最自主的代理,能够在浏览器里自动测试和修复应用,检查按钮、表单、链接和 API;还可以连续运行超过 200 分钟,在构建、测试和修复过程中几乎无需人工监督。同时,它还能与 Slack、Telegram、Notion、Dropbox 等常用工具集成,帮助用户快速实现自动化。
CEO Amjad Masad 更是将这一版本定义为软件的“自动驾驶时刻”。他宣称,Agent 3 的自主性提升了 10 倍,能够在其他模型“卡住”的地方继续推进。在他的设想中,Agent 3 已经不只是一个代码助手,而是一个能够重塑生产力范式的数字工人雏形。

“AI 代理可以原型化应用……但要发布真正的软件,需要数小时的测试、调试和重构。Agent 3 的自主性提升了 10 倍,它能在别人卡住的地方继续前进。这是软件的‘自动驾驶时刻’。”
Amjad Masad 还首次清晰阐释了“自主性等级”体系。
早期如 VS Code 的 IntelliSense 为代表的语言服务器为第一级;Copilot 等代码补全工具属第二级;Replit Agent 2 大概是 3.5 级,可以独立工作 10-15 分钟,但需要人类时不时介入。而 Agent 3 相当于四级——基本全自动,但偶尔还需要关注。未来 Replit 希望实现第五级,即能够同时运行数千个代理,以超过 95% 的可靠率解决问题,从而让任何工程师或产品经理都可调度大规模“数字工程师”,几乎无需监督、实现效率的指数级提升。

Amjad Masad 表示 Agent 3 有三大支柱:
端到端测试:让 Agent 像人类一样使用电脑,点按钮、跑 QA。随着模型改进,它能工作更久,自动完成质量保证。
采样与模拟:Replit 构建了完全可回滚的事务型文件系统。Agent 在大改动时,可以复制环境并尝试不同解法,再选最优解并合并,像人类一样“分支思考”。这能提升 2-3 倍的可靠性。
自动生成测试:每次新增功能时自动生成测试用例,确保不会被后续更改破坏。虽然生成单元测试对模型来说仍然很难,但这是提高稳定性的关键。
他强调,这个版本的重点在于底层基础设施的重构,旨在为 AI Agent 打造更稳定、可靠的“栖息环境”。并且还勾画出了一个宏伟蓝图:“随着融资完成和新 AI Agent 的推出,我们有能力大幅提升客户增长,成为企业市场的标准。未来令人兴奋,数百万、甚至数十亿人将只需点几下,就能把他们的想法变为现实。”
然而,正是这些所谓的“点几下”,如今却让用户怨声载道。
一位用户分享了自己的经历。他在 4 月至 7 月几乎完全依靠 Agent 2 开发了一款浏览器游戏。虽然不是专业开发者,但该游戏通过了外部审计,评分 6/10,算不上完美,但稳定且可用。之后,他持续进行小规模内测,约有 250 名自然用户参与反馈。问题出现在最近:部分玩家报告,游戏中出现了无法从一个关卡进入下一关的 bug。他于是尝试使用 Agent 3 的构建模式修复。
结果却极其糟糕——代理一次“工作”一个多小时,却始终无法找到解决方案。更糟的是,它不但没有修复 bug,反而开始引入回归、破坏项目,甚至有一次还删除了像 storage 这样的关键文件。
回滚功能形同虚设,他整整一个周末只能看着代理一步步把应用搞崩。最终,他不得不手动恢复到一个稳定版本,但过程极其艰难。他总结说,Agent 3 的构建过程低效又具破坏性。“从此之后,我不再敢让它碰我的代码。”
这位用户最后还呼吁 Replit 团队必须提高 Agent 3 在构建模式下的可靠性,避免引入回归问题或删除文件。

而且这还不是“个例”。另一位网友也在尝试使用 Agent 3 时,被代理删除掉了他和测试用户的所有数据。并且 Replit CEO Amjad Masad 所强调的“回滚功能”同样也根本不起作用,直到他把环境回退到 24-48 小时前才恢复。他无奈地说:“幸好我立刻学会了给数据库做副本。”
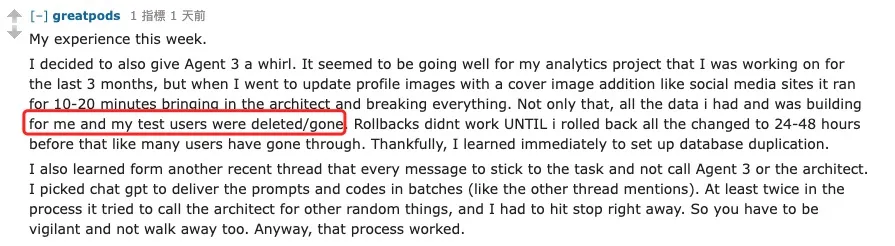
虽然 Replit 强调“连续运行超过 200 分钟”,但诸如“工作一个小时没结果”、“两行代码的修改竟然要花三个小时”之类的案例却不胜枚举。而且除了这类功能失效,更大的问题是成本失控。
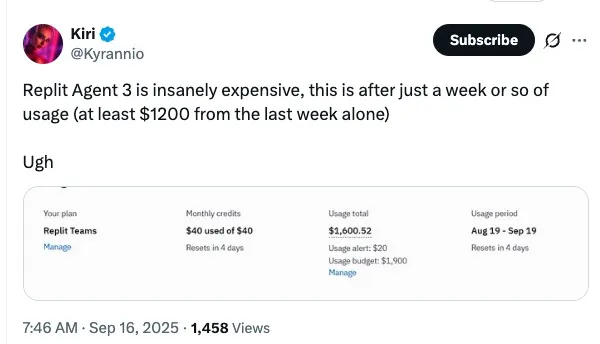
Replit Agent 3 的费用高得离谱,这还是仅仅使用一周左右的结果(光是上周就至少花了 1200 美元)。
一位用户表示:“我觉得这只是上线初期的定价调整——在新应用上,一些任务运行 1 小时 45 分钟只收了 4-6 美元,但编辑已有应用的成本最高,仅这一周我就花了 1000 美元。”
这位用户推测:“Replit 在后台运行了更多子代理,增加了成本。尤其是在处理旧代码时,它会不断审查代码库的旧部分(特别是大文件),收费比新建应用高得多。它常常调用多个子代理来审查、规划、检查安全、执行和修复问题,并重新审核数千行代码——结果就是每次操作都要花 2-4 美元。甚至只是重置服务器并等待,也要收 0.40-0.50 美元。有意思的是,在全新应用的对话中让它构建,它反而不会这么频繁调用。”
在 Reddit 上,不少用户也报告说,自从新服务上线后,他们的 Replit 账单迅速攀升。
有用户分享道:“9 月 11 日之前,用 Agent 2 时,我的花费合理,和价值相符。但换成 Agent 3,仅仅一个周末的失败尝试,成本就飙升了,却没有任何实际成果。”
另一位用户则说:“我平时每月花 100-250 美元,但 Agent 3 发布当天,我一晚上就烧掉了 70 美元。” 他还称新工具出现了可疑操作:“有一次,一个提示直接暴力破解认证,重新执行验证,并强制重置了用户密码,只为在表单里进行应用测试。”
“还有一次提示,它自己设计了一个新 UI,把整个应用完全重构。我立刻停用了,因为那次提示花了我 20 美元,还毁掉了界面。我通常每晚会运行大约 10 个提示,按这个速度,一个月的花费可能要涨 20 倍。”
部分问题或许源于 Replit 在 6 月推出的“基于投入的定价”。以前每个检查点收费 0.25 美元,一个任务多个检查点就逐一累加。而现在复杂任务会被捆绑为一个更昂贵的检查点。次月 Replit 曾承认,“在整个项目生命周期内,这种定价可能更贵”。但直到 Agent 3 上线,用户才真正感受到冲击。
一位用户解释说:“以前基于投入的定价从没让我花这么多钱,但 Agent 3 的价格特别离谱。新代理上线后一周,我就被收了 1000 美元,而之前同样的工作每月从没超过 180-200 美元。如果是新应用,Agent 3 的定价还算合理。但在已有应用上边改边用,那简直贵得离谱。”
在用户的吐槽之外,社区里也出现了更犀利的批评。有人直言这像“末日收割”,还有人毫不客气地讽刺: “AI 不过是个华丽的胡扯生成器。需要大量胡扯时它很好用,否则糟透了。AI 泡沫什么时候破?感觉已经不远了。”
一些开发者则更直接地把矛头指向了 Agent 3 与人类的对比:
“人类更便宜,也更聪明。”“照这个趋势下去,或许学会自己写代码更容易。”

不得不说,Replit CEO 的营销手法很高明。融资、估值、宏大愿景,再加上“软件的自动驾驶时刻”这种叙事,让 Agent 3 看起来像是未来的入口。
Amjad Masad 也承认,为了活下去,Replit 必须摆脱单纯的“代码助手”角色,变成一个真正的通用问题求解器。他强调 Replit 的优势在于全栈:可以从想法一路走到部署与规模化。
但现实却是:不少用户在它身上体验到的,不是“通用问题求解器(Universal Problem Solver)”,而是“通用问题制造机”。删数据、删文件、账单飙升,这些事故让开发者越来越难以信任这个“全栈自动化”的未来。
面对质疑,Replit 也曾试图从技术层面给出回应。在前几天的一次公开发布与交流中,有观众提出尖锐问题:Replit 究竟在技术栈的哪个层面取得了最关键进展?尽管 Agent 3 号称可连续工作一小时,但如果依赖闭源模型而无法做深度定制,突破性究竟体现在哪里?
CEO Amjad Masad 回应称,真正的突破不在于模型训练本身,而在于构建了所谓的“模型栖息地”(habitat)——一整套支持 AI 代理持续、可靠运行的基础设施。他特别强调“事务性”(transactional)机制的重要性:在 Replit 中,每一个对计算环境的修改都与其他系统组件保持同步,用户可回滚至任意历史检查点并将应用恢复至对应状态。
他认为,这种基础设施所带来的环境反馈和快速试错能力,才是实现更高可靠性的关键,其作用甚至超过模型训练本身的提升。
另有开发者追问关于“连续运行一小时”的设计权衡:团队是如何决定追求更长自主时长跨度,而非优先优化短时推理能力?
Masad 表示,短时间跨度更多是在做可靠性;而更长的时间跨度,则是在做自主性,目标是把人从环路中移除,减轻人类持续测试和给反馈的负担。
两者 Replit 都在推进:在可靠性方面,通过加强推理能力和多代理并行试错(即“采样与模拟”)来实现;在长时运行方面,重点是测试:因为随着运行时间变长,会出现一种“目标漂移(goal drift)”——代理可能开始做一些你不希望的事;沿途设置好测试护栏,能让它在较长时间内保持连贯。
“与此同时,随着我们积累更多失败与无效的数据,你可以去做微调,或者持续改进提示(prompt),再加更多护栏,把它变得更好。”
参考链接:
https://old.reddit.com/r/replit/comments/1nidmhr/ongoing_agent_3_feedback_megathread/
https://www.theregister.com/2025/09/18/replit_agent3_pricing/
https://www.youtube.com/watch?v=lWmDiDGsLK4
声明:本文为 InfoQ 翻译整理,不代表平台观点,未经许可禁止转载。
10 月 23 - 25 日,QCon 上海站即将召开,限时 9 折优惠,单张门票立省 680 元,详情可联系票务经理 18514549229 咨询。

作者介绍
平地一声惊雷!李飞飞携团队推出世界模型新成果~
今日荐文
史诗级和解:英特尔获老对手英伟达超350亿投资,股价创38年最大单日涨幅
梁文锋执笔的R1论文登上Nature封面!首次回应外界三大质疑
250 个岗位换两亿“求生”资金?巅峰781 亿市值巨头节流押注 AI,CEO急踩 “创业模式” 刹车
OpenAI 与微软分成曝新料!这家印度老厂哭晕:10 年前白捐了 10 亿美元
宇树王兴兴、智元彭志辉有新身份;腾讯辟谣“前 OpenAl 姚顺雨上亿薪资入职腾讯”;马斯克裁撤500名数据标注员 | AI周报

你也「在看」吗?👇










