点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:我爱计算机视觉
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

今天要介绍的论文是来自苏黎世联邦理工学院、南洋理工大学等机构的研究者们发表在 IEEE TPAMI 2025 上的工作。该研究创新性地将近期在生成任务中大放异彩的 扩散模型(Diffusion Model) 引入了多视图立体(Multi-View Stereo, MVS)领域,提出了一种全新的 MVS 框架。
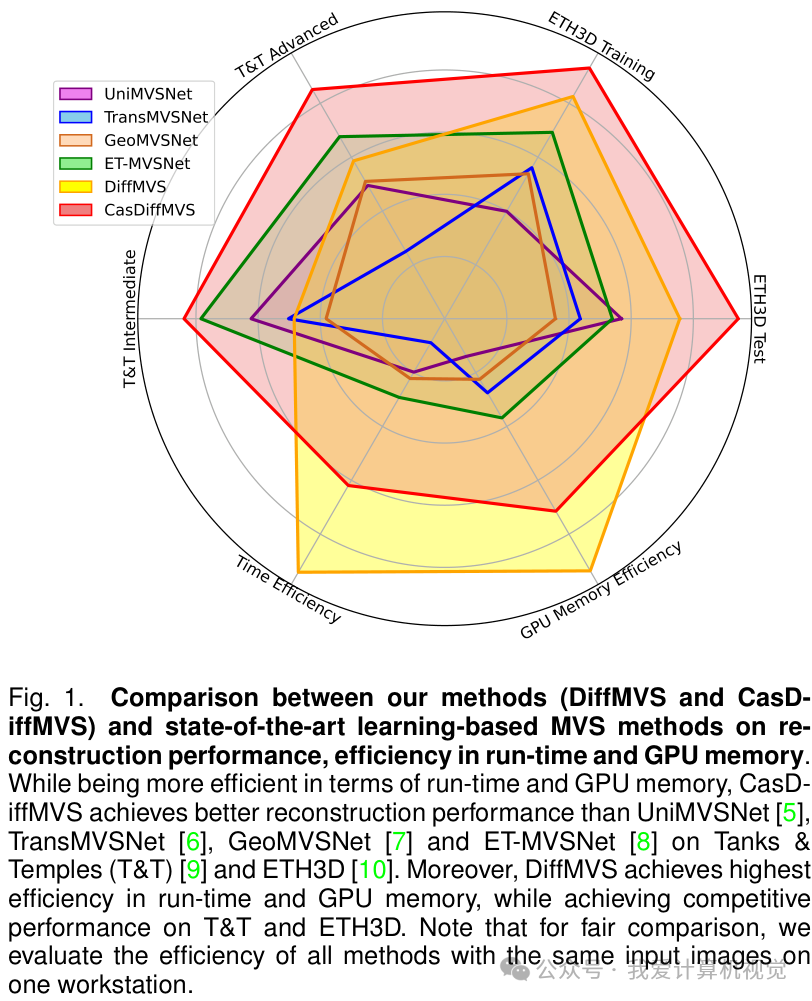
基于此框架,论文推出了两种新方法:DiffMVS 和 CasDiffMVS。这里的 "Diff" 代表 "Diffusion","Cas" 代表 "Cascade",表明了其技术核心。DiffMVS 旨在实现极致的效率,在运行时间和 GPU 内存方面达到业界顶尖水平;而 CasDiffMVS 则追求最高的精度,在多个主流 MVS 基准测试(如 DTU, Tanks & Temples, ETH3D)上均取得了 SOTA(State-of-the-Art) 的性能。
这项工作通过将深度图细化过程建模为条件扩散过程,并设计了一系列创新模块,成功地平衡了三维重建的效率与精度,为 MVS 领域带来了新的思路和强大的基线模型。

论文标题: Lightweight and Accurate Multi-View Stereo with Confidence-Aware Diffusion Model 作者: Fangjinhua Wang, Qingshan Xu, Yew-Soon Ong, Marc Pollefeys 机构: 苏黎世联邦理工学院,南洋理工大学,新加坡科技研究局(A*STAR),微软 论文地址: https://arxiv.org/abs/2509.15220 代码地址: https://github.com/cvg/diffmvs 录用信息: Accepted to IEEE TPAMI 2025
研究背景与意义
多视图立体(MVS)技术旨在从不同视角的校准图像中重建场景的三维几何,是机器人、自动驾驶、虚拟/增强现实等领域的关键技术。
传统的学习式 MVS 方法通常采用“深度估计+深度图融合”的流程。为了提高效率和精度,许多先进方法采用“从粗到细”(coarse-to-fine)的策略:首先在低分辨率下估计一个粗略的深度图,然后逐步在高分辨率下进行细化。然而,这种策略高度依赖初始粗略深度图的质量,一旦初始估计出错,后续的细化过程很难纠正,容易陷入局部最优。
近年来,扩散模型作为一种强大的生成模型,通过从随机噪声中迭代去噪来恢复数据样本,在图像生成等任务上取得了巨大成功。其引入随机扰动的特性,天然具有跳出局部最优的能力。
作者受到启发,思考能否将扩散模型的这种“去噪生成”范式引入 MVS 的深度细化过程,从而克服传统方法的局限性。然而,将用于生成任务的扩散模型应用于具有判别性质的深度估计任务,面临着三大挑战:
扩散条件: 如何为扩散过程提供有效的几何约束和引导? 扩散采样: 如何在采样过程中利用非局部信息以实现更精确的优化? 扩散效率: 如何在保证性能的同时,避免经典扩散模型(如大型U-Net)带来的高计算开销?
本文正是为了解决这些挑战,提出了一套完整的基于条件扩散模型的 MVS 框架。
核心方法
论文提出的新框架包含两个核心模块:深度初始化和基于扩散的深度细化。整个流程分为单阶段细化的 DiffMVS 和级联细化的 CasDiffMVS。

深度初始化
与许多 MVS 方法类似,该框架首先在一个较低的分辨率(例如1/8)下生成一个初始的粗略深度图。这一步通过构建一个轻量级的 3D 代价体(Cost Volume),并使用一个 3D U-Net 进行正则化来完成,为后续的细化提供一个起点。

基于扩散的深度细化
这是本文最核心的创新。作者将深度图的细化过程建模为一个 条件扩散过程。它不是从纯噪声开始,而是从一个带噪声的粗略深度图出发,通过迭代去噪来预测深度残差,从而逐步逼近真实的深度值。
为了实现高效且准确的细化,作者设计了三个关键组件:
1. 条件编码器(Condition Encoder)
为了让扩散模型理解几何信息,作者设计了一个条件编码器。它融合了三种关键信息作为引导扩散过程的条件:
几何匹配信息: 从局部代价体中提取。 深度上下文特征: 从当前的深度假设中提取。 图像上下文特征: 从参考图像中提取,提供场景的语义信息。
通过这种方式,扩散模型不仅能感知局部像素的匹配程度,还能利用长距离的上下文信息,从而在弱纹理或遮挡区域做出更鲁棒的估计。

2. 轻量级扩散网络
传统的扩散模型通常使用庞大的 U-Net 结构,计算成本高。为了提高效率,作者提出了一个新颖的扩散网络,它巧妙地将一个轻量级的 2D U-Net 与 卷积门控循环单元(Convolutional GRU, ConvGRU) 结合起来。ConvGRU 能够以迭代的方式更新隐藏状态,有效捕捉时序(在本文中是迭代细化步骤)信息,从而在单个扩散时间步内实现多次细化更新。这种设计既提升了性能,又避免了堆叠多个大型 U-Net 带来的高昂计算开销。

3. 基于置信度的采样策略
为了更智能地探索深度假设空间,作者提出了一种基于置信度的自适应采样策略。在每次细化迭代中,模型会预测当前深度估计的置信度。
对于 高置信度 的像素(通常是估计得比较准的),采样范围会缩小,以进行精细微调。 对于 低置信度 的像素(可能估计错误),采样范围会扩大,以增加找到正确深度值的机会。
这种自适应策略使得模型能够将计算资源集中在最需要的地方,有效地提供了优化所需的一阶信息,加速了收敛并提升了精度。
 上图展示了参考图像、预测的深度图、深度误差图和置信度图。可以看到,置信度图(右下)能够很好地反映深度误差的分布(左下),高置信度区域(亮色)对应着低误差区域。
上图展示了参考图像、预测的深度图、深度误差图和置信度图。可以看到,置信度图(右下)能够很好地反映深度误差的分布(左下),高置信度区域(亮色)对应着低误差区域。
实验与结果分析
作者在三个主流的 MVS 数据集上对提出的 DiffMVS 和 CasDiffMVS 进行了全面评估,并与当前最先进的方法进行了比较。
在 DTU 数据集上的表现
DTU 是一个经典的室内场景 MVS 数据集。如下表所示,CasDiffMVS 在“Overall”指标上取得了极具竞争力的结果,超越了许多经典的 SOTA 方法。而 DiffMVS 作为一个单阶段细化方法,其性能也超过了同样是单阶段细化的 IterMVS,并逼近许多更复杂的多阶段方法。

在 Tanks & Temples 和 ETH3D 上的泛化能力
Tanks & Temples 和 ETH3D 是更具挑战性的大规模真实世界场景数据集,用于测试模型的泛化能力。
在 Tanks & Temples 数据集上,CasDiffMVS 在中级和高级子集上均取得了 SOTA 性能,其 F-score 显著优于其他方法。

下图展示了在 Tanks & Temples 上的定性比较,CasDiffMVS (Ours) 生成的三维点云(最右列)在完整性和细节上都优于其他方法,例如在 "Horse" 场景中马腿部分的重建以及 "Temple" 场景中廊柱的完整性。

在同样具有挑战性的 ETH3D 数据集上,CasDiffMVS 再次展现了其卓越的性能,在训练集和测试集上的 F1-score 均达到了 SOTA 水平。
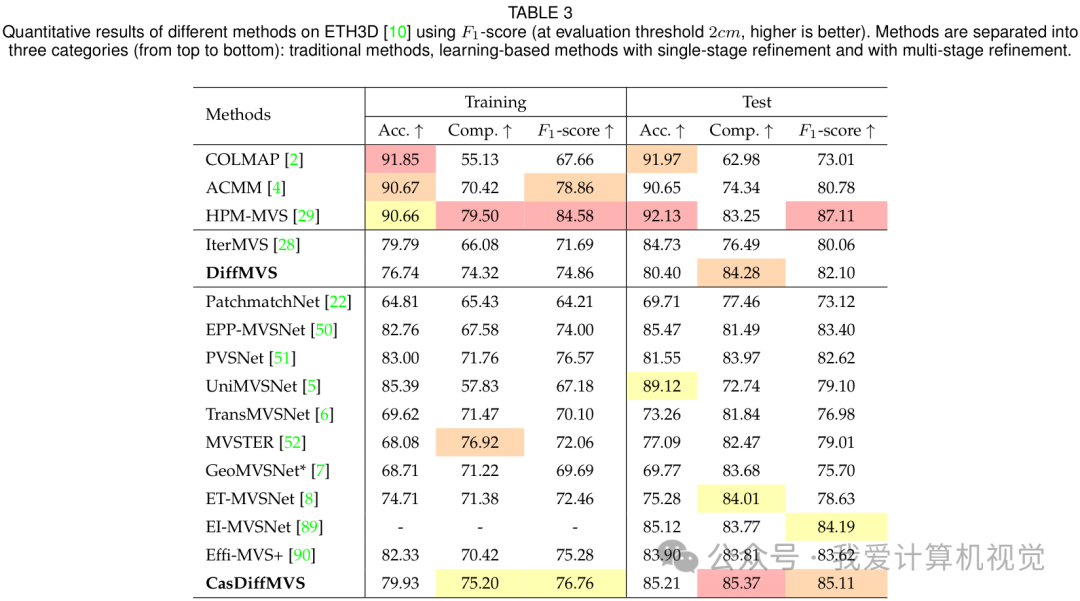
下图为 ETH3D 上的定性结果,无论是在室内 "Relief" 场景还是室外 "Terrace" 场景,CasDiffMVS 的重建结果(最右列)都更加准确和完整。

效率对比
效率是 MVS 方法在实际应用中的一个关键考量。如下图所示,DiffMVS 在运行时间(横轴)和 GPU 内存消耗(纵轴)方面表现出 最佳 的效率,远超其他 SOTA 方法。即使是追求高精度的 CasDiffMVS,其效率也与 PatchmatchNet 相当,但性能却遥遥领先。

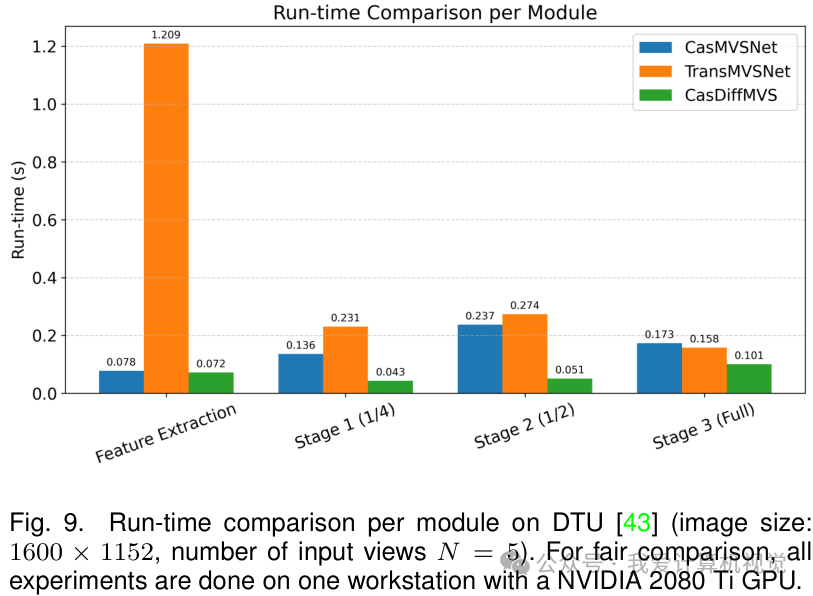
下图进一步分析了不同方法在各个模块上的耗时。可以看到,CasDiffMVS 在特征提取和深度推断阶段都比基于 Transformer 或 3D CNN 的方法(如 TransMVSNet, CasMVSNet)快得多,这得益于其轻量化的网络设计。
消融实验
作者通过一系列消融实验验证了各个设计模块的有效性。
扩散模型的有效性: 移除扩散过程后,模型性能在 DTU 和 ETH3D 上分别下降了 3.2% 和 5.6%,证明了扩散机制的核心贡献。 扩散条件的有效性: 移除代价体、深度上下文或图像上下文等任何一个条件,都会导致性能显著下降,说明了多信息融合引导的重要性。 置信度采样的有效性: 与单样本或固定范围采样相比,基于置信度的自适应采样策略能带来明显的性能提升。 网络结构的有效性: 与单个 U-Net 或堆叠 U-Nets 相比,本文提出的 U-Net+ConvGRU 结构在性能和效率之间取得了最佳平衡。

此外,实验还表明,模型对 DDIM 采样步数、噪声尺度和随机种子等超参数具有较好的鲁棒性。



总结与贡献
本文 首次 将扩散模型成功引入多视图立体(MVS)领域,并提出了一个新颖、高效、准确的深度估计框架。
主要贡献可以总结为:
提出新框架: 提出了一个基于条件扩散模型的 MVS 框架,将深度细化表述为去噪过程,有效避免了传统方法的局部最优问题。 提出两种新方法:
DiffMVS: 实现了 SOTA 级别的运行效率和低内存占用,适用于对实时性要求高的场景。 CasDiffMVS: 在多个主流 MVS 基准上取得了 SOTA 的重建精度。
总而言之,这项工作不仅在性能上取得了突破,更重要的是为 MVS 领域探索了一个全新的、富有潜力的技术方向。CV君认为,将生成模型思想与判别任务相结合的思路非常值得借鉴,未来可能会有更多工作沿着这个方向展开。
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











