
芯片项目组创始团队招募!◀点击查看!
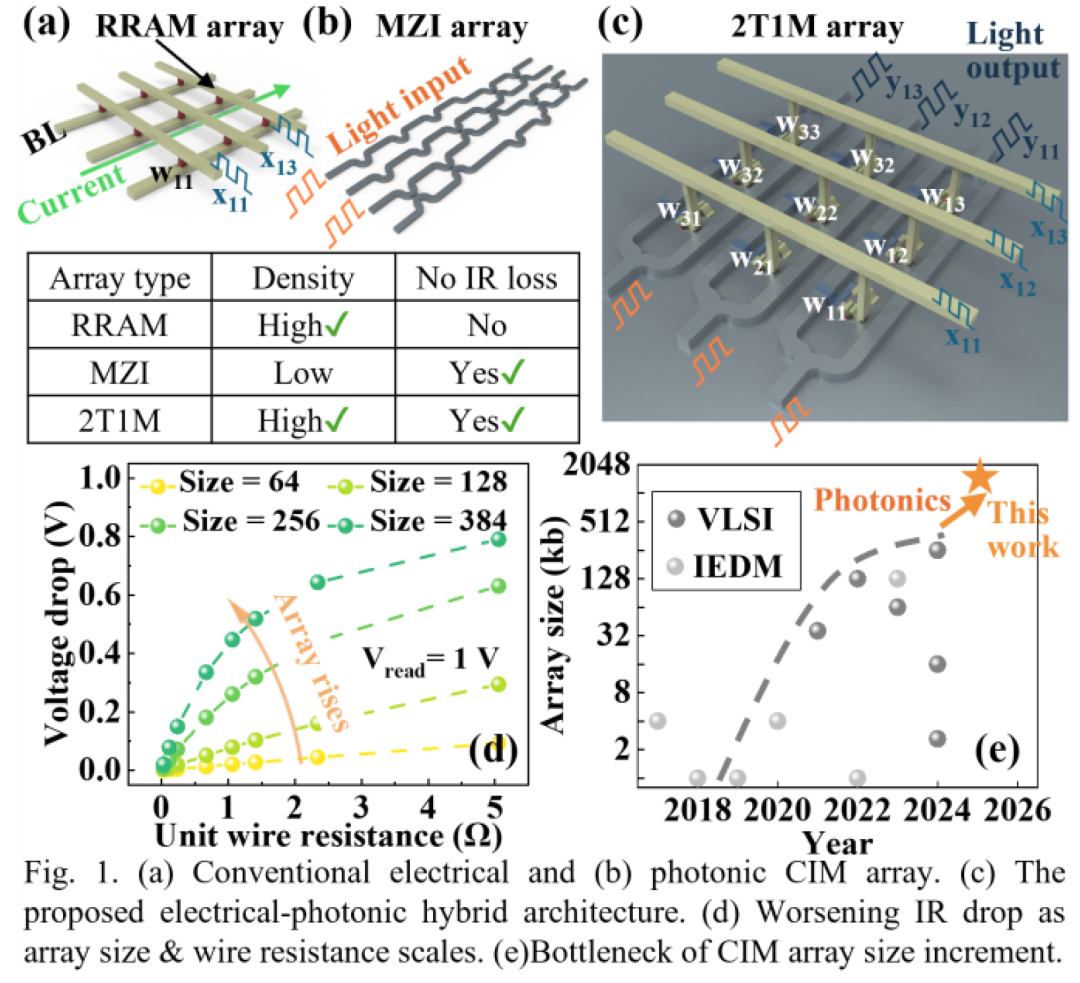
在深度学习与人工智能技术迅猛发展的今天,大规模神经网络模型如Transformer的应用日益广泛,对计算硬件的性能提出了前所未有的挑战。传统的基于忆阻器RRAM的电存算一体(CIM)架构在应对这些挑战时,面临着一个严峻的问题——随着阵列规模的扩大,导线电阻也随之增大,IR压降效应愈发显著,严重限制了CIM阵列规模的扩展(图1)。在2025 Symposium on VLSI Technology and Circuits(VLSI)半导体顶会上,来自新加坡国立大学(NUS)的Aaron Thean教授团队展示了一项光电混合存内计算的研究(图1c),共同第一作者为赵石(NUS博士生)、许泽锋(现香港科技大学(广州)助理教授)和杨洁(NUS博士生)。该研究首次提出一种新型的双晶体管单调制器(2T1M)光电混合存算阵列,通过光学位元线(bit line,BL)规避传统电位元线的IR损耗与电容负载问题:利用工作在亚阈值区域的铁电场效应晶体管(FeFET)存储器执行点积运算,经光信号相位调制实现结果求和,并采用低损耗铌酸锂(LNOI)马赫曾德调制器(MZI)实现高效电光转换,通过共享MZI对光子波导BL进行读取以最大化列布局效率。该架构通过消除电BL的IR损耗,可支持高达3750kb的阵列规模,在大规模 Transformer模型上,该架构仿真上可实现93.3%的推理精度,与GPU实现相当,显著超越传统CIM设计的48.3%。此外,通过消除大规模矩阵分解和重复外围电路的需求,能效提升超过3倍,达167 TOPS/W。
1.
架构设计与工作原理
2T1M光电混合架构是一种全新的存算一体架构设计(图2),它巧妙地结合了电子和光子技术的优势,旨在解决传统CIM架构的IR压降问题。该架构的核心在于每个存储单元由两个晶体管和一个调制器组成,通过光电转换实现了无损的列线求和。在2T1M架构中,FeFET(铁电场效应晶体管)被用于执行乘法运算,这是因为FeFET在亚阈值区域具有良好的线性特性,能够实现高效的模拟计算。与传统的RRAM相比,FeFET具有更低的截止电流,这对于降低静态功耗至关重要。在室温下,FeFET在±3V、100μs条件下表现出亚pA级截止电流以及预期10年的保持特性和超过107次循环的可重复性。

2.
光电转换与无损求和
2T1M架构的另一个关键组成部分是基于铌酸锂(LN)的调制器实现电信号到光信号的转换。铌酸锂材料的Pockels效应表明,当对铌酸锂材料施加电场时,其折射率会发生变化。这种折射率的变化会导致光信号的相位发生偏移。通过将多个2T1M单元集成在一个马赫-曾德尔干涉仪(MZI)的单臂上,各个单元产生的相位偏移可以被有效地累加,从而实现了向量矩阵乘法结果的无损求和(图6)。
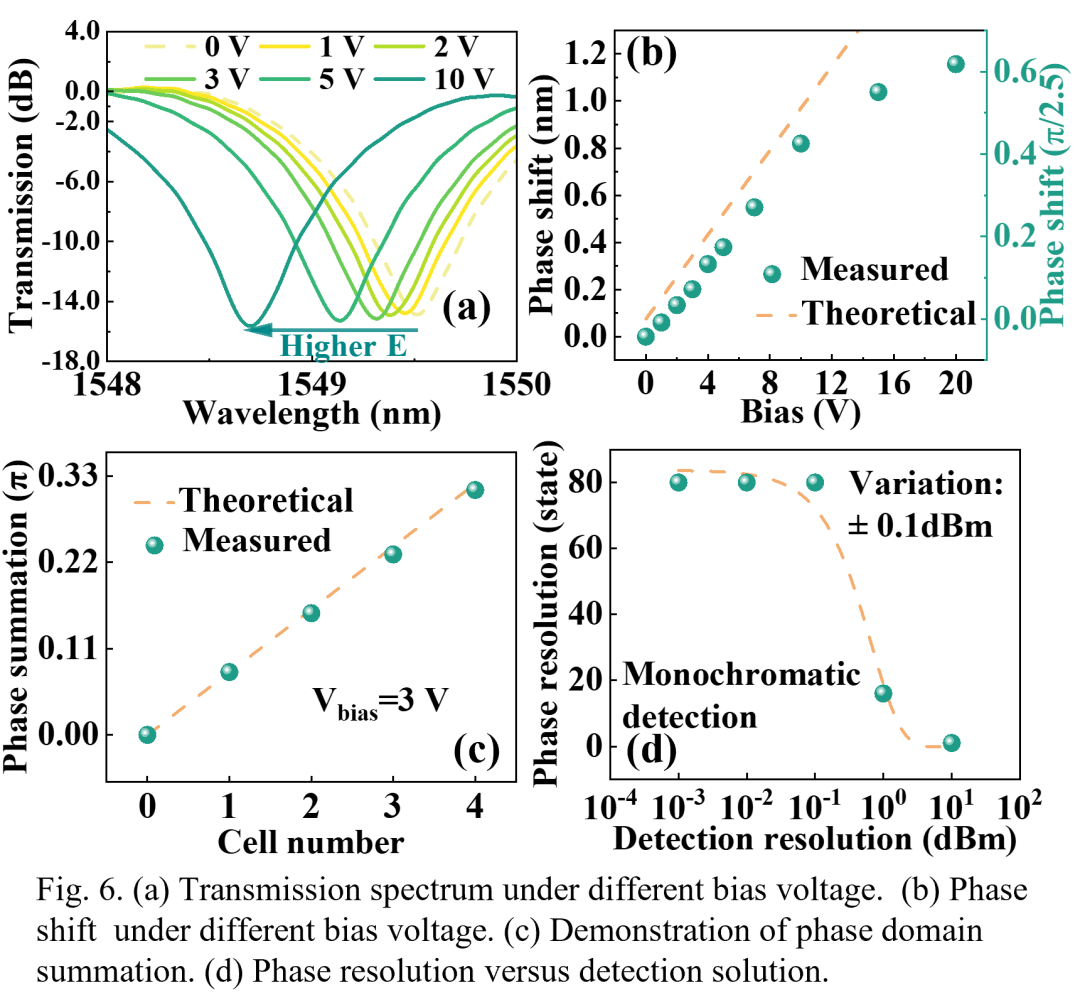
这种光电转换和相位求和的方式具有显著的优势。首先,光信号在波导中的传播损耗极低,本研究中实现的铌酸锂波导传播损耗仅为0.28dB/cm,这使得大规模阵列中的信号无损传输成为可能。其次,相位求和是一种无损的求和方式,避免了传统电信号求和中因IR压降导致的误差积累问题。
3.
Transformer应用
为了验证2T1M架构的性能,该团队进行了详细的实验验证。结果表明,该架构在多个关键指标上表现出色,显著优于传统的CIM架构(图9)。
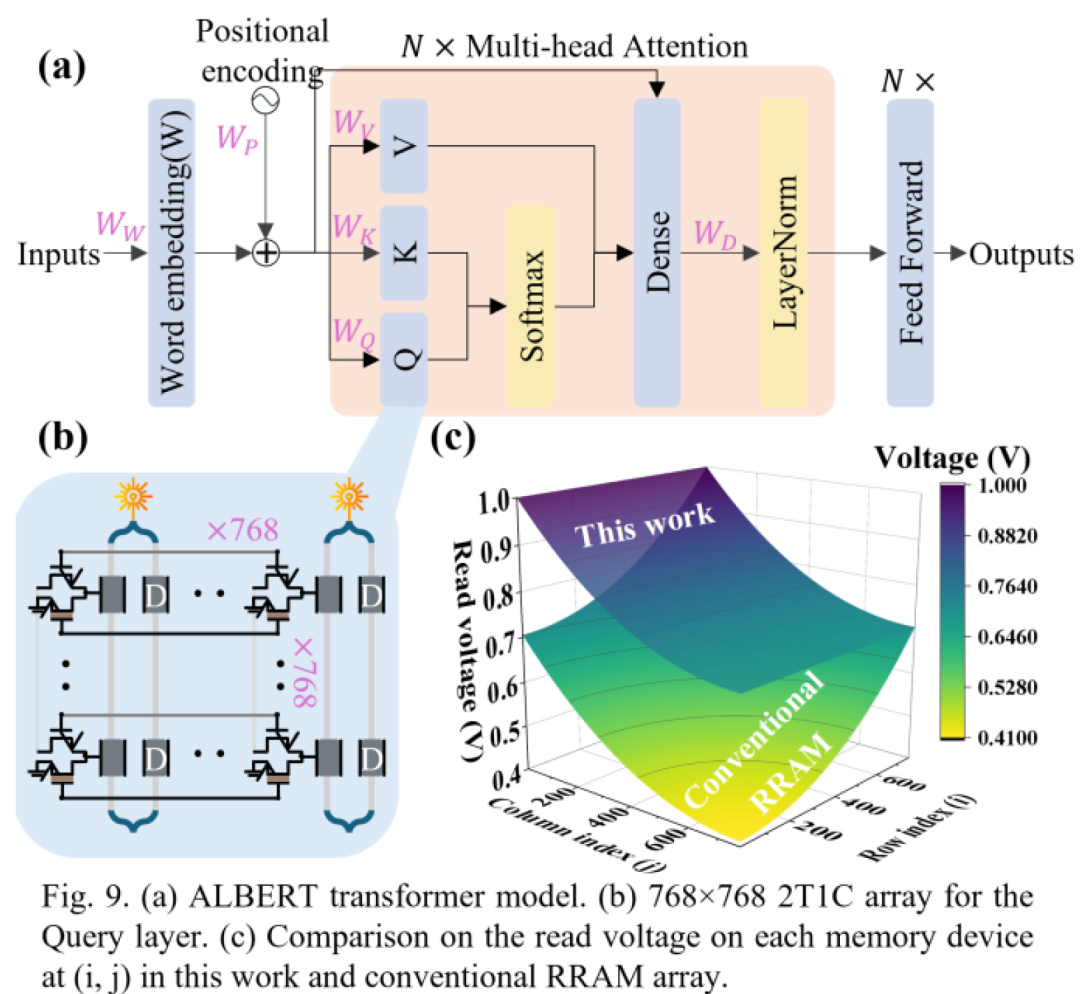
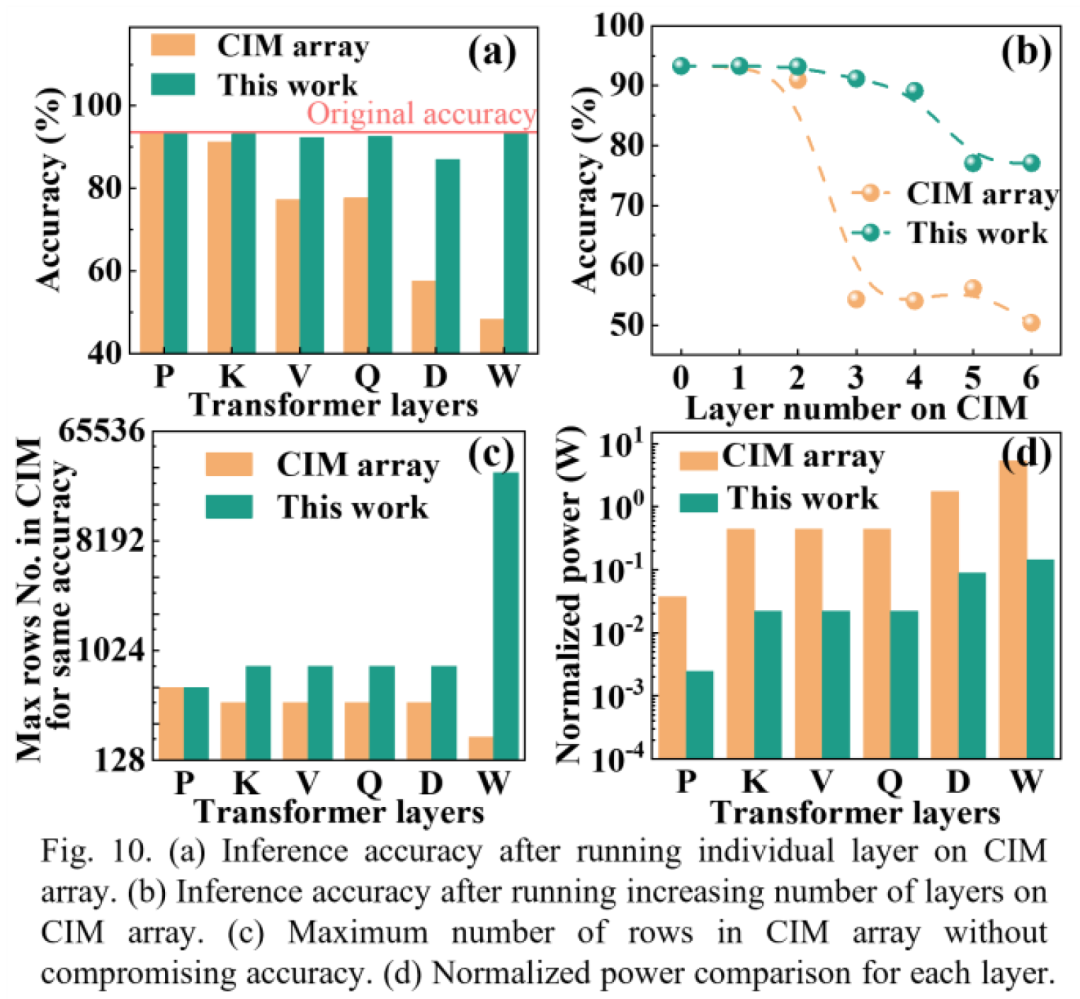
在准确性方面,当运行ALBERT模型的最大词嵌入层(30000×128)时,2T1M架构实现了93.3%的推理准确率,这一结果与完整的GPU实现相当,而传统的CIM架构在相同条件下仅能达到48.3%的准确率。这一巨大的差距充分说明了2T1M架构在克服IR压降问题后,能够更好地保持计算的准确性,尤其是在大规模阵列中(图10)。在可扩展性方面,2T1M架构表现出了显著的优势。传统CIM架构由于IR压降的限制,阵列规模很难超过256kb,而2T1M架构通过光电混合设计,成功实现了3750kb的超大阵列规模,这是传统架构的150倍以上。这种出色的可扩展性使得2T1M架构能够满足大规模神经网络模型的计算需求。 在功耗方面,2T1M架构同样表现优异。由于消除了IR压降,避免了大规模矩阵分解和重复的外围电路,该架构的功耗效率比最先进的传统CIM架构提高了37倍,达到了164TOPS/W的峰值性能。这一结果对于推动边缘计算和数据中心的能效提升具有重要意义。

作者介绍:




(本文作者:ATG)
☟☟☟
☞人工智能产业链联盟筹备组征集公告☜
☝
*免责声明:本文由作者原创。文章内容系作者个人观点,人工智能产业链联盟转载仅为了传达一种不同的观点,不代表人工智能产业链联盟对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END

半导体行业交流群











