
本文由 Intern-S1、Qwen3 等 AI 生成, 由机智流编辑部校对
不知道你有没有这样的感受,在使用各家大模型的深度研究时,让大语言模型自行查阅一个网页及其子网页的信息并总结时,感觉效果还不错;但让研究一个开放性问题(即OEDR,比如概括某个领域的研究现状)并输出研究报告时,总觉得差点意思。
最近,阿里通义实验室的研究团队,包括Zijian Li、Xin Guan等学者,在发布的论文《WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research》中,提出了一种创新框架——WebWeaver。这个框架模拟人类研究过程,通过双智能体系统(规划器和写作器)来解决现有方法的双重局限:一是静态研究管道,将规划与证据收集分离,导致研究路径僵化;二是单次生成范式,容易陷入“中间丢失”(loss in the middle)和幻觉问题。

图1:不同智能体在三大基准上的性能对比。WebWeaver在DeepResearch Bench、DeepConsult和DeepResearchGym中均取得SOTA,展示了其在开放式深度研究中的优越性。
WebWeaver强调动态循环和分层合成,让AI智能体像人类专家一样,边探索边调整大纲,最终输出高质量、可靠的报告。该框架已在三大主要OEDR基准测试中取得state-of-the-art(SOTA)性能,超越了包括OpenAI和Gemini在内的专有系统。这不仅为学术界提供了开源解决方案,还通过构建高质SFT数据集WebWeaver-3k,帮助小型模型实现专家级表现。感兴趣的读者可以访问项目博客或GitHub仓库获取更多细节。
项目博客:https://tongyi-agent.github.io/blog
GitHub:https://github.com/Alibaba-NLP/DeepResearch
现有方法的痛点:为什么AI在深度研究中“卡壳”?
传统OEDR方法大致分为两类:专有系统和开源方案。专有系统如OpenAI的DeepResearch、Google的Gemini Deep Research,虽然强大,但API费用高昂、配额限制严格,阻碍了广泛应用和学术探索。开源方案则主要采用两种范式。第一种是“先搜索后生成”,智能体先收集所有信息,然后直接生成报告。这种方法缺乏指导性大纲,导致输出低质且不连贯。第二种是先生成静态大纲,再针对每个部分搜索。这种策略看似更结构化,但大纲基于LLM的内部知识固定成型,无法适应搜索中的新发现。更糟糕的是,将所有检索材料塞入单一上下文进行生成,会引发注意力分散、幻觉增多等问题。
研究团队通过分析这些范式(如下图2所示),指出核心问题是脱离了人类研究的有机过程。人类专家不会预先固定整个计划,而是让大纲成为“活文档”,随着发现不断演化。写作时,也不会一次性“阅读”所有笔记,而是针对每个章节参考特定材料。WebWeaver正是基于这一人类中心哲学设计的,它通过动态研究循环和记忆导向的分层合成,实现了从探索到输出的无缝衔接,避免了长上下文的陷阱。

图2:三种研究范式的对比。图中展示了传统“先搜索后生成”(a)和“静态大纲引导搜索”(b)范式的局限,以及WebWeaver的动态循环与分层写作(c),后者通过迭代优化大纲和针对性检索,提升了报告的质量和可靠性。
WebWeaver框架详解:规划器与写作器的协同作战
WebWeaver的核心是一个双智能体框架,由规划器和写作器组成,整体流程如图3所示。规划器负责探索阶段,通过动态研究循环交替进行证据收集和大纲优化。不同于静态方法,规划器在每个步骤中选择搜索、优化大纲或终止动作。当证据不足时,它执行搜索:查询搜索引擎,获取标题、片段和URL,然后通过LLM过滤相关URL,提取摘要反馈到上下文中,并将详细证据存入记忆库。这一过程确保了探索的适应性,让大纲随着新发现不断精炼,最终输出一个全面的、带引用的大纲,每个部分链接到记忆库中的证据ID。
规划器输出示例,上下滑动,查看更多














向下滑动查看所有内容
写作器则处理合成阶段,避免单次生成的弊端,转而采用分层检索和写作策略。它按大纲逐节构建报告:识别子任务,检索相关证据,进行内部思考(分析内容、合成洞见、规划叙事),然后写作输出。完成后,移除已用证据,防止上下文溢出和干扰。这种“分而治之”的方法模拟人类专注写作,缓解了“中间丢失”和“上下文溢出”问题。框架使用ReAct作为智能体范式,定义了明确的动作空间(如搜索、检索、写作),并引入记忆库管理长上下文输入(超过100k令牌)和输出(超过20k令牌)。
写作器输出示例,上下滑动,查看更多









向下滑动查看所有内容
这一设计哲学源于对人类认知的深刻洞察:研究不是线性管道,而是迭代循环;写作不是蛮力处理,而是专注子任务。WebWeaver通过这种方式,不仅提升了报告的全面性和可靠性,还为复杂信息景观导航提供了新范式。

图3:WebWeaver整体工作流程。左侧显示规划器的迭代证据收集和大纲优化,右侧展示写作器的分层检索与写作,确保每个部分仅使用相关证据,避免长上下文问题。
实验验证:基准领先与深入分析
为了验证WebWeaver的有效性,研究团队在三大基准上进行了广泛实验:DeepResearch Bench(100个博士级任务,覆盖22领域)、DeepConsult(商业咨询领域提示集)和DeepResearchGym(真实信息寻求查询)。使用不同LLM如Qwen3系列、Claude-sonnet等作为后端,WebWeaver一致超越开源(如WebShaper)和专有系统(如Gemini-2.5-pro-deepresearch)。例如,在DeepResearch Bench上,WebWeaver(Claude-sonnet-4-20250514)取得50.58的整体RACE分数,93.37%的引用准确率;在DeepConsult上,胜率达66.86%;在DeepResearchGym上,平均分数96.77。这些结果源于动态循环带来的深度和广度提升,以及分层写作的可靠性保障。
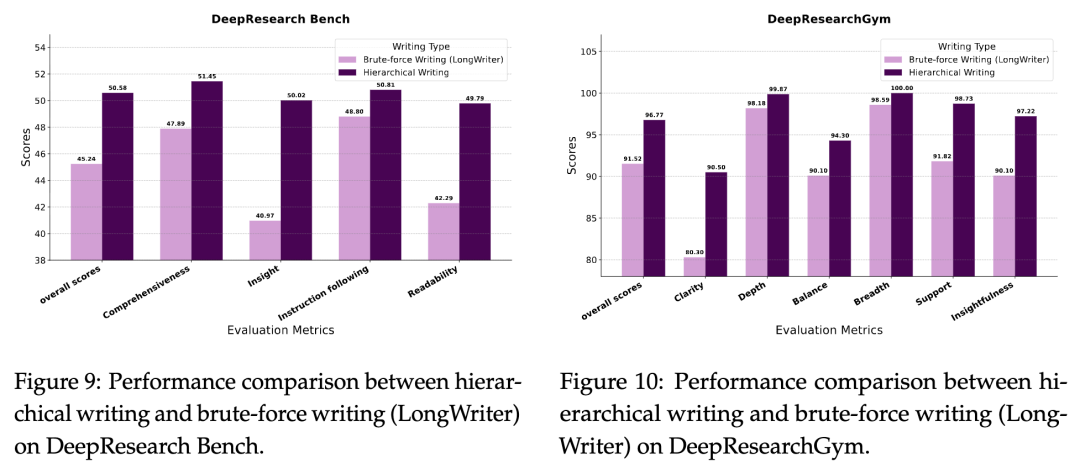
进一步的分析揭示了框架组件的贡献。规划统计显示,平均16次搜索和2次以上大纲优化,生成4k+令牌的大纲,处理67k+证据令牌。这证明了迭代优化的必要性:随着优化轮次增加,报告分数稳步上升(如图5和6所示),特别是在全面性和洞见维度。LLM判断也确认了大纲质量的提升(图7和8)。对比分层写作与蛮力写作(如LongWriter),前者在洞见和可读性上大幅领先(图9和10),验证了注意力管理的关键作用。


此外,团队构建了WebWeaver-3k SFT数据集,通过强大教师模型生成3.3k规划和3.1k写作轨迹,用于微调小型模型(如Qwen3-30b)。结果显示,微调后模型在基准上显著提升,例如引用准确率从25%跃升至85.90%(图12),证明了复杂技能(如思考、搜索、写作)的可蒸馏性。这为实际部署小型模型提供了宝贵途径。

相关工作与启示:从深度研究到长写作的演进
WebWeaver与现有深度研究智能体密切相关,但超越了它们。专有系统如Claude Research虽强大,但不透明;开源如OpenDeepResearch、GPT Researcher采用静态大纲和单步生成,导致不连贯和幻觉。WebWeaver强调大纲优化和分层写作,确保流畅性和准确性。在长写作领域,它区别于LongWriter的“计划后写”策略,后者依赖静态计划和蛮力输入,而WebWeaver实现动态优化和针对性检索。
这一工作不仅解决了OEDR的具体问题,还为AI智能体设计提供了新蓝图:通过系统级信息管理和精确动作,将长上下文难题转化为结构化任务。这启示未来智能体应注重人类式迭代,而非被动处理。
结语:WebWeaver开启AI知识工作的未来
阿里通义实验室的WebWeaver框架标志着AI在开放式深度研究领域的重大进步。它通过模拟人类过程,实现了从海量网页中提炼洞见的高效路径,并在基准中证明了其优越性。更重要的是,它展示了如何通过SFT数据集将专家技能注入小型模型,推动AI的民主化。未来,这一范式可能扩展到更多知识密集任务,助力AI从工具向智能伙伴转型。研究者们可通过上述链接深入探索,推动这一领域的进一步创新。
-- 完 --
机智流推荐阅读:
1. 万字长文解答为何LLM同问不同答?OpenAI前CTO团队最新研究让大模型结果可复现
2. VLA-Adapter:北邮等团队以0.5B参数实现机器人智能新高度,还无需预训练
3. 理解和生成让任务真的能相互受益吗,还是仅仅共存?北大&百度UAE框架,统一视觉理解与生成,实现多模态模型新突破
4. 聊聊大模型推理系统之Q-Infer技术突破:GPU-CPU协同推理提速3倍背后的三大创新
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










