点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 论文信息
标题:MapAnything: Universal Feed-Forward Metric 3D Reconstruction
作者:Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, Peter Kontschieder
机构:Meta Reality Labs、Carnegie Mellon University
原文链接:https://www.arxiv.org/abs/2509.13414
代码链接:https://github.com/facebookresearch/map-anything
官方主页:https://map-anything.github.io/
1. 导读
我们介绍了MapAnything,这是一种基于变换器的统一前馈模型,它吸收一个或多个图像,并包含可选的几何输入,如相机特性、姿态、深度或部分重建,然后直接回归度量三维场景几何和相机。MapAnything利用多视点场景几何的因子表示,即深度图,局部光线图,相机姿势的集合,和一个度量比例因子,有效地将局部重建升级为全球一致的度量框架。通过对不同数据集的监督和培训进行标准化,加上灵活的输入增强功能,MapAnything能够在单一前馈通道中处理广泛的3D视觉任务,包括未校准的运动结构、校准的多视图立体、单目深度估计、相机定位、深度完成等。我们提供广泛的实验分析和模型改进,证明MapAnything优于或匹配专业前馈模型,同时提供更高效的联合训练行为,从而为通用的3D重建主干铺平道路。
2. 效果展示
MapAnything是一种灵活、统一的向前馈送式3D重建模型,它利用一组N个输入图像中的相机信息来预测度量级别的3D重建结果,这些输入图像可以包含可选的相机姿态、内部参数或深度图。MapAnything支持超过12种不同的3D重建任务,包括相机定位、结构自运动(SfM)、多视角立体成像以及度量深度填充,其表现优于或至少与专业方法的质量相当。

. MapAnything与仅使用野外图像作为输入的VGGT的定性比较。为了公平比较,我们对两种方法应用了相同的基于法线的边缘掩模后处理和我们的天空掩模。MapAnything更有效地处理了大的视差变化、季节变化、无纹理表面、水体和大场景。

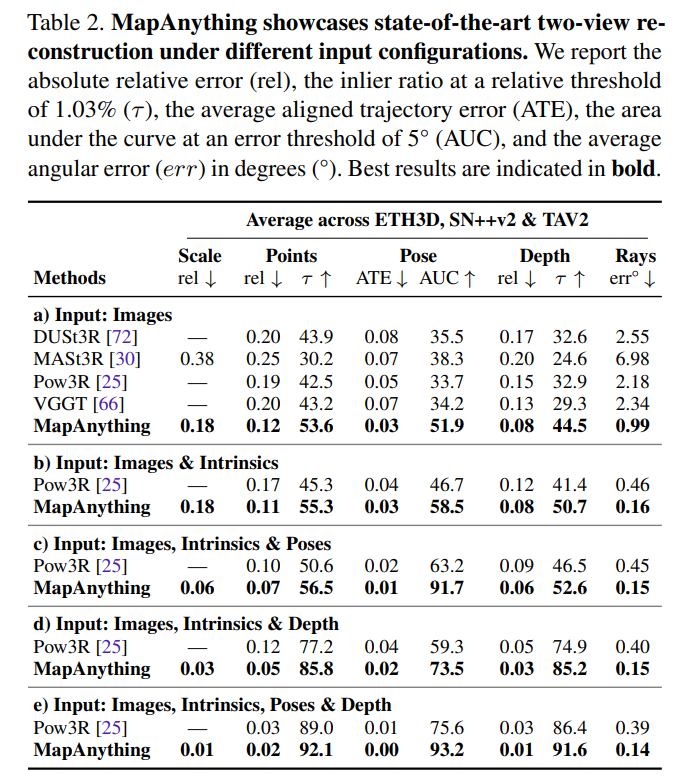
MapAnything展示了最先进的密集多视图重建功能,可用于在不同输入配置下从2到100个输入视图的数量。我们报告了ETH3D,ScanNet++v2和TAv2上的绝对相对误差(rel),相对阈值为1.03%(r)的内比,平均对齐轨迹误差ATE RMSE),误差阈值为5°(AUC@5)的曲线下面积,以及平均角度误差(err)。当推断耗尽GPU内存时,我们不会报告基准的性能。我们在补充材料中为MapAnything的详尽输入配置提供了结果。

3. 引言
基于图像的三维重建问题传统上一直采用运动恢复结构(Structure-from-Motion,SfM)、光度立体法(Photometric Stereo)、从明暗恢复形状(Shape-from-Shading)等方法来解决。为了使问题易于处理,经典方法将其分解为不同的任务,如特征检测与匹配、两视图位姿估计、相机标定与 resectioning(相机定位,将相机在空间中的位置和姿态解算出来)、旋转与平移平均、光束法平差(Bundle Adjustment,BA)、多视图立体视觉(Multi-View Stereo,MVS)和/或单目表面估计。近期的研究表明,使用前馈架构以统一的方式解决这些问题具有巨大的潜力。
虽然先前的前馈研究要么孤立地处理不同任务,要么未充分利用所有可用的输入模态,但本文提出了一种用于多种三维重建任务的统一端到端模型。我们的方法MapAnything可用于解决最一般的未标定SfM问题,以及各种子问题的组合,如标定SfM或多视图立体视觉、单目深度估计、相机定位、度量深度补全等。为了实现这种统一模型的训练,我们:(1)引入了一种灵活的输入方案,在可用时支持各种几何模态;(2)提出了一种合适的输出空间,支持所有这些不同的任务;(3)讨论了灵活的数据集聚合与标准化方法。推荐课程:为什么说colmap仍然是三维重建的核心?
MapAnything应对这些挑战的关键在于采用多视图场景几何的因子分解表示。我们没有将场景直接表示为点图的集合,而是将场景表示为深度图、局部光线图、相机位姿以及将局部重建升级为全局一致度量框架的度量尺度因子的集合。我们使用这种因子分解表示来表示MapAnything的输出和(可选)输入,使其能够在可用时利用辅助几何输入。例如,机器人应用可能已知相机内参(光线)和/或外参(位姿)。最后,我们因子分解表示的一个重要优势在于,它允许MapAnything从具有部分标注的多样化数据集中进行有效训练,例如,仅标注了非度量“按比例缩放”几何的数据集。
4. 主要贡献
提出了一种用于多视图度量三维重建的统一前馈模型,支持超过12种不同的问题配置。与一组简单的定制模型相比,端到端Transformer的训练效率更高,并且不仅利用图像输入,还利用相机内参、外参、深度和/或度量尺度因子等可选几何信息(在可用时)。
提出了一种因子分解场景表示,可灵活实现解耦输入和有效预测度量三维重建。我们的模型直接计算多视图像素级场景几何和相机参数,无冗余或高昂的后处理成本。
与其他前馈模型相比,取得了最优性能,达到或超过了针对特定孤立任务定制的专家模型。
开源发布了(a)用于数据处理、推理、基准测试、训练和消融实验的代码,以及(b)在宽松的Apache 2.0许可证下预训练的MapAnything模型,从而提供了一个可扩展且模块化的框架和模型,以促进未来构建三维/四维基础模型的研究。
5. 方法
给定N个视觉和可选几何输入,模型首先将图像和几何输入的因子分解表示编码到一个共同的潜在空间中,其中,补丁特征(针对图像、光线和深度)和广播的全局特征(针对所有位姿输入的平移、旋转、位姿尺度以及每个帧的局部深度尺度)相加。然后,将一个固定的参考视图嵌入添加到第一个视图的特征中,并将一个可学习的单一尺度标记附加到N个视图补丁标记集合中。接着,将这些标记输入到交替注意力Transformer中。我们使用单个密集预测Transformer(DPT)将N个视图补丁标记解码为所有视图局部的N个密集输出。一个基于平均池化的位姿头也使用N个视图补丁标记来预测框架中的N个位姿。最后,虽然这些预测存在于按比例缩放的空间中,但模型将尺度标记通过多层感知器(MLP)来预测度量尺度因子,该因子与其他预测相结合,提供密集的度量三维重建。

辅助几何输入可提高MapAnything的前馈性能。(上)虽然使用100张输入图像的MapAnything和其他基线方法都显示出三维结构的重复,但当提供相机标定和位姿时,三维重建显著改善,展示了对齐的几何结构。(中)仅使用图像作为输入的MapAnything在ETH3D(一个零样本数据集)上展示出不精确的度量尺度估计。然而,当将标定和度量位姿作为额外输入提供时,估计的度量尺度显著改善,并大致与真实值匹配。(下左)我们展示了MapAnything能够利用稀疏度量点云作为输入来执行密集度量深度补全。(下右)尽管未针对以对象为中心的数据进行训练,但我们展示了场景几何和相机如何根据提供的输入而变化。

6. 实验结果

7. 总结 & 未来工作
MapAnything是首个通用的基于Transformer的主干网络,它直接从灵活的输入(包括图像、相机内参、位姿、深度图或部分重建)中一次性回归度量三维几何和相机位姿。通过使用多视图几何的因子分解表示(深度图、光线图、位姿和全局尺度因子),MapAnything将局部估计统一到全局度量框架中。通过跨不同数据集和增强的标准化监督,MapAnything无需针对特定任务进行调优,即可处理多种任务,如未标定运动恢复结构、标定多视图立体视觉、单目深度估计、相机定位、深度补全等。大量实验表明,它超越或匹配了专家模型,同时实现了高效的联合训练。未来向动态场景、不确定性量化和场景理解方向的扩展,有望进一步提升MapAnything的能力和鲁棒性,为构建真正的通用三维重建主干网络铺平道路。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001