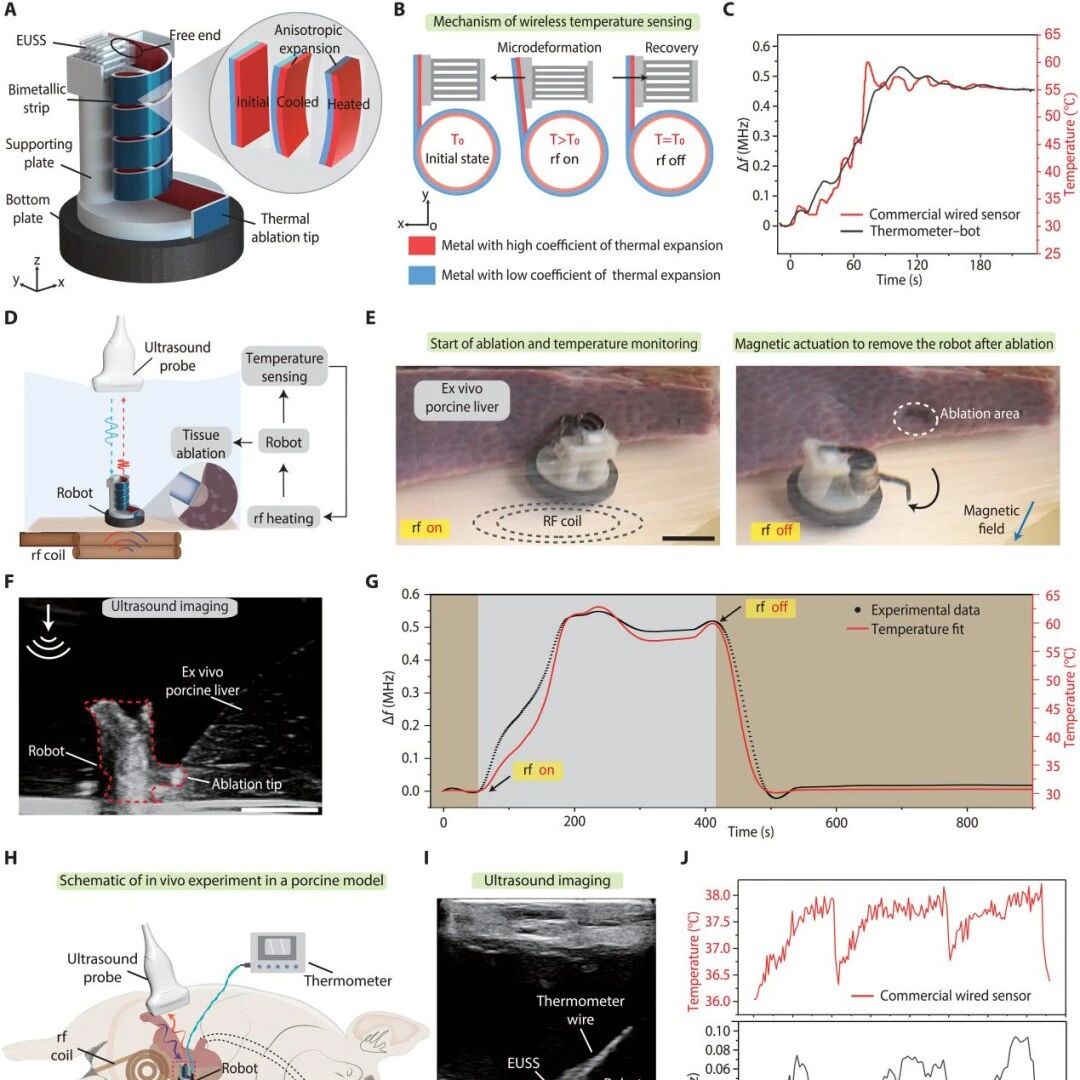
点击下方卡片,关注“具身智能之心”公众号
作者丨YumingJiang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
在大语言模型、多模态模型飞速发展的今天,机器人操作领域却始终受困于一个关键难题——大规模高质量操作数据的稀缺。传统机器人数据采集依赖人类远程操控实体设备记录轨迹,不仅耗力耗时,成本更是居高不下,直接制约了视觉-语言-动作(VLA)模型的进步。
为打破这一僵局,来自阿里巴巴达摩院的团队提出了全新 VLA 模型 RynnVLA-001。该模型另辟蹊径,将目光投向人类演示数据:通过 1200 万条以ego为中心的人类操作视频,结合两阶段预训练策略,让机器人 “学习” 人类的操作逻辑与动作轨迹。从预测未来操作帧的视觉动态,到关联人类关键点轨迹建立动作映射,再到引入 ActionVAE 优化机器人动作连贯性,RynnVLA-001 成功架起了 “人类演示” 到 “机器人操作” 的桥梁。
实验显示,在 LeRobot SO100 机械臂上,RynnVLA-001 在绿色方块拾取、草莓抓取、钢笔入架等任务中,平均成功率达 90.6%,显著超越 GR00T N1.5、Pi0 等主流模型;即便在含干扰物的复杂场景中,仍保持 91.7% 的高成功率,展现出极强的指令跟随与抗干扰能力。
这一突破不仅为 VLA 模型提供了更高效的预训练范式,更让机器人操作向 “低成本、高泛化” 迈进了关键一步。想了解模型如何通过人类演示实现技能迁移?两阶段预训练与 ActionVAE 模块又有哪些技术细节?下文将为你深入解析 RynnVLA-001 的创新之处。
论文题目:RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
论文链接:https://arxiv.org/pdf/2509.15212
项目链接:https://github.com/alibaba-damo-academy/RynnVLA-001
作者单位:DAMO Academy, Alibaba Group, Hupan Lab

研究背景与问题
在大语言模型(LLM)、多模态模型(VLM)和生成模型等领域,得益于大规模数据集的支撑,技术已取得快速发展。例如,大语言模型可从网络资源中获取丰富的训练数据。然而,视觉 - 语言 - 动作(VLA)模型的发展却受限于大规模机器人操作数据的稀缺。
机器人操作数据的收集通常依赖人类对实体机器人进行远程操控以记录操作轨迹,这一过程不仅耗费大量人力,成本也极高。为解决数据稀缺问题,现有研究主要有两类思路:一是构建大规模机器人操作数据集,但此类数据集规模远小于 LLM、VLM 等模型所用数据集;二是利用预训练生成模型或 VLM 的海量先验知识,不过仍未能充分弥合视觉预测与机器人动作控制之间的差距,无法高效实现从人类演示到机器人操作的技能迁移。
主要贡献
提出两阶段预训练框架:创新性地设计了 “以ego为中心的视频生成预训练” 和 “以人类为中心的轨迹感知建模” 两阶段预训练方法,有效将人类演示中的操作技能迁移到机器人操作任务中,填补了视觉帧预测与动作预测之间的鸿沟。
引入 ActionVAE 模块:提出变分自编码器(ActionVAE),将动作序列压缩为紧凑的 latent 嵌入,降低 VLA 模型输出空间的复杂度,同时保证预测动作的平滑性和时间连贯性,避免单步动作预测的重复性问题。
构建大规模数据集与数据筛选 pipeline:从网络资源中筛选出 1200 万条以ego为中心的人类操作视频,并结合机器人特定数据集,为模型训练提供高质量数据支撑;同时通过多阶段筛选(如关键点检测、ego中心视角过滤)确保数据与机器人操作任务的相关性。
性能超越现有基线模型:在相同下游机器人数据集上微调后,RynnVLA-001 在多个操作任务(如拾取放置草莓、绿色方块、钢笔入架)中,成功率显著优于 GR00T N1.5 和 Pi0 等当前主流模型,验证了预训练策略的有效性。
方法介绍
RynnVLA-001 的训练流程分为三个核心阶段,并结合 ActionVAE 模块优化动作表示,整体架构如图 2 所示:
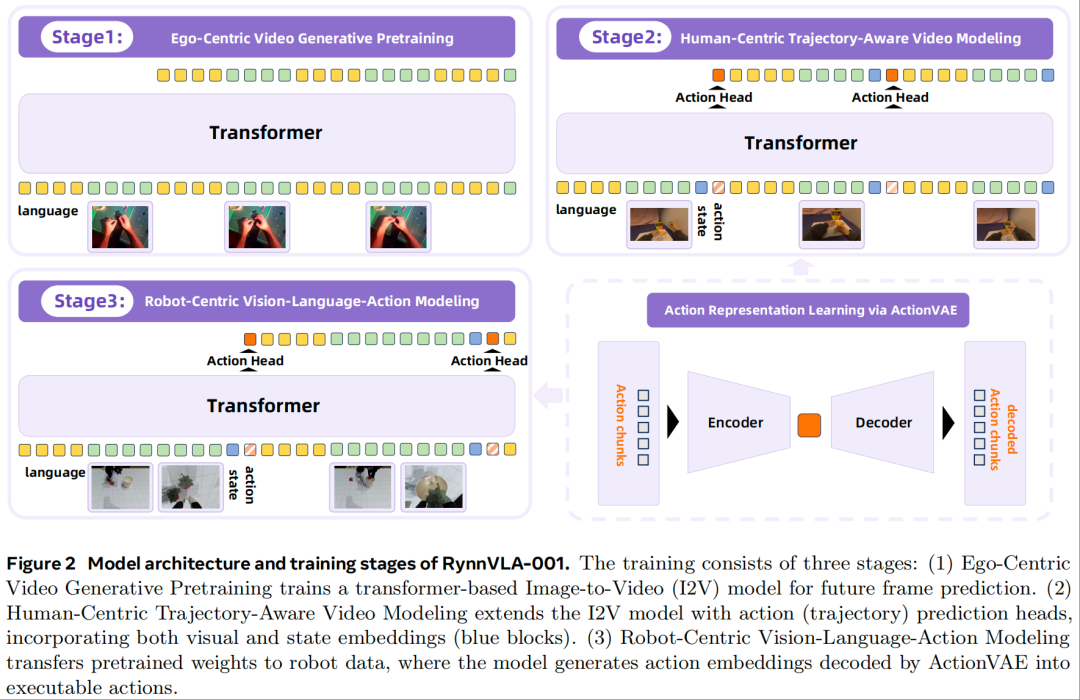
阶段 1:以ego为中心的视频生成预训练
目标:训练图像到视频(I2V)模型,使其能根据初始图像和语言指令预测后续视频帧,学习人类操作的视觉动态规律。 数据与架构:使用 1200 万条以ego为中心的人类操作视频(聚焦第一视角手部动作,类比机器人抓手运动),基于自回归 Transformer 扩展 Chameleon 文本 - 图像模型以适配 I2V 任务。 输入序列设计:将语言token与视觉token交错排列(如 [language tokens, visual tokens(t), language tokens, visual tokens(t+1), ...]),模拟 VLA 模型的推理过程,通过交叉熵损失监督离散视觉token和语言token的预测。
阶段 2:以人类为中心的轨迹感知建模
目标:在阶段 1 基础上,让模型同时预测未来帧和人类关键点轨迹,建立视觉预测与动作生成的关联。 数据与关键设计:采用 EgoDex 数据集(含 Apple Vision Pro 捕获的上半身关节轨迹),仅使用手腕关键点(近似机器人末端执行器位置),并通过预训练的 ActionVAE 将轨迹压缩为紧凑嵌入(而非预测原始坐标)。 输入与损失:引入 “状态嵌入”(手腕关键点当前位置),输入序列变为 [language, visual tokens(t), state embedding(t) , <ACTION_PLACEHOLDER>, ...];新增轻量级动作头(单一线性层),通过 L1 损失监督动作嵌入预测,视觉帧预测仍沿用阶段 1 的交叉熵损失。
阶段 3:以机器人为中心的视觉 - 语言 - 动作建模
目标:将前两阶段预训练的模型适配到机器人任务,实现从视觉观察和语言指令到机器人动作的映射。 架构调整: 替换动作头:丢弃阶段 2 的人类轨迹动作头,重新初始化机器人专属轻量级动作头,适配机器人运动学空间。 多视角输入:视觉token改为双摄像头视图(正面 + 手腕视角),输入序列包含 “语言指令、机器人视觉观察、当前机器人状态、动作占位符” 四部分。 训练目标:
机器人动作预测:通过 L1 损失监督动作头预测机器人动作块的嵌入(与机器人专属 ActionVAE 的真实嵌入对比)。 未来视觉预测:保留帧预测任务作为辅助正则项,通过交叉熵损失监督,维持模型对环境动态的理解。
ActionVAE:动作表示优化模块
核心功能:将 “动作块”(短动作序列)压缩为紧凑 latent 嵌入(编码器),并能从嵌入中重构原始动作序列(解码器),解决单步动作预测的效率低、重复性问题。 领域适配:针对人类轨迹和机器人动作分别训练两个 ActionVAE(因二者运动学空间不同),且模型与机器人本体绑定,训练后可直接用于同类型机器人的动作嵌入提取,无需重新训练。 推理流程:模型输出动作嵌入后,由 ActionVAE 解码器生成可执行的机器人动作序列,实现闭环控制(每步输入当前观察和指令,输出动作块并执行,直至任务完成)。
实验结果
实验设置
数据集:使用 LeRobot SO100 机械臂采集的真实世界操作数据,包含 3 类任务(拾取放置绿色方块 248 条、草莓 249 条、钢笔入架 301 条),场景涵盖 “单目标、多目标、含干扰物” 三种设置。 基线模型:GR00T N1.5(开源双系统 VLA 模型)、Pi0(结合 PaliGemma 和条件流匹配的连续控制模型),均使用相同数据微调。 评价指标:任务成功率(单任务 / 平均)、SR@1(单次尝试成功率),失败条件包括超时、连续 5 次抓取失败、操作干扰物。
核心结果
与主流模型的性能对比(表 1、表 2)

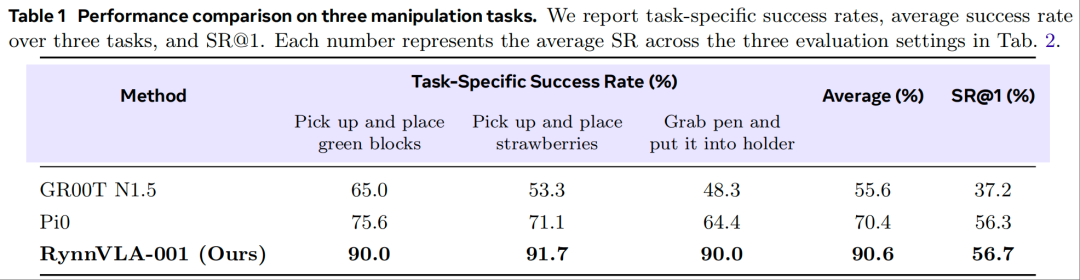
表 1 详细对比了各模型的任务专属成功率与平均成功率。本文提出的 RynnVLA-001 模型整体性能显著更优,在三项任务中均超越 GR00T N1.5 和 Pi0。在 SR@1 指标上,RynnVLA-001 与 Pi0 性能相当。所有三个模型的 SR@1 值均相对较低,这表明在提升物体定位精度以实现可靠的单次尝试成功方面,仍有较大改进空间。

表 2 报告了各模型在三种不同评估场景下的成功率。场景中物体数量越多,任务难度越大。对于 GR00T N1.5,其多目标操作和含干扰物指令跟随场景的成功率均低于单目标操作;对于 Pi0,当桌面上出现干扰物体时,成功率显著下降,表明其指令跟随能力有限。相比之下,本文提出的 RynnVLA-001 模型性能始终保持稳定。
预训练有效性验证(表 3、表 4)
在 RynnVLA-001 中,提出了两个预训练阶段:(1)以ego为中心的视频生成预训练;(2)以人类为中心的轨迹感知视频建模。为验证所提两阶段预训练流程的有效性,我们开展了全面的消融实验,结果如表 3 和表 4 所示。

结果清晰表明以视频为中心的预训练至关重要:RynnVLA-001-Scratch 模型无法将语言指令与有意义的动作关联,导致成功率极低;RynnVLA-001-Chameleon 模型受益于预训练的 T2I checkpoint,在简单抓取任务上取得了一定效果,但定位能力有限,成功率最高仅为 50.0%;与之相反,RynnVLA-001-Video 模型性能显著提升,这表明从以ego为中心的视频中学习到的先验知识可有效适配 VLA 任务。
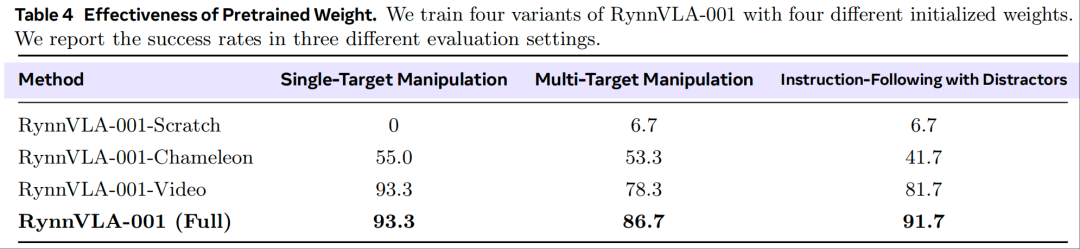
在此基础上,基于经过视频预训练的模型,进一步评估第二阶段(以人类为中心的轨迹感知视频建模)的作用。通过加入这一预训练阶段(模型学习预测人类轨迹),本文提出的完整模型 RynnVLA-001 在所有模型变体中取得了最佳性能。这一最终性能提升表明,通过预训练使模型具备预测人类轨迹的能力,能有效弥合视觉预测与动作生成之间的鸿沟,带来显著收益。
模型组件消融实验(表 5,基于 Calvin 基准)
为系统评估所开发关键组件的影响,在 Calvin 基准数据集上开展了一系列消融实验。为提升实验效率,完整模型及各消融变体均从 RynnVLA-001-Video 的预训练权重初始化。
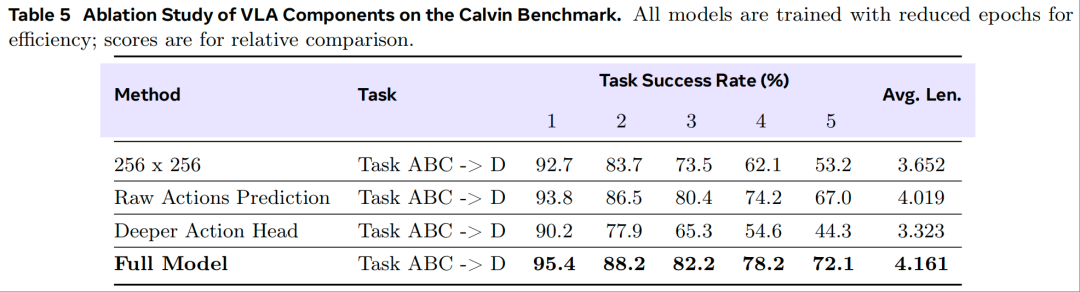
图像分辨率:384×384 分辨率性能显著优于 256×256(因 VQGAN 预训练于 512×512 图像,低分辨率导致视觉token精度下降),且 384×384 兼顾精度与计算效率。
动作表示:预测 ActionVAE 嵌入的性能优于直接预测原始动作(因嵌入压缩降低复杂度,且 latent 空间提升动作连贯性)。
动作头复杂度:单一线性层动作头性能优于 5 层 MLP(因 Transformer 输出已足够适配动作解码,深层 MLP 引入噪声或过拟合)。
视频预训练模型的可视化
本文提出的 RynnVLA-001 模型第一阶段为以ego为中心的图像-视频(I2V)模型预训练。选择 I2V 范式,以与VLA 模型的典型输入(初始图像观察与文本指令)保持一致。

如图 4 所示,预训练后的模型能根据给定图像和文本提示,生成动作合理、内容连贯的视频帧。尽管模型生成的帧间视觉变化较为细微,但其已足以使其作为后续 VLA 训练的预训练骨干网络。
前置/手腕摄像头的功能分析
前置摄像头负责物体粗定位与3D 投影场景信息获取,手腕摄像头负责精细局部调整。
前置摄像头粗定位功能验证
通过禁用前置摄像头的对比实验发现:

正常设置下(图 5(a)),机器人可成功完成草莓拾取任务; 前置摄像头被遮挡时(图 5(b)),仅当目标在手腕摄像头初始视野内,模型才能完成任务(图 5(c)),若目标在视野外(如左侧草莓),机器人无法发起动作; 定量结果:右侧目标成功率从 100%(5 次 4 中)降至 80%(5 次 4 中),左侧目标成功率从 80%(5 次 4 中)降至 0%,证实前置摄像头的核心作用是引导末端执行器大致靠近目标。
前置摄像头 3D 信息提供功能验证
在钢笔入架等需深度感知的任务中:

正常摄像头设置下(图 6(a)),机器人可成功完成钢笔入架; 前置摄像头抬高导致场景投影几何改变后(图 6(b)),模型无法完成插入动作,说明前置摄像头能提供关键 3D 投影信息,支撑模型空间推理与操作。
总结与局限
总结
RynnVLA-001 通过 “视频生成预训练→轨迹感知建模→机器人任务适配” 的三阶段流程,结合 ActionVAE 优化动作表示,成功将人类演示中的操作技能迁移到机器人操作任务中。实验表明,该模型在多类抓取、放置任务中表现优异,尤其在含干扰物场景下指令跟随能力突出,为 VLA 模型的预训练策略提供了有效范式。
局限与未来方向
机器人本体适配性:当前仅在 LeRobot SO100 机械臂上验证,未来需扩展到更多类型机器人。 环境泛化性:实验环境与训练环境相似度高,需在更复杂、非结构化环境中测试。 摄像头视角多样性:当前正面摄像头为固定位置,未来需探索多视角动态调整以提升鲁棒性。