作者丨Wenxuan Guo等
编辑丨视觉语言导航
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
作者:Wenxuan Guo, Xiuwei Xu, HangYin, ZiweiWang, Jianjiang Feng, Jie Zhou, Jiwen Lu 单位:清华大学,南洋理工大学 论文标题:IGL-Nav: Incremental 3D Gaussian Localization for Image-goal Navigation 论文链接:https://arxiv.org/pdf/2508.00823 项目主页:https://gwxuan.github.io/IGL-Nav/ 代码链接:https://github.com/GWxuan/IGL-Nav
主要贡献
提出了IGL-Nav框架,通过增量式更新3D高斯表示(3DGS),实现了高效的3D感知图像目标导航,显著优于现有方法。 设计了粗粒度到细粒度的目标定位策略,先利用几何信息进行离散空间匹配实现粗粒度定位,再通过可微渲染优化求解精确定位,有效解决了6自由度相机姿态估计的复杂搜索空间问题。 IGL-Nav能够处理更具挑战性的自由视角图像目标设置,并可部署在真实机器人平台上,使用手机拍摄的任意姿态目标图像引导机器人导航。
研究背景

图像目标导航任务要求智能体在未知环境中导航到由图像指定的位置和朝向,这对于智能体理解空间信息以及基于过往观测探索场景的能力提出了很高要求。 传统方法或依赖端到端的强化学习,或基于模块化策略使用拓扑图或鸟瞰图作为记忆,但都无法充分建模已探索3D环境与目标图像之间的几何关系。 近期虽有基于可渲染神经辐射图(如RNR-Map)的模块化方法取得进展,但其2D投影会丢失关键3D结构信息,限制了在真实场景中的适用性,因此需要一种高效的3D感知记忆表示。
方法

问题定义
论文研究的是自由视角图像目标导航问题,即移动智能体需要导航到由图像 指定的位置和朝向,该图像由相机 A 在位置 拍摄。智能体配备有相机,接收带姿态的 RGB-D 视频流 ,并需要在每个时间步执行一个动作 。任务成功完成的条件是智能体终止在目标姿态的水平邻域内,满足 。 与传统图像目标导航任务相比,自由视角图像目标导航不要求相机 A 和 B 之间存在任何相关性,且目标图像可以由任意相机在任意 3D 位置和姿态下拍摄,这使得任务更具挑战性和实用性。
增量式场景表示
3D 高斯表示(3DGS):采用 3DGS 作为场景表示,因为它具有显式性且渲染效率高。然而,传统的 3DGS 通常是通过离线优化获得的,不适合实时任务。为此,提出了一种前馈式 3DGS 重建模型,能够基于单目 RGB-D 序列进行实时 3DGS 重建和增量式累积。 高斯参数预测:在时间步 ,智能体接收新的 RGB-D 观测 和 。模型 将这些观测映射到 3DGS 参数,包括位置 、透明度 、协方差 和球谐系数 。这些参数是按像素对齐预测的,因此输入图像的大小 对应于输出的 个高斯分布。 模型结构:首先将归一化的 RGB 和深度图像拼接,然后通过基于 UNet 的编码器提取密集的单目场景嵌入 。接着,通过高斯头 (由几个 CNN 和线性层组成)回归 3DGS 参数。利用相机内参矩阵 、姿态 和逆投影 计算 3DGS 位置。 训练与损失:使用被动离线 RGB-D 视频流进行训练。随机从训练集中采样训练片段,随机选择 帧来预测 3DGS 参数,并渲染其他视点的图像以计算损失。训练损失是 L-2 和 LPIPS 损失的线性组合。
由粗到细的目标定位
由于目标图像可以由任意姿态的相机拍摄,目标的搜索空间非常大。为此,设计了一种粗粒度到细粒度的目标定位策略。
粗粒度定位
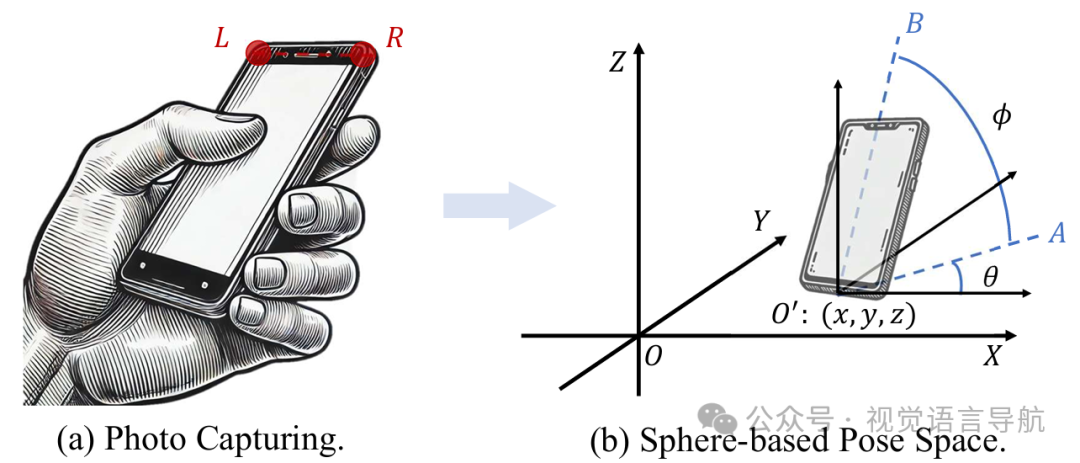
相机姿态表示:观察到拍照时相机顶部通常与地面平行,因此可以将相机姿态用球坐标系表示为 ,其中 表示相机位置, 表示相机旋转。 离散化搜索空间:将 3D 空间离散化为体素网格,将球面表面通过多级细分的正二十面体进行离散化,从而将目标嵌入旋转到这些离散化点,获得 个 3D 嵌入。通过将这些嵌入平移至离散化体素网格,并计算平移嵌入与场景嵌入 之间的对齐程度,确定粗粒度目标姿态。 3D 卷积优化:为了提高实时性,进一步将场景嵌入 和目标嵌入离散化后的表示量化为体素,并将这些嵌入作为 3D 卷积核进行 3D 卷积操作,从而将复杂的对齐计算转化为高效的 3D 卷积操作,大大提高了计算效率。 训练与损失:使用离线被动视频流训练粗粒度定位模块。使用焦点损失监督 3D 卷积后的激活图,并在激活图附近的目标姿态输出上应用交叉熵损失。
细粒度定位
基于渲染的停止器:当智能体接近目标时,使用基于可微渲染的停止器判断目标是否出现在视野中。通过渲染目标图像的相机当前视点的图像,并使用 LoFTR 算法预测目标图像与渲染图像之间的匹配像素对,从而确定目标是否出现在视野中。 匹配约束优化:一旦检测到目标,利用可微渲染优化当前相机姿态。通过在 3D 空间中关注匹配对,优化相机姿态以最小化渲染结果与目标图像之间的几何差异,从而实现精确定位。
导航
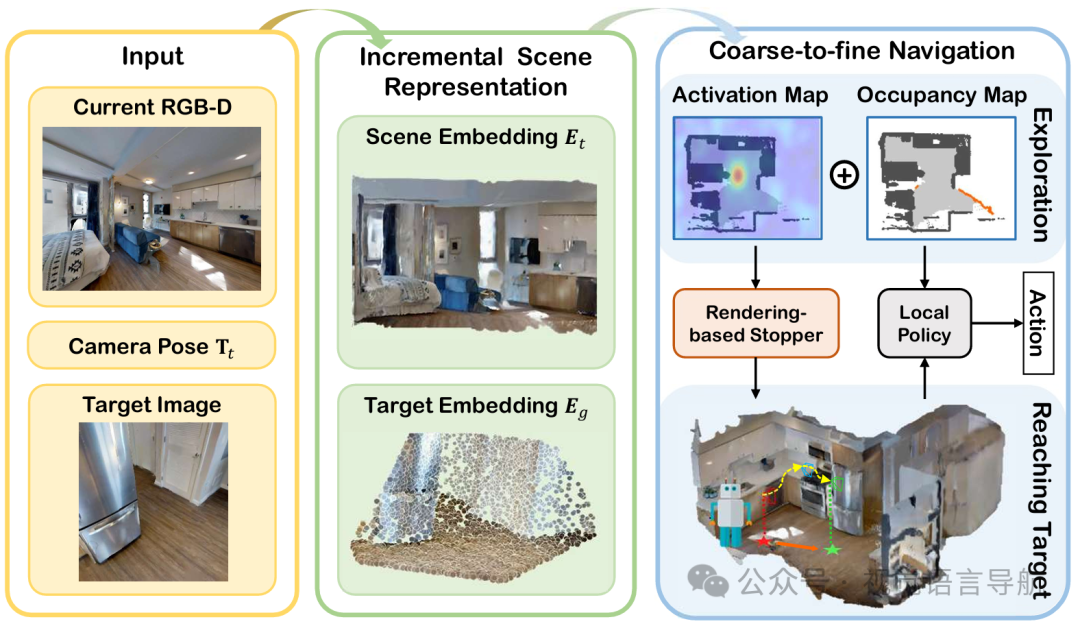
导航过程分为两个阶段:基于粗粒度定位的探索和基于细粒度定位的目标到达。 探索阶段:智能体在新环境中初始化时,其对场景的观测不足,因此结合粗粒度目标定位和基于前沿的探索策略来探索场景并发现潜在目标。基于带姿态的 RGB-D 输入,维护一个在线占用图来指示已探索、未探索和占用区域,在每个时间步选择智能体最近的前沿并生成二进制分数图,将粗粒度目标定位模块获得的激活图投影到该分数图上,智能体优先探索具有最高值的位置。 目标到达阶段:在探索过程中,智能体逐渐接近目标。使用基于渲染的停止器判断目标是否出现在视野中,一旦检测到目标,切换到细粒度定位计算精确目标姿态,并将其作为导航目标,再次应用基于前沿的路径规划方法进行导航。
实验
实验设置
任务:在Habitat模拟器上进行图像目标导航(Image-goal Navigation)和更具挑战性的自由视角图像目标导航(Free-view Image-goal Navigation)任务。 数据集和基准: 图像目标导航任务:使用Gibson数据集,包含72个房屋用于训练和14个用于验证。数据集分为“直线”和“曲线”两种路径类型,每种路径类型又分为“简单”、“中等”和“困难”三个难度级别。 自由视角图像目标导航任务:收集了大量新的Gibson数据集用于验证。根据相机视野角(FOV)分为两组:50°~75°和75°~100°。每组又根据与目标的距离分为三个难度级别。与传统的图像目标导航任务相比,自由视角图像目标导航任务的目标图像是从任意角度和高度拍摄的,更加接近真实场景。 对比方法:与现有的最先进图像目标导航方法进行比较,包括DDPPO、NRNS、ZSEL、OVRL等方法。对于自由视角图像目标导航任务,还评估了这些方法在新设置上的零样本迁移性能。
与最先进方法的比较

图像目标导航任务: IGL-Nav在所有指标上均大幅超越了现有的最先进方法。 在不同路径类型和难度级别上,IGL-Nav的成功率(SR)和路径长度加权成功率(SPL)都显著高于其他方法。例如,在“简单”级别上,IGL-Nav的成功率和SPL分别为87.9%和82.5%,远高于第二名FeudalNav的82.6%和75.0%。

自由视角图像目标导航任务: 自由视角图像目标导航任务更具挑战性,所有方法的性能都有所下降。 在零样本迁移的情况下,IGL-Nav依然保持了显著的性能优势。经过针对该任务的数据训练后,IGL-Nav的性能进一步提升,成功率和SPL指标均大幅领先。 例如,在窄视野角(50°~75°)的“总体”级别上,IGL-Nav的成功率和SPL分别为70.4%和64.2%,远高于其他方法,如NRNS的成功率24.5%和SPL19.3%。
IGL-Nav的模块分析


增量式3D高斯表示(3DGS): 在没有深度信息和相机内参的情况下,使用单目深度估计器预测这些信息,IGL-Nav的性能依然稳健。 渲染结果表明,即使在增量式更新和前馈式预测的情况下,3DGS表示仍能实现逼真的新视图合成。

粗粒度定位模块: 通过改变球面的细分级别(γ)来调整离散化精度,发现3级细分(γ=3)能够取得最佳性能。 细化的离散化可以降低量化误差,提高粗粒度定位的精度,但会增加计算成本。

精定位模块: 对比了不同的停止器,包括LoFTR(IGL-Nav使用的方法)和SLING。结果表明,基于3DGS的停止器和匹配约束优化更适合IGL-Nav的导航系统。 例如,在窄视野角情况下,IGL-Nav的成功率和SPL分别为57.0%和48.2%,而使用SLING作为停止器的成功率和SPL分别为49.0%和40.7%。 导航过程的可视化显示了IGL-Nav如何在部分观测下有效地定位目标图像,并通过精细的渲染优化引导智能体到达最终位置。

真实世界部署

在真实机器人平台上部署IGL-Nav,直接使用从自由视角图像目标导航任务中训练的模型,无需对真实世界数据进行微调。 使用手机拍摄的目标图像引导机器人导航,结果表明IGL-Nav能够有效地引导机器人到达目标位置,展现了其强大的泛化能力和从模拟到真实环境的迁移性能。
结论与未来工作
结论: IGL-Nav通过增量式维护3DGS场景表示,并利用其进行粗粒度到细粒度的目标定位,在图像目标导航和自由视角图像目标导航任务中均取得了优异的性能,并且在真实世界中的部署也证明了其泛化能力。 IGL-Nav的一个限制是需要目标图像的深度和相机内参信息,但实验表明使用现有的单目深度估计方法可以较好地解决这一问题。 未来工作: 可以考虑进一步优化3DGS表示的更新和优化过程,以提高导航的效率和精度; 还可以探索如何更好地将IGL-Nav与其他导航技术或模块结合,以应对更复杂的导航场景和任务; 此外,针对目标图像深度和相机内参的预测方法也可以进一步改进,以提高在真实世界应用中的鲁棒性。

本文只做学术分享,如有侵权,联系删文










