如您有工作需要分享,欢迎联系:aigc_to_future
作者:Yanghao Li等
解读:AI生成未来

文章链接:https://arxiv.org/pdf/2509.16197


亮点直击
hybrid tokenizer 设计巧妙:通过共享编码器+双适配器结构,在一个语义空间中同时支持连续和离散表征,显著缓解了理解与生成之间的任务冲突。 统一且可扩展的训练配方:三阶段训练策略有效整合多样数据,支持模型同时学习理解和生成,并具备良好的扩展性。 强竞争力与扩展性:小模型(3B)即可达到SOTA, scaling实验表明模型能力随参数增加持续提升,尤其在文本丰富任务和图像结构完整性上表现突出。
总结速览
解决的问题
现有开源统一多模态大语言模型(LLMs)在图像理解与图像生成能力之间存在明显的性能权衡,通常顾此失彼。 生成任务偏好离散图像token,而理解任务更受益于连续嵌入,这种表征冲突导致模型性能下降,尤其在文本密集(text-rich)任务上表现显著落后于专用模型。 现有解决方案(如双tokenizer或混合专家模型)存在参数效率低、架构复杂或无法有效协同 scaling 等问题。
提出的方案
提出Manzano,一个简单且可扩展的统一多模态框架,核心是混合图像分词器(hybrid image tokenizer) 和精心设计的训练策略。 使用一个共享视觉编码器,搭配两个轻量适配器: 连续适配器:为图像理解任务输出连续嵌入; 离散适配器:为文本到图像生成任务输出离散token。 采用统一的自回归LLM同时预测文本和图像token,再通过一个辅助扩散解码器将图像token转换为像素。
应用的技术
混合分词器:基于同一视觉编码器生成连续和离散表征,减少任务冲突。 三阶段训练配方:
预训练:在大规模纯文本、图文交错、图像到文本(IT)、文本到图像(TI)数据上进行; 继续预训练:使用更高质量的IT和TI数据; 有监督微调(SFT):使用精心策划的指令数据提升理解和生成能力。
达到的效果
在统一模型中实现了SOTA性能,在理解和生成任务上均表现优异。 在文本密集型评估中媲美专用模型,且模型规模更小(如3B参数即达到竞争性性能)。 实验显示任务冲突极小,联合训练有效;模型能力随LLM decoder(300M→30B)和扩散解码器的扩大而持续提升。
模型
Manzano 是一个统一理解与生成任务的多模态大语言模型(MLLM),采用自回归(AR)方法实现。其架构包含三个组成部分:
一个混合视觉分词器,可同时生成连续和离散的视觉表示; 一个LLM解码器,可接收文本token和/或连续图像嵌入,并以自回归方式从联合词汇表中预测下一个离散图像或文本token; 一个图像解码器,用于将预测出的图像token渲染为图像像素(框架见下图3)。

设计选择
统一的混合表示。
混合图像分词器将图像编码为用于理解(I2T)的连续token和用于生成(T2I)的离散token,同时共享同一个视觉编码器。
I2T 任务使用连续表示。
Manzano 在 I2T 任务中使用连续嵌入,这一策略已被主流视觉理解模型广泛采用,并被证明具有优越性能,尤其是在需要更多视觉细节的文本密集型任务(如 DocVQA、ChartQA 和 InfoVQA)中。我们的消融实验(表1)也表明,离散token在理解任务上表现较差,这也反映了一些纯离散统一模型在理解任务上的较弱结果。T2I 任务使用离散表示。
将图像表示为离散代码索引使LLM能够采用与文本相同的自回归下一token学习策略,从而简化生成流程并改善扩展行为。共享的统一语义空间。
两个分支源自同一编码器主干,因此连续与离散token处于共同的语义空间中,这减少了潜在的任务冲突。
LLM解码器专注于回归高层语义(文本和图像token),而扩散解码器负责在像素空间中渲染高保真细节。许多现有的统一模型为理解和生成使用独立的分词器——例如,使用CLIP分词器处理理解任务,使用VAE分词器处理生成任务。尽管该策略保留了更多图像空间细节,但它加剧了后续LLM内部的任务冲突。一些研究[9,10]发现,专用的生成分词器与LLM的兼容性不如语义分词器。因此,我们采用的混合统一图像分词器使用单一图像编码器处理理解和生成两类任务。
简洁性与可扩展性。
我们的设计保持训练损失的标准性以及各组件的清晰解耦,从而简化了统一MLLM的统一化与扩展过程。
统一的自回归目标。
我们的统一LLM解码器对纯文本、I2T 和 T2I 任务使用单一的自回归目标,无需额外的辅助损失或针对不同任务的输出头。解耦的组件。
语义预测(LLM解码器)与细节生成(图像解码器)之间的清晰分离支持基础LLM与图像解码器的独立扩展。实用的扩展机制。
本文的方法能够直接利用来自LLM/MLLM以及扩散解码器的成熟、可扩展的训练流程。相比之下,先前的工作(例如 Transfusion和 Bagel)尝试在单一LLM中融合自回归文本预测和扩散图像生成过程以进行图像生成,但大规模扩展方面的探索仍显不足。我们解耦式的设计有助于将LLM解码器扩展至30B参数,扩散解码器扩展至3B参数,并展现出良好的扩展特性。
架构
混合图像分词器。
本文的分词器包含三个组件:(i)一个标准视觉Transformer(ViT)作为视觉主干;(ii)一个连续适配器,首先应用一个的空间到通道(STC)层将空间token数量减少至1/9(例如,从减少到),然后使用一个MLP将每个特征投影到LLM特征维度(例如2048);(iii)一个离散适配器,同样以STC压缩步骤开始,但随后使用有限标量量化(FSQ)对特征进行进一步量化——选择该方法是因为其简单性以及对大码本(实验中为64K)的良好扩展性——最后再通过一个MLP投影到LLM特征维度。
统一LLM。
将混合图像分词器连接到一个标准文本LLM解码器上,以便在包含文本、理解数据和生成数据的混合数据集上进行统一训练。对于语言主干,利用预训练的LLM。
图像解码器。
在预训练的混合图像分词器之上训练一个图像解码器,以从离散图像token重建像素空间中的图像。给定输入图像,混合分词器首先将其编码为潜在表示,该表示作为流匹配(flow-matching) pipeline的条件输入,该pipeline将高斯噪声转换为真实图像。对于解码器主干,本文采用DiT-Air架构,该架构采用分层参数共享策略,将标准MMDiT模型的尺寸减小约66%,同时保持相当的性能。我们提供了三种解码器配置,参数规模分别为0.9B、1.75B和3.52B,支持从256到2048像素的一系列输出画布分辨率。
推理流程。
前面图3(右)展示了理解和生成任务的推理流程。对于理解任务,Manzano使用混合图像分词器提取连续特征。这些特征与文本特征一起被输入统一LLM解码器,以预测最终答案。对于生成任务,Manzano接收文本输入并预测一个图像token序列。图像解码器随后将这些token渲染为图像像素。
训练
数据
我们的训练数据混合了纯文本、图像理解和生成数据,分为预训练、继续预训练和监督微调(SFT)三个阶段。我们利用高质量的纯文本数据进行预训练和SFT,以保持Manzano模型的语言建模能力。
预训练与继续预训练
理解。本文使用两种类型的图像理解数据:描述性数据(配对的图像和文本描述)和交错图文数据。对于描述性数据,我们组合使用了多个来源的23亿个图文对,包括CC3M、CC12M、COYO、VeCap和内部许可数据。这些数据经过过滤和重新描述处理以确保高质量。对于交错数据,使用了来自[40]的17亿个文档和网络爬取的交错数据,类似于MM1和MM1.5的做法。
在继续预训练阶段,进一步使用2400万高质量能力导向数据进行训练,包括文档、图表、多语言OCR、知识与推理、高质量合成描述数据,所有这些数据都启用了图像分割功能。
生成。图像生成预训练数据包含10亿个内部文本-图像对。本文使用不同的描述生成模型生成合成描述。在继续预训练阶段,我们选择了一个高质量的许可图像子集,并使用更强大的MLLM重新为它们生成描述,生成的长度从20到128个token不等。
监督微调
理解。遵循MM1.5的方法,我们最终的理解SFT方案包含75%的图文数据和25%的纯文本数据。图文部分进一步由约30%的通用知识数据、20%的文档和图表理解数据以及25%的视觉思维链(CoT)和内部生成的推理数据组成。
生成。本文的文本到图像SFT数据包括精心策划的真实数据和合成数据的混合。从DreamO数据集的真实世界文本-图像对开始。然而,我们观察到仅在该数据集上训练,虽然对于标准的基于扩散的生成器足够,但会导致我们的统一自回归模型过拟合。为了缓解这个问题,用合成样本扩展了训练数据。首先,纳入了来自成熟数据集的9万个文本-图像对,包括DALLE3-1M、BLIP-3o和ShareGPT-4o。其次,为了达到更大规模,通过将JourneyDB中的提示输入到开源独立扩散模型Flux.1-schnell中,生成了额外的400万个对。
训练方案
混合分词器训练
混合图像分词器旨在产生两种类型的token:用于理解的连续token和用于生成的离散token,这些token与多模态LLM语义空间进行了预对齐。
首先使用CLIP预训练视觉编码器(ViT)。然后我们通过两个并行的连续和离散适配器将一个预训练的小型LLM解码器(300M)连接到共享视觉编码器(见图3-左)。对于每个训练样本,我们随机选择一个适配器,并将相应的嵌入馈送到LLM解码器,该解码器使用下一token预测进行训练。我们解冻所有参数,并在各种理解数据领域上训练模型,包括通用知识、推理和文本密集型任务。
此过程增强了分词器的理解能力,包括高层语义理解和细粒度空间细节。同时,两个分支也被对齐到同一空间。我们按照第4.1节中描述的理解和纯文本数据,进行预训练、继续预训练和SFT阶段。
训练完成后,丢弃小型LLM解码器,保留得到的混合图像分词器,然后将其用作统一LLM和图像解码器的视觉输入模块。
统一LLM训练
如下图4-左所示,我们冻结视觉编码器和离散适配器的参数,以在训练期间保持图像token词汇表的固定。我们按照分词器中FSQ层的相同码本大小,用64K个图像token扩展了LLM嵌入表。
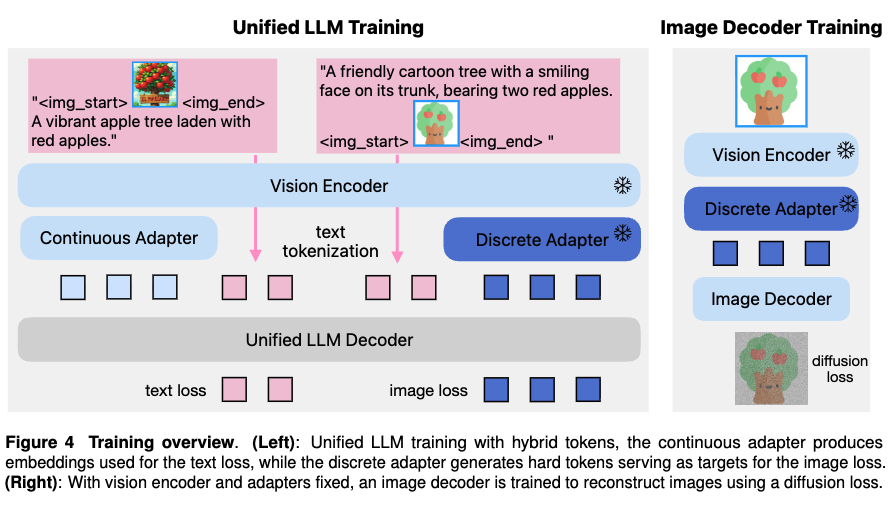
对于图像理解,图像分词器从输入图像中提取连续特征,并将其直接馈送到LLM中,并在文本目标上计算标准下一token损失。对于图像生成,分词器使用其离散适配器将输入图像转换为离散图像token ID序列,这些ID通过扩展的LLM嵌入表映射到图像token。然后,LLM仅对这些图像token计算交叉熵损失。为了平衡理解任务和生成任务的训练,将文本损失与图像损失的权重比设置为1:0.5。
在三个阶段训练统一LLM。预训练和继续预训练使用第4.1.1节中描述的图像理解、图像生成和纯文本数据的40/40/20混合比例。我们在预训练期间使用1.6T token(30B模型使用0.8T token)进行训练,并在继续预训练期间额外使用83B token。类似地,SFT阶段使用第4.1.2节中的数据集,按41/45/14的混合比例使用精心策划的理解、生成和文本指令数据。
图像解码器训练
本文的图像解码器按照渐进式分辨率增长范式进行训练。我们首先在分辨率下预训练解码器40万步。随后,模型在、和的更高分辨率上逐步进行微调,每个阶段训练较短的计划10万步。对于每个阶段,仅使用短边大于目标分辨率的图像进行训练。
实验
评估
本文在流行的基准测试上评估模型在图像理解和生成方面的能力。
理解。采用以下三类基准进行多模态理解评估:
通用VQA:SeedBench、RealWorldQA和MMBench。 知识与推理:AI2D、ScienceQA、MMMU和MathVista。 文本密集型文档与图表理解:ChartQA、TextVQA、DocVQA、InfoVQA和OCRBench。
生成。使用自动评估和人工评估两种方式:
自动评估:自动基准测试包括用于提示跟随生成的GenEval和DPGBench,以及用于世界知识 informed 生成的WISE。 人工评估:我们策划了一个包含800个具有挑战性提示的综合评估集,这些提示从已建立的学术基准和广泛使用的社区评估平台中二次抽样得出。生成的输出由内部人工评估员在三个维度上进行评估:结构完整性、指令遵循和美学质量。对于每个维度,评估员分配三个等级之一:严重问题、轻微问题或无问题,随后量化为分数。为减少偏差,实体信息被掩盖,样本顺序随机化。每个样本由三名评估员独立评分,最终分数通过评估员间的平均得出以减少变异性。
理解-生成的相互作用
本节从两个轴研究任务冲突:(i)分词器策略(纯离散 vs. 双编码器 vs. 我们的混合策略);(ii)任务混合(统一 vs. 单任务)。为简化起见,我们在这些消融实验中跳过了统一LLM训练中的继续预训练阶段。
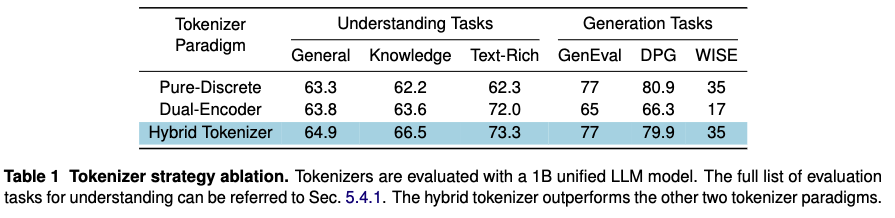
分词器策略。构建了两个基线来比较统一混合分词器策略:
纯离散。先前的工作使用各种量化技术训练量化的语义视觉分词器,然后使用LLM预测下一个文本和图像token。为了在我们的设置中模拟这些方法,我们将LLM的理解输入替换为来自我们混合分词器的离散特征,因此LLM对理解和生成使用相同的离散token。为了隔离量化对理解的影响,我们使用与混合分词器中相同的视觉编码器和离散适配器权重。 双编码器。另一种流行模型使用双编码器策略,通过语义编码器保留详细特征以用于理解,并通过VAE风格编码器用于生成,有效减轻了理解性能的下降。我们通过将混合分词器中的离散token替换为由内部复现的MagViT-2(一种自编码器风格的分词器)生成的token来复现此基线。该MagViT-2分词器使用FSQ,具有64K码本和8的空间压缩比。对于生成任务,我们将图像大小调整为像素,而不是原始的。这将每幅图像的token数量减少到256个,提高了模型在基准测试中的指令遵循能力。
下表1显示了图像理解和生成任务的结果。混合分词器范式显示出最小的任务冲突,并在所有任务上优于纯离散和双编码器基线。纯离散基线导致理解性能显著下降——尤其是在文本密集型基准测试中,这是由于量化造成的信息损失。虽然双编码器基线减轻了部分性能下降,但在所有理解任务上——尤其是在严重依赖LLM推理能力的知识基准测试上——它仍然 consistently 表现不如我们的混合分词器。这表明异构视觉token之间的冲突存在于LLM内部。
统一 vs. 单任务。为了量化我们混合分词器范式中的任务冲突,将本文的统一模型与专门为理解或生成训练的基线进行比较。对于仅理解基线,我们从预训练和SFT阶段移除了所有文本到图像数据。我们减少训练步数,确保其接触到的文本和图像理解token数量与本文的统一模型相同。类似地,对于仅生成基线,我们移除理解数据,仅保留纯文本和文本到图像数据,同时减少训练步数。使用300M和3B的LLM解码器进行了此消融研究。下图5a和5b中绘制的结果表明,使用我们的混合分词器训练的统一LLM在几乎所有任务上的表现与专用的单任务模型相当,即使在300M这样紧凑的规模下也是如此。这表明本文的统一混合分词器范式成功统一了视觉感知和生成,而没有性能权衡。

模型扩展行为
借助LLM解码器和图像解码器的解耦设计,沿着两个维度探索模型扩展行为:LLM解码器和图像解码器。在扩展实验中跳过了统一LLM训练中的继续预训练阶段。
扩展LLM解码器。仅改变LLM解码器的大小(300M、1B、3B和30B),同时保持图像解码器(0.9B)、数据混合和训练超参数固定。下图6a显示,随着LLM解码器的扩展,所有理解(通用/知识/文本密集型)和生成(GenEval/DPG/WISE)指标均获得单调提升。与300M相比,我们的3B Manzano模型显著提高了+14.2(通用)、+18.8(知识)、+10.9(文本密集型)、+11.0(GenEval)、+1.48(DPG)和+12.0(WISE)。进一步扩展到30B相比3B产生了较小但一致的增益。下图7展示了图像生成的定性示例。我们可以看到,包括指令遵循、文本渲染和整体图像质量在内的生成能力在不同LLM规模下 consistently 得到改善。这些结果支持了Manzano简单而有效的设计:LLM解码器捕获高层语义,扩展它有益于理解和生成。
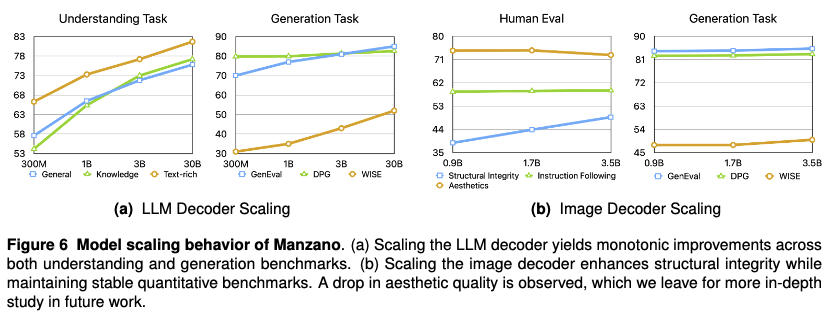

扩展图像解码器。评估了建立在3B LLM解码器之上的不同大小图像解码器的性能。图6b显示,在人工评估中,结构完整性显著提高(+9.9),而指令遵循性能保持不变。观察到美学质量略有下降。对于自动生成基准测试,GenEval和DPGEval上的性能几乎相同,而WISE表现出适度改善(+2.0)。
要点。扩展统一LLM主干 consistently 改善理解和生成,在文本密集型理解任务和生成的WISE上收益显著。扩展图像解码器也提高了图像质量,且对理解没有负面影响。我们观察到,当模型变大时,GenEval和DPG基准测试的性能趋于饱和。这种饱和促使重新审视如何评估统一模型的涌现能力,因为现有基准测试可能仅捕获整体能力的有限部分,并可以通过有针对性的数据调优来提升。同时,我们观察到世界知识生成任务的显著改进,希望这些发现为未来社区研究的新方向铺平道路。
与统一模型和专用模型的比较
本节在各种基准测试上评估我们的Manzano模型在图像理解和文本到图像生成方面的能力。为全面评估我们模型的性能,将其与SOTA统一模型和专用模型(即仅理解模型和独立生成模型)进行比较。
图像理解
从三个角度评估模型的理解能力:知识与推理、通用视觉问答以及文本密集型文档与图表理解。下表2所示的结果将本文的模型与类似大小的其他仅理解模型进行了比较。尽管是一个统一模型,本文的模型在许多理解基准测试上实现了最先进的性能,尤其是在文本密集型任务上。
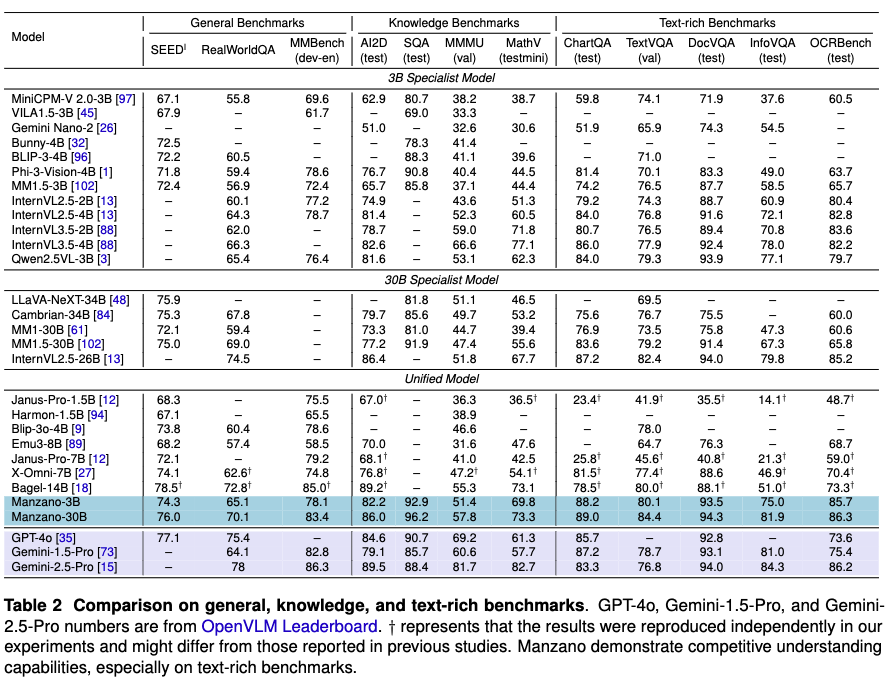
知识与推理。在3B规模上,本文的模型优于7B规模内的所有统一模型,并达到与3B规模最佳专用模型相当或更好的性能。在30B规模上,本文的模型在ScienceQA、MMMU和MathVista基准测试中排名第一,在AI2D基准测试中排名第三,在这些类别中优于所有其他统一和专用模型。值得注意的是,本文的模型在ScienceQA上超过了最后三行列出的专有模型,并在AI2D基准测试上与当前最先进的模型具有竞争力。
通用视觉问答。对于通用视觉问答,本文的模型尽管规模较小,但通常优于其他统一模型。它在两个规模上也与最先进的专用模型取得了竞争性结果。
文本密集型文档与图表理解。在文本密集型和图表理解任务上,与所有其他统一模型、专用模型和专有模型相比,本文的模型在五个基准测试中的四个(ChartQA、TextVQA、DocVQA和OCRBench)上取得了最佳性能。对于InfoVQA任务,本文的模型显著优于其统一对应模型,并在专用模型中取得了最佳结果。
图像生成
展示了模型图像生成能力的定量结果,并在两个基准测试上进行了评估:GenEval和WISE。虽然两个基准测试都评估模型遵循文本指令的能力,但WISE还通过世界知识 informed 属性评估语义 grounding。如表3所示,本文的模型在GenEval和WISE上均实现了统一MLLM中的SOTA结果。3B模型已经能够与更大的统一模型竞争或表现更好,而扩展到30B进一步提高了生成质量——最显著的是在WISE上获得了巨大收益,同时保持了强大的GenEval性能。这证实了我们的统一架构和训练方案支持强大的指令遵循生成。
与统一模型的比较
除了专用模型,还与最近的统一模型(如Janus-Pro、X-Omni和Bagel)进行了比较,这些模型旨在单个框架内同时处理理解和生成任务。Manzano模型在几乎所有理解基准测试上都显著优于这些统一基线。在相似规模下,我们的3B模型在DocVQA、OCRBench和SEEDBench上超过了X-Omni和BAGEL,同时在MathVista和ChartQA上保持了竞争性性能。30B模型进一步扩大了这一领先优势, consistently 在知识、通用VQA和文本密集型领域超越所有现有统一模型。这表明统一不必以牺牲理解能力为代价。通过精心的架构和训练设计,本文的模型匹配或超越了最佳专用模型,同时提供了强大的生成能力。图8中提供了与最先进统一模型的更多定性比较。

图像编辑的能力扩展
图像编辑既是关键应用,也是文本到图像生成的自然延伸。尽管Manzano展示了强大的多模态建模能力,尤其是在文本密集型理解基准测试上,但在细粒度图像编辑中实现像素级精度仍然具有挑战性。类似地,解耦LLM-扩散范式中的近期工作报告称,仅依赖LLM进行精确编辑存在困难,因为LLM缺乏直接像素级控制的本机机制。
将参考图像同时提供给LLM和扩散解码器。在这种 formulation 中,LLM负责多样化的指令遵循和保持语义连贯性,而扩散解码器则强制执行精确的像素级控制。通过联合以参考图像为条件,Manzano能够实现准确的语义指令遵循,同时保持细粒度的视觉一致性。在图9中,Manzano展示了多功能的编辑能力,包括指令引导编辑、风格迁移、修复、外绘和深度估计。

结论
Manzano,这是一个通过混合图像分词器和统一自回归主干结合视觉理解与图像生成的MLLM。LLM以文本和图像token的形式预测高层语义,而轻量级的基于扩散的图像解码器则根据生成的图像token渲染最终像素。结合简化的三阶段训练方案,该架构实现了:(i)理解任务的最先进性能,(ii)在统一模型中生成能力的显著提升,以及(iii)通过相互作用和扩展消融实验验证的最小任务干扰。除了生成,Manzano通过以参考图像为条件同时作用于LLM和图像解码器,自然支持图像编辑,实现了具有像素级控制的指令遵循。
参考文献
[1] MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











