编辑:冷猫
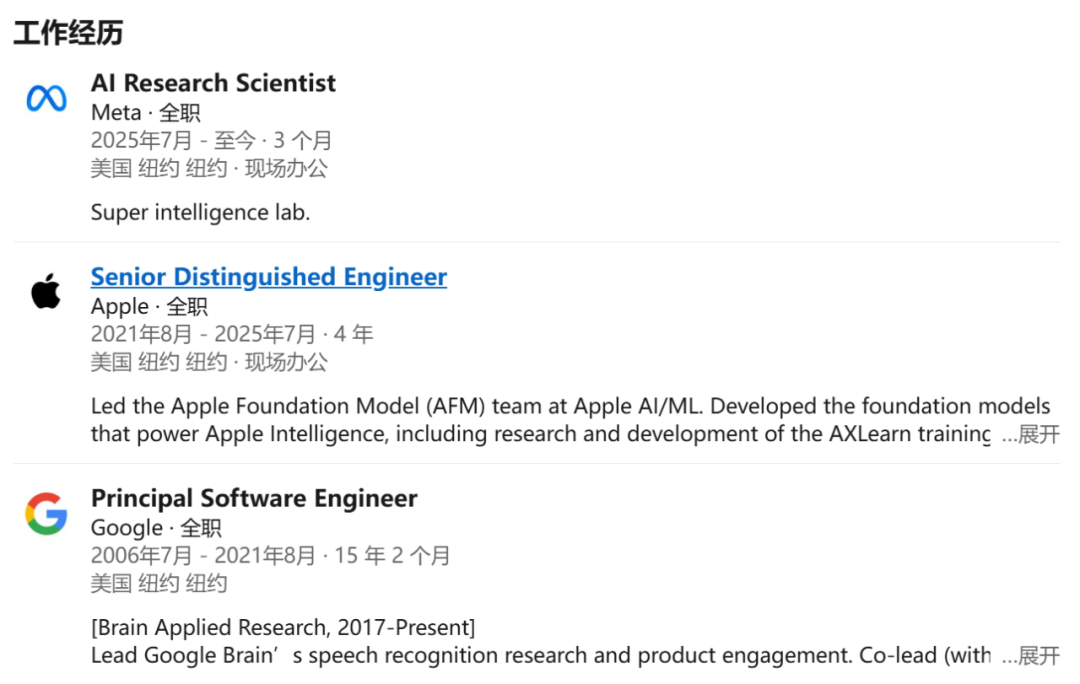
数月前,苹果基础模型团队负责人、杰出工程师庞若鸣(Ruoming Pang)离职加入 Meta。扎克伯格豪掷两亿美元招揽庞若鸣加入超级智能团队。
根据庞若鸣的领英信息,他已在 Meta 工作了大约三个月的时间。
但令我们出乎意料的是,这两个多月来,庞若鸣在苹果参与的工作还在不断发表中,其中仍不乏一些高价值研究。
在苹果期间,庞若鸣领导着苹果基础模型团队,主要负责开发 Apple Intelligence 及其他 AI 功能的核心基础模型的工作。庞若鸣的工作在推动基础大模型进步的领域中具有很高的影响力和研究价值。
就比如我们即将介绍的这一个:

论文标题:Synthetic bootstrapped pretraining
论文链接:https://arxiv.org/html/2509.15248v1
我们知道,大规模的语言模型是以海量的互联网文本作为基础进行训练的,受到规模效应「Scaling Law」的影响,数据量越大,多样性越强,模型的能力也会有相应的提升。
但从互联网上获取的数据不可能无限制的增加。准确的说,我们已经达到了真实数据规模的瓶颈:高质量文本数据已经在迅速枯竭。我们已经触及到了「规模壁垒」,因此在大模型训练中亟需重新思考如何更高效地利用现有数据。
在大模型训练中,预训练的成功主要依赖于文档内部 token 之间丰富的因果关联。然而,这并不是预训练数据集中唯一存在的相关性来源。例如:
一个实现注意力机制的代码文档,往往源自 Transformer 论文的 arXiv 预印本;
《哈利・波特》的小说在结构上与其电影剧本存在相似性。
这些现象表明,除了文档内部的强相关性之外,还存在一种较弱的跨文档相关性,它来源于预训练文档的某种潜在联合分布。
根据以上发现,研究团队提出了假设:
这种额外的信号在标准预训练过程中被忽视,而它可以通过合成数据加以捕捉。这为提升模型性能提供了一条尚未被充分探索的路径。
为充分利用这一潜在机会,研究者们提出了 Synthetic Bootstrapped Pretraining (SBP),一种新的语言模型预训练流程,分为三个步骤:
相似文档对识别:SBP 首先在预训练数据集中识别语义上相似的文档对 d1,d2,例如 Transformer 论文及其代码实现。
条件建模:SBP 接着对 d2|d1 的条件概率进行建模,从而构建一个「数据合成器」,该模型能够在给定种子文档的情况下生成新的、相关文档。
数据扩展:最后,SBP 将训练好的条件合成器应用于整个预训练语料库,从而生成一个大规模的新文本语料。该语料显式编码了原始预训练中未被利用的跨文档相关性。
通过直接从预训练语料库中训练数据合成器,SBP 避免了依赖外部教师语言模型来「拔高」性能的陷阱,从而保证了改进来源于对同一预训练数据的更优利用。

SBP 的三步流程:(1) 通过最近邻搜索识别语义相似的文档对,(2) 训练一个合成器模型来生成相关内容,以及 (3) 扩展合成以创建用于与原始数据联合训练的大型语料库。
核心问题
大规模语言模型正面临所谓的 「规模壁垒」:可用于预训练的高质量、独特文本语料正在迅速枯竭。现有的标准预训练方法主要依赖 下一词预测,学习单个文档内部的 token 级依赖关系。虽然这种方法在实践中取得了显著效果,但它基本忽视了一类潜在的、极其丰富的信号 —— 语料中不同文档之间的关联关系。
例如,一篇研究论文及其对应的代码库,或者一部小说及其影视改编,本质上存在深层的概念联系,尽管它们在形式和风格上迥异。现有的预训练范式将它们视为完全无关的样本,从而丢弃了这些跨文档关系所蕴含的价值。
合成自举预训练(Synthetic Bootstrapped Pretraining, SBP) 正是为了解决这一问题,通过将文档间的相关性转化为新的训练信号。
SBP 通过三个顺序执行的步骤,将跨文档关系转化为合成训练数据:
步骤 1:最近邻配对
首先,在原始预训练语料中识别语义相似的文档对。具体而言,每个文档都通过一个较小的外部模型(Qwen3-Embedding-0.6B)编码为 1024 维向量。随后,系统使用 ScaNN 并结合 8-bit 量化 来进行近似最近邻搜索,以保证计算效率。
当文档对的相似度分数高于 0.75 阈值时,认为其足够相关并选入候选集合。为避免语料冗余,一个关键的过滤步骤是基于 「shingles」 (13-token 滑动窗口) 检查重叠情况,移除近似重复的文档对,从而确保配对结果具备真正的新颖性,而不是简单的重复。
步骤 2:合成器调优
基于已识别的文档对,SBP 训练一个条件语言模型,以学习相似文档之间的关系模式。值得注意的是,这一「合成器」与主语言模型使用相同的 Transformer 架构,并且从已有的预训练检查点初始化,从而继承了基础语言理解能力。
合成器的目标是最大化如下条件概率: 。其中,d1 是种子文档,d2 是与之相关的文档。这一训练过程促使模型理解同一概念如何能够在不同的文档类型、写作风格和语境中被表达出来。
。其中,d1 是种子文档,d2 是与之相关的文档。这一训练过程促使模型理解同一概念如何能够在不同的文档类型、写作风格和语境中被表达出来。
步骤 3:大规模数据合成
训练完成的合成器会应用到整个原始语料库,以生成一个庞大的新语料集。具体来说,对于原始语料库中采样得到的每一个种子文档 d1,合成器都会通过温度采样(temperature = 1.0, top_p = 0.9)生成一个新的文档 d2。
在生成之后,系统会对合成结果进行过滤,去除存在过多内部重复的文档,以确保合成语料的质量。最终,合成语料与原始数据集结合,用于主语言模型的联合训练。一个核心原则是:合成文档在训练过程中不会被重复使用。
理论基础
作者们从贝叶斯视角解释了 SBP 的有效性。他们将文档生成建模为对潜在概念的后验分布进行采样:

其中,c 表示潜在概念,d 表示文档。合成器在隐式学习过程中会从种子文档中推断这些潜在概念,然后生成新的文档,以不同的方式来表达同一概念。
这种方式使得语言模型能够在训练中以多样化的形式多次接触相同的知识,从而获得更强的泛化能力和表达能力。
实验结果
这项研究使用基于 Llama 3 架构的 3B 参数 Transformer 模型,并在包含 5.82 亿文档和 4820 亿 token 的 DCLM 数据集的定制版本上进行训练,在多个规模和评估指标上验证了 SBP。

测试损失曲线表明,SBP(红色)始终优于基线重复方法(黑色),并接近于拥有大量独特数据的「Oracle」模型(灰色虚线)的性能。
性能提升
SBP 在 200B-token 和 1T-token 的训练规模下,都比强大的基线模型表现出持续的改进。
在 200B 规模下,该方法实现了拥有 20 倍以上独特数据的「Oracle」模型所获得性能增益的 42%;在 1T 规模下,则实现了 49%。这些结果表明 SBP 从固定数据集中提取了大量的额外信号。

SBP 与 oracle 在重复基线上的性能增益对比。平均而言,SBP 在问答准确率上的提升,大约相当于 oracle 在拥有 20 倍更多独特数据时所能带来的性能提升的 47%。
训练动态显示,尽管 SBP 在初期可能略逊于基线,但随着训练的进行,其性能持续提升,而基线则趋于平稳。这表明合成数据提供了真正的新信息,而非简单的重复。
质量分析
对合成文档的定性检查表明,SBP 超越了简单的释义。合成器从种子文档中抽象出核心概念,并围绕它们创建新的叙述。例如,一篇关于圣地亚哥咖啡馆的种子文档可能会生成关于浓缩咖啡机比较或咖啡文化散文的合成内容,在保持主题相关性的同时引入新的视角和信息。

原始文本与合成文本变体的对比。
定量分析证实,合成数据在多样性和缺乏重复性方面保持了与真实数据相当的质量,而在更大的训练规模下,事实准确性显著提高。

在 200B 规模和 1T 规模下从合成器采样文档的定量评估。
意义与影响
SBP 通过将重点从获取更多数据转向从现有数据中提取更多价值,解决了大型语言模型可持续发展中的一个根本性挑战。该方法提供了几个关键优势:
数据效率:通过学习文档间的相关性,SBP 使模型能够从固定语料库中获取更丰富的训练信号,从而可能延长现有数据集的有效寿命。
自我改进:与依赖外部教师模型或人工标注的方法不同,SBP 通过使用相同的架构和数据进行自我引导来实现性能提升,使其具有广泛的适用性。
理论基础:贝叶斯解释提供了对该方法为何有效的原理性理解,表明它实现了超越表面级 token 模式的概念级学习形式。
互补效益:实验表明,SBP 的改进与模型规模扩展带来的改进是正交的,这表明它可以整合到现有的扩展策略中以获得额外的性能提升。
这项工作为数据高效训练开辟了新的研究方向,并表明通过更复杂的利用策略,现有数据集仍可实现显著改进。随着该领域接近根本性数据限制,SBP 等方法可能对语言模型能力的持续进步变得至关重要。
更多信息,请参阅原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com