
近日,硅谷AI芯片新创公司Groq成功完成7.5亿美元融资,公司估值飙升至69亿美元。这笔顶级投资不仅是当前AI热潮下的一个标志性事件,更表明Groq已成为英伟达(NVIDIA)在特定市场领域潜在的关键挑战者,预示着AI芯片市场正迎来一场结构性变革。
Groq的核心战略是避开AI模型训练的激烈红海,转而专注于被NVIDIA通用型GPU所忽视的AI推理蓝海市场。Groq独有的LPU(语言处理单元)架构,专为处理实时、低延迟的生成式AI任务而设计,旨在从根本上解决通用芯片在处理大型语言模型时的延迟和存储器瓶颈,以惊人的速度和能效优势开辟全新的市场空间。
尽管NVIDIA凭借其约80%的市场份额和深不可测的CUDA软件生态系统,仍保有绝对的市场主导地位,但高昂的GPU成本、供应短缺及对单一供应商的依赖,已让市场“苦”之已久。
资本潮涌:Groq崛起的风口与动力
在科技巨头竞相投入AI硬件基础设施的时代背景下,硅谷AI芯片新创公司Groq在最新一轮融资中成功筹集7.5亿美元,将公司估值推升至69亿美元。
投资者开始将目光从单纯的AI模型开发,转向支撑这些模型运行的底层硬件基础设施。这笔资金的领投方为Disruptive,同时吸引了贝莱德(Blackrock)、路博迈集团(Neuberger Berman Group)和德国电信资本合伙公司(Deutsche Telekom Capital Partners)等顶级财务投资者的参与。此外值得注意的是,思科(Cisco)、三星催化基金(Samsung Catalyst Fund)等硬件和科技巨头也加入其中。
这些企业的参与从侧面印证了对Groq技术和商业模式的认可。行业消息显示,这些战略投资者可能正在积极寻求多元化的AI硬件供应链,以降低其对市场主导者NVIDIA的单一依赖,应对日渐高涨的价格、供不应求的局面以及地缘政治带来的供应链不确定性。这种市场压力,正是Groq得以迅速获得资本青睐的核心驱动因素。
这场融资事件的成功,其背后有着一条清晰的因果链:NVIDIA的GPU价格居高不下且一卡难求,市场对其高昂成本和不确定供应有所顾虑,并催生了市场对替代解决方案的迫切需求。
价值重估:百亿估值与沙特巨额订单
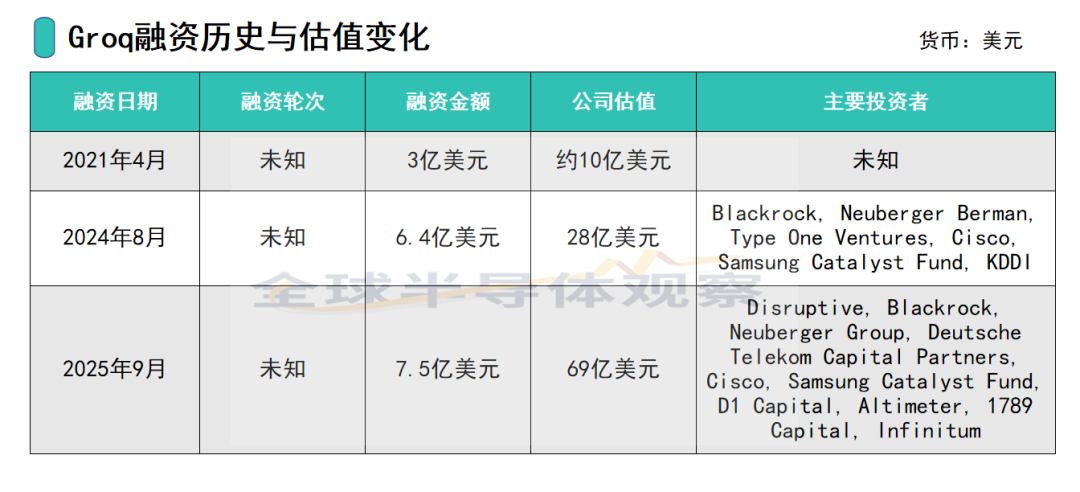
公开资料显示,Groq的估值在短时间内实现了爆炸性增长,从2024年8月融资时的28亿美元,在不到一年的时间里飙升近2.5倍,达到了惊人的69亿美元。这种估值飞跃的背后,是市场对AI推理这一特定市场环节长期价值的重新认识与重估。
过去,AI芯片市场的关注焦点主要集中在训练芯片上,但随着AI应用从实验室走向大规模生产化部署,对高性能、低延迟推理硬件的需求正爆发性增长。这一庞大的市场需求,使其成为一个全新的价值洼地。
此次估值飞跃的关键催化剂,与Groq在2025年与沙特阿拉伯的AI公司HUMAIN达成的15亿美元芯片交易息息相关。这笔巨额交易不仅为Groq带来了强劲的收入预期,更提供了强有力的市场背书。
它证明Groq的技术已经具备了满足国家级主权AI基础设施建设的能力,其技术价值远超其自身的基准测试数据。这笔交易预计将使Groq在2025年的营收从2024年的9,000万美元飙升至约5亿美元。
商业棋局:从“卖芯片”到“卖算力”
据悉,Groq的商业模式并非简单地销售芯片,而是提供基于其LPU的全栈平台GroqCloud™和API。这种模式使其更像是一家云服务供应商,出售“实时AI推理算力”,而不是一家传统的芯片制造商。该平台支持如Meta的Llama3.1和Google的Gemma等主流开源模型。这种服务模式降低了客户的前期硬件投资门槛,允许他们根据实际需求弹性地使用服务,这对于无法承担大规模资本支出的企业极具吸引力。
为了快速抢占市场,Groq采取了激进的价格战策略,将每百万Token的价格定为仅0.27美元。这种低价策略能够迅速吸引开发者和企业用户,实现市场渗透率的快速增长。然而,这也引发了市场对于其盈利能力和可持续性的疑问。
这种低价是否是基于其在总体拥有成本(TCO)上的优势?或者,这只是一种通过补贴来刺激市场热度的策略?多方消息显示,Groq的系统需要大量辅助硬件,例如一个系统可能配备144个CPU和144TB的RAM,这与只需要2个CPU的NVIDIA系统规模显著不同。这表明Groq虽然在单芯片推理延迟上表现出色,但在系统层级的成本结构上,仍需进一步的验证和优化。
技术交锋:LPU与GPU的底层对决
NVIDIA的GPU最初是为图形处理而设计,其架构哲学是平行处理,擅长将庞大的任务分解为数千个可以同时运行的简单计算。这种设计在AI模型训练、科学模拟和图像处理等需要大规模并行运算的任务中表现卓越。
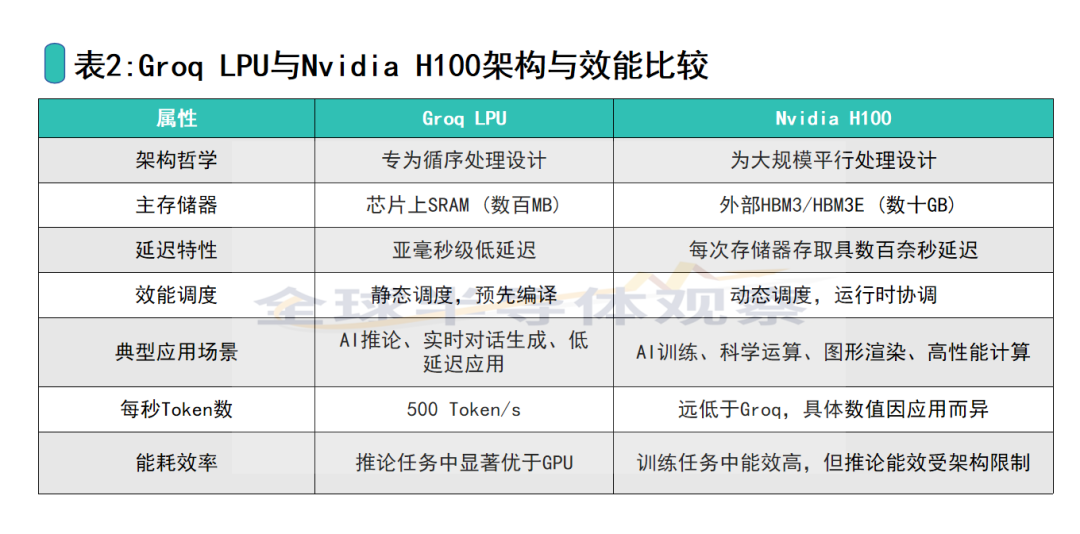
然而,当处理大型语言模型(LLMs)的推理任务时,这种架构却面临了效率上的挑战。LLM的推理是高度循序的,每个Token的生成都依赖于前一个Token,这使得GPU的平行处理优势难以完全发挥。
Groq的LPU正是为了解决这个根本性问题而诞生。其核心架构哲学是循序处理,专为处理语言中前后连贯的逻辑关系而设计。LPU消除了对外部高带宽存储器的依赖,将所有数据保留在芯片内部的高速SRAM中,从根本上消除了延迟瓶颈,实现了亚毫秒级的低延迟,这正是其“确定性性能”的技术基础。
此外,Groq还采用独特的软硬件协同设计方法,为LPU开发了专属的编译器,能够进行“静态调度”(Static Scheduling),与英伟达GPU的动态调度形成鲜明对比。这种设计不仅提高了处理效率,也保证了生成结果的一致性和处理的稳定性。
性能真相:数据下的挑战与局限
Groq的LPU在性能方面做出了声明。据报道,其LPU在处理LLM时的速度比通用型GPU快10倍,能耗仅为十分之一。官方数据显示,LPU每秒可以生成高达500个Token,而在Llama3测试中,其延迟为0.3秒,吞吐量为每秒282个Token。
然而,在解读这些性能数据时需要保持谨慎。Groq并未明确指出其比较的NVIDIA GPU具体型号。此外,LPU的片上SRAM仅有230MB。为了运行如Llama-2 70B这样的大型模型(即使经过量化,仍需要约70GB的存储器),需要将多达305张Groq加速卡网络化连接起来。
这引出了两个关键问题:单芯片存储器限制和系统级复杂性。虽然单芯片效能卓越,但为了适应大模型,Groq必须依赖复杂的多芯片互联,这可能在系统层级引入新的瓶颈和高昂的成本。
这场竞争的本质并非正面对决,而是针对不同细分市场的差异化竞争。Groq的技术优势聚焦在“推理”上,而英伟达的GPU(如H100)凭借其多核并行架构和高带宽,在“训练”端依然是无可匹敌的霸主。
多元格局:AI芯片生态的群雄逐鹿
在AI芯片市场,NVIDIA面临的挑战者远不止Groq一家。市场格局正在从单极走向多元化,涌现出多个重要玩家,各自拥有独特的技术和市场策略。

超威(AMD)的Instinct MI系列是NVIDIA最强大的硬件竞争对手之一。AMD也在积极追赶NVIDIA的软件生态系统,其ROCm软件栈正在努力为开发者提供与CUDA兼容的替代方案。Cerebras Systems以其独特的晶圆级引擎(WSE)著称,它将整个晶圆视为一个单一的超大芯片,旨在为超大规模模型的训练提供无与伦比的性能。
此外,主要的云服务提供商,如谷歌(Google)、亚马逊(AWS)和微软(Microsoft),都在自研芯片,以优化其云端服务并降低对外部供应商的依赖。这些自研芯片(如Google TPU、AWS Trainium、Microsoft Maia)主要用于其内部的云端工作负载,但也逐渐向外部客户开放。





发现“分享”和“赞”了吗,戳我看看吧










