当城市早高峰的车流数据实时涌入交通管控系统,当医院的心电图仪持续记录患者的心脏电活动,当股票交易所的行情面板每秒刷新数十次股价波动——这些伴随时间流逝不断产生的“时间序列数据”,早已成为现代社会运转的“数字脉搏”。从金融风控、医疗诊断到能源调度、交通管理,几乎所有关键领域的决策,都依赖于对这些时序数据的深度解读。
过去数十年间,时间序列分析领域涌现出了从经典统计模型(如ARIMA、ETS)到深度学习方法(如LSTM、Transformer)的大量技术,它们在“预测未来”“识别异常”等基础任务上取得了显著进展。例如,早期用LSTM预测未来24小时的城市用电量,用CNN检测心电图中的心律失常片段,这些传统技术早已落地于实际场景。
但随着应用需求的不断升级,传统方法的“能力边界”逐渐显现。在个性化医疗场景中,医生不仅需要模型判断“患者是否存在心律异常”,更需要知道“异常与哪些生理指标、哪个时间段的活动相关”;在自适应风险管理中,基金经理不仅需要股价预测结果,更需要理解“若政策调整,股价可能如何变化”的因果逻辑;在 autonomous 交通系统中,控制器不仅要检测拥堵,还需实时调整信号策略并验证效果——这些需求,都超出了传统时间序列分析仅输出结果、不解释过程的能力范畴。
与此同时,大语言模型(LLMs) 的爆发式发展,为时间序列分析带来了一场“范式革命”。不同于传统模型的“黑箱式拟合”,LLMs具备输出显式推理过程、生成因果假设、与外部工具协作的能力——这些特性,恰好击中了传统时序分析的痛点。正是在这一背景下,时间序列推理(Time Series Reasoning, TSR) 这一新兴领域应运而生,旨在将LLM的推理能力与时间序列的数据特性深度融合,构建能分析、能解释、能决策的新一代时序智能系统。
近日,来自加州大学洛杉矶分校(UCLA)、南加利福尼亚大学(USC)、阳明交通大学的跨校团队,联合发布了一篇题为《A Survey of Reasoning and Agentic Systems in Time Series with Large Language Models》的重磅综述。这篇综述不仅首次为“时间序列推理”给出了清晰的定义,更构建了一套覆盖“推理结构-任务目标-技术特征”的三维分类框架,系统梳理了领域内的研究成果、数据集与基准,并明确指出了未来的核心挑战与研究方向。对于希望进入这一领域的研究者,或是寻求技术落地的从业者而言,这篇综述无疑是一份“全景式路线图”。
论文链接:https://arxiv.org/pdf/2509.11575
开源仓库:https://github.com/blacksnail789521/Time-Series-Reasoning-Survey


为什么需要“时间序列推理”?传统方法的局限与LLMs的突破
在深入综述内容之前,我们首先需要理解一个核心问题:为什么要提出“时间序列推理”这一概念?
传统时间序列分析的核心是“预测”与“分类”——比如用ARIMA、LSTM预测未来股价,用CNN检测心电图中的异常片段。这些方法虽在特定任务上表现出色,但存在三大关键局限:
缺乏解释性:深度学习模型常被称为“黑箱”,即便能预测出“某患者存在心律异常”,也无法说明“异常与哪些生理指标、时间段相关”; 难以处理因果:当需要判断“若调整交通信号灯时长,能否缓解拥堵”时,传统模型只能基于相关性分析,无法推导干预措施的真实因果效应; 静态响应不足:面对动态变化的场景(如实时调整电网负荷、动态优化交易策略),传统模型无法像人类一样“逐步思考、迭代修正”。
而LLMs的出现,恰好为解决这些问题提供了新工具。综述指出,LLMs不仅能拟合数据模式,还具备三大核心能力:
分步推理轨迹:能像人类一样输出“第一步分析趋势、第二步验证异常、第三步推导结论”的显式推理过程; 因果假设生成:可基于时序数据提出“某事件可能导致另一事件”的因果假设,并结合领域知识验证; 智能体交互能力:能与外部工具(如数据库、模拟器)协作,甚至形成多智能体系统,实现“感知-规划-行动-反思”的闭环。
正是基于这些能力,“时间序列推理”被定义为:利用LLMs对时序索引数据执行显式结构化推理的方法,可融合多模态上下文与智能体系统,不仅强化传统分析任务,还能实现解释、干预与动态生成。这一定义,也成为了整篇综述的核心出发点。
三维分类框架:从“如何推理”到“为何推理”
综述最核心的贡献,是构建了一个“推理拓扑-核心目标-属性标签”的三维分类框架,将零散的研究统一到系统性的框架下。这一框架不仅能帮助研究者定位现有工作,更能清晰识别领域空白。

第一维度:推理拓扑——定义“如何推理”的结构
推理拓扑描述了LLMs执行推理的“流程结构”,综述将其分为三类,构成了从简单到复杂的能力光谱:

1. 直接推理(Direct Reasoning):单步映射,高效但“黑箱”
直接推理是时间序列推理中最为基础的拓扑结构,它的特点是模型直接将时间序列输入映射到输出,中间不产生或暴露任何推理过程。这种推理方式就像是一个“黑箱”,直接给出结果,却不展示得出结果的步骤。

在传统时间序列分析任务里,直接推理的应用十分广泛。以预测任务为例,LLMTIME把预测问题转化为对文本化数字的下一个token生成任务,通过采样多个延续结果来总结点预测和概率预测;CiK则引入了上下文辅助基准,通过直接提示的方式让模型输出结构化的概率预测。在分类任务中,HiTime通过对齐时间序列和文本语义,让经过调整的大语言模型在单次前向传递中就能生成类标签。而在异常检测方面,Zhou和Yu通过提示大语言模型和多模态大语言模型,使其从文本化序列或绘制的图像中一步返回异常区间。
虽然直接推理在简单任务上能快速给出结果,效率较高,但它的局限性也很明显。由于缺乏中间推理步骤,其可解释性差,面对复杂任务时,鲁棒性不足。比如在处理一些需要深入分析和复杂逻辑的问题时,直接推理可能无法准确把握数据中的复杂关系,导致结果的准确性和可靠性下降 。
综述中提到的典型案例包括:
LLMTIME:将时序数据转化为文本化的数字序列,用LLM以“下一个token预测”的方式实现时序预测; CMLLM:将风力发电机的SCADA信号转化为文本,结合领域知识前缀,让冻结的LLM直接生成预测token,再映射回数值。
2. 线性链推理(Linear Chain Reasoning):分步执行,显式中间态
线性链推理,在直接推理的基础上有了进一步发展。它通过引入一个有序的推理步骤序列,每个步骤都依赖前一个步骤的输出,形成了一条逻辑连贯的推理链。这种结构使得中间状态能够被明确表示、检查和修改,大大提升了推理过程的可解释性和模块性。

在传统时间序列分析中,线性链推理的应用案例众多。像TimeReasoner将时间序列预测视为深思熟虑的推理过程,使用结构化提示让大语言模型在生成预测之前先分析模式;RAF引入检索增强框架,通过构建特定数据集的数据库,检索相关的时间序列片段来辅助预测。在分类任务中,TableTime将时间序列序列化为表格提示,用于无训练的分类;VL-Time则把时间序列转化为图像,利用视觉语言模型进行分类。
在解释与理解、因果推断与决策以及时间序列生成等任务中,线性链推理也发挥着重要作用。例如在解释与理解方面,Tan等人通过引导对变化的逐步分析来推断自然语言事件序列,从而解释观察到的时间片段;在因果推断与决策的自主政策学习中,FinAgent通过市场情报、检索等一系列有序步骤来做出交易决策。
不过,线性链推理也并非完美无缺。它的执行路径单一,缺乏分支和反馈机制,在面对需要同时探索多种可能性的复杂情况时,灵活性不足,可能无法全面考虑各种因素,影响最终的决策质量 。
典型案例包括:
TimeRAG:将时序数据切分为代表性片段,检索相似历史片段后,转化为自然语言提示输入LLM,实现预测; VLM4TS:两阶段异常检测——先用视觉编码器筛选候选异常,再用视觉语言模型(VLM)验证并修正结果,输出最终异常区间与解释。
3. 分支结构推理(Branch-Structured Reasoning):多路径探索,灵活且自修正
分支结构推理是三种推理拓扑中最为复杂的一种。它允许推理过程在同一执行过程中分叉为多个路径,模型可以并行或顺序地探索不同的假设、候选预测、解释或计划。这种结构还支持反馈循环和交叉分支聚合,使得模型能够根据后续的信息对之前的输出进行修正和优化,大大增强了模型的灵活性和自校正能力。

在传统时间序列分析的预测任务中,Zhang等人将新闻驱动的预测视为一个竞争的多智能体过程,通过并行假设的迭代修剪和自我反思来改进预测;NewsForecast则通过对错误的反思和更新选择逻辑来调整预测。在分类任务里,ReasonTSC进行结构化的多轮推理,通过回溯探索替代方案来做出更准确的决策;ColaCare通过引发不同的智能体评论并融合结果,提升临床报告的预测准确性。
在解释与理解、因果推断与决策以及时间序列生成任务中,分支结构推理同样表现出色。例如在解释性诊断方面,TESSA通过协调多个智能体进行跨域解释性注释;在因果推断与决策的自主政策学习中,FinArena协调多个智能体进行金融决策;在时间序列生成任务中,BRIDGE通过多智能体团队的协作,生成可控的合成序列。
然而,分支结构推理的复杂性也带来了一些挑战。比如,分支的增长可能导致计算成本迅速增加,如何控制分支的数量和范围成为关键问题;同时,反馈循环可能引发不稳定性,模型需要精确地定义停止条件以确保推理过程的收敛性和可重复性 。
典型案例包括:
AD-AGENT:多智能体异常检测框架——生成智能体提出检测规则,审查智能体修正规则,记忆智能体存储历史经验,形成“生成-审查-修正”的分支循环; BRIDGE:时序生成模型——多智能体团队迭代提出、批判、修正文本描述,再基于描述生成符合约束的时序数据,实现“语义可控的生成”。
第二维度:核心目标——定义“为何推理”的意图
如果说推理拓扑是“方法”,核心目标就是“目的”。综述将时间序列推理的核心目标分为四类,覆盖了从基础分析到高级决策的全场景:
1. 传统时间序列分析:夯实基础任务
这是最基础的目标,涵盖传统时序任务,但用LLM增强性能或灵活性:
预测:如用LLM结合文本上下文(如新闻)预测股价(Yu et al., 2023); 分类:如将心电图(ECG)信号与文本描述融合,用LLM分类心律类型(HiTime); 异常检测:如用VLM分析时序图表,检测电力系统中的异常(VLM4TS); 分割:如用LLM将长时序数据切分为有意义的子区间(MedTsLLM用于医疗信号分割)。
2. 解释与理解:让LLM“说清楚”结果
这一目标聚焦“可解释性”,要求LLM不仅输出结果,还能生成人类可理解的解释:
时序问答(Temporal QA):如“2023年Q3的销售额环比增长了多少?”,LLM需从时序数据中提取信息并回答(Time-MQA); 诊断解释:如生成ECG诊断报告时,说明“异常波峰出现在第10秒,可能与心肌缺血相关”(GEM); 结构发现:如从工业时序数据中提取因果关系(如“温度升高导致压力上升”)(RealTCD)。
3. 因果推断与决策:从“描述”到“干预”
这是更高级的目标,要求LLM不仅分析数据,还能推导“如果做X,会发生Y”的因果效应,并支持决策:
自主策略学习:如LLM结合市场数据,自主学习“何时买入/卖出”的交易策略(FinAgent); 辅助决策支持:如为医生提供“若调整用药剂量,患者心率可能如何变化”的建议(SocioDojo); 控制优化:如LLM生成交通信号灯控制策略,优化路口通行效率(Open-TI)。
4. 时间序列生成:创造符合约束的“假数据”
这一目标聚焦“数据合成”,要求LLM生成符合特定约束的时序数据(如“生成符合‘早高峰拥堵、晚高峰平缓’的交通流量数据”):
条件合成:如基于文本描述(“未来5天的温度先降后升”)生成时序数据(GenG); 场景模拟:如生成极端天气下的电网负荷数据,用于测试系统鲁棒性(BRIDGE)。
第三维度:属性标签——细化方法的“辅助特征”
属性标签是对前两个维度的补充,描述了方法的“辅助特征”,共分为四类,帮助研究者更精细地分类工作:
控制流操作:如是否分解任务(如将预测拆分为“趋势预测+季节项预测”)、是否验证结果(如用另一个模型检查预测合理性);

执行主体:如是否使用外部工具(如调用数据库检索历史数据)、使用多少智能体(单智能体/多智能体);

信息来源:如是否融合多模态数据(时序+文本+图像)、是否访问外部知识(如调用知识库查询领域规则);
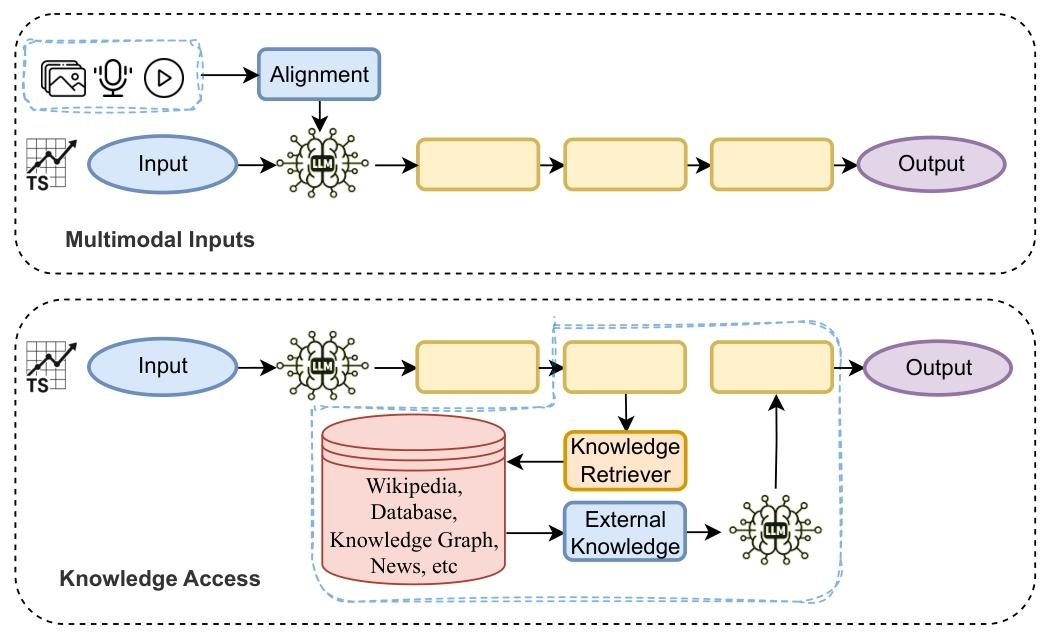
LLM对齐方式:如用提示工程(Prompting)、监督微调(SFT)、强化学习(RLHF)等方式让LLM适配时序任务。
资源与工具:从数据集到基准,支撑研究落地
要推动领域发展,完善的资源与工具至关重要。综述专门梳理了三类核心资源,为研究者提供“开箱即用”的支撑:

1. 推理优先(Reasoning-First)基准:专门测试推理能力
这类基准的设计目标就是“考核LLM的推理能力”,而非仅测试预测 accuracy:
MTBench:多模态时序问答基准,要求LLM结合文本报告与时序数据回答问题(如“某患者的心率异常与用药时间是否相关”); TimeSeriesGym:时序智能体基准,构建了可复现的环境,测试LLM在“规划-工具使用-迭代修正”中的表现; CiK:上下文依赖预测基准,测试LLM能否利用文本上下文(如“某地区发生自然灾害”)提升时序预测准确性。
2. 推理就绪(Reasoning-Ready)基准:自带“推理所需信息”
这类基准虽非专为推理设计,但包含丰富的辅助信息(如文本描述、领域知识),可直接用于推理研究:
GPT4MTS:多模态时序基准,包含时序数据与对应的文本描述(如“这是某城市2023年的降雨量数据”); RATs40K:异常检测基准,不仅提供时序数据,还包含“异常原因”的文本标注,支持解释性研究; STOCK23:金融时序基准,包含股价数据与对应的新闻、财报文本,支持“文本-时序融合推理”。
3. 通用时序(General-Purpose)基准:传统任务的“通用测试床”
这类基准是传统时序任务的经典基准,可用于对比LLM与传统方法的性能:
FinBen:金融时序基准,包含股票、期货等数据,支持预测、风险管理等任务; UEA/UCR:时序分类基准,包含多领域数据(如传感器、医疗),常用于测试分类模型; TSFM-Bench:时序基础模型基准,包含多模态、多任务数据,支持大规模模型评估。
开放问题与未来方向:从“窄精度”到“大规模可靠性”
尽管时间序列推理已取得不少进展,但综述指出,领域仍面临六大核心挑战,这些挑战也定义了未来的研究方向:
1. 标准化评估:如何衡量“推理质量”?
当前评估多关注“预测 accuracy”,但推理质量需要更全面的指标:
需结合“证据忠实性”(解释是否与数据一致)、“决策效用”(推理结果能否提升决策效果); 需构建“压力测试”基准(如数据分布偏移、长时域场景),而非仅测试简单场景。
2. 多模态融合与对齐:如何让LLM“看懂”时序+文本+图像?
多模态是时序推理的重要方向,但当前存在三大问题:
时间对齐:文本中的“昨天”、图像中的“某个时刻”与时序数据的时间戳如何精准匹配; 模态失衡:文本常包含更丰富的标签,导致LLM“重文本、轻时序”(如忽略时序中的细微变化); 风格鲁棒性:将时序数据转化为图表时,不同绘图风格(如折线图、柱状图)可能导致LLM性能波动。
3. 长上下文与效率:如何处理“超长时序”?
现实中的时序数据常长达数月甚至数年,但LLM的上下文窗口有限:
需开发“时序压缩”技术(如保留关键事件、压缩冗余数据),在不丢失信息的前提下缩短输入长度; 需优化推理效率(如流式推理、增量更新),避免长时序导致的高延迟。
4. 智能体与工具使用:如何让LLM“安全地行动”?
智能体系统需解决“鲁棒性”与“安全性”问题:
行动选择:如何在“不确定环境”下选择最优行动(如“若预测不准,是否应暂停交易”); 工具适配:如何应对工具API变更、数据格式变化等“现实问题”; 风险控制:如何设置“安全阈值”(如当推理置信度低于80%时,触发人工审核)。
5. 因果推断落地:如何从“相关性”到“因果性”?
因果推断是时序推理的核心目标,但落地困难:
需解决“时间混淆变量”(如“看似A导致B,实则是第三个变量C同时影响A和B”); 需构建“因果基准”(如已知数据生成过程中的因果关系,用于验证LLM的因果推断能力)。
6. 成本与实用性:如何平衡“性能”与“成本”?
LLM推理的计算成本较高,需在性能与成本间权衡:
需开发“轻量化推理”技术(如用小模型完成基础步骤,大模型仅处理复杂推理); 需将“成本”纳入设计指标(如“用1/10的计算量,实现90%的性能”)。
总结:时序推理的下一个十年
这篇综述不仅是对现有研究的梳理,更定义了“时间序列推理”这一新兴领域的核心范式。从“直接推理”到“分支结构推理”,从“预测”到“因果决策”,LLM正在将时间序列分析从“静态黑箱”转变为“动态、可解释、能行动”的智能系统。
未来的时间序列推理,将不再追求“窄范围的高精度”,而是向“大规模的可靠性”迈进——系统不仅能在实验室环境中表现出色,更能在金融、医疗、能源等关键领域中,基于可追溯的证据,生成可信的结果,真正实现“理解、解释、并作用于动态世界”。