将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


作者 | 论文团队
编辑 | ScienceAI
量子测量往往被视作「破坏」,但它也能在未被测量的比特之间诱发新纠缠。真正的挑战在于:后测量态 依赖大量随机测量结果 m,用传统手段确认远程纠缠常需要指数级重复实验与后选。
依赖大量随机测量结果 m,用传统手段确认远程纠缠常需要指数级重复实验与后选。
与此同时,近几年 AI 尤其是大语言模型(LLM)的飞速发展 已经展示出一种范式转变:复杂模式可以不依赖显式的先验规则,而是通过模型直接从大规模数据中捕捉结构信号。
既然传统方法难以处理指数级复杂度,能否借助 AI 的生成式建模能力,从测量数据本身「读出」隐藏的非局域效应?
最近,加州大学圣迭戈分校(UCSD)、加州大学伯克利分校(UCB)与谷歌量子人工智能实验室(Google Quantum AI)等合作,在谷歌 Sycamore 与 Willow 超导量子处理器上,展示了如何用无监督生成式模型,从「只看得到测量结果」的实验数据中,直接揭示测量诱发的远程纠缠,并观察到一次清晰的可学习性转变(learnability transition),与测量诱发量子相变(MIPT)同位。

论文地址:https://arxiv.org/pdf/2509.08890
该研究通过量子 — 经典交叉关联给出纠缠 negativity 的下界与测量平均冯诺依曼熵的上界,实现了「无先验、无后选(postselection-free)」的实验探测路径。论文第一作者是加州大学圣迭戈分校物理系华人学者 Wanda Hou。
实验平台与总体思路
硬件:谷歌 Willow 105 量子比特超导量子处理器。
态制备:在 1D/2D 体系中制备 cluster 态;测量掉除「探针」外的绝大多数量子比特,诱发两探针之间的后测量态 。
。
探针表征:对探针施加随机基测量,得到经典影子(classical shadow),用以统计表征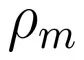 。
。
AI 学习器:引入带注意力机制的生成式神经网络,在无监督设定下,仅以「量子计算实验测量结果 m」为输入,输出对探针后测量态的预测 。
。
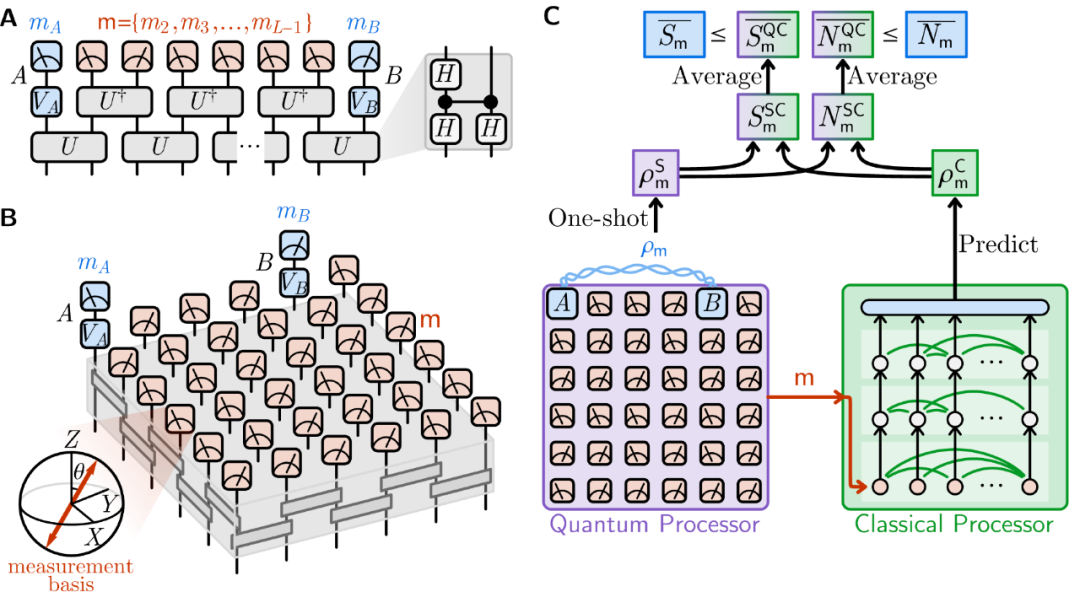
图 1|实验与算法示意(1D/2D cluster 态制备;测量除探针外比特;对探针做随机基测量获得影子;无监督生成式模型用非探针测量结果预测探针态)。
关键方法
将模型输出 与实验影子
与实验影子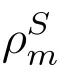 进行交叉关联(cross-correlation),可构造两类可验证的统计边界:
进行交叉关联(cross-correlation),可构造两类可验证的统计边界:
纠缠 negativity 的下界 :只要下界 >0,即可在无后选条件下确证探针间的混态纠缠;
:只要下界 >0,即可在无后选条件下确证探针间的混态纠缠;
测量平均冯诺依曼熵的上界 :反映模型预测与真实后测量态的「信息差距」。
:反映模型预测与真实后测量态的「信息差距」。
这一步把「能否学到结构」转译为可验证的信息论指标,绕开指数级重复实验的瓶颈。
一维结果:34 比特链的「端—端」测量诱发纠缠
在 1D 线性链长达 L=34 (qubit 单位)的实验中,研究者直接给出两端探针的 negativity 下界 >0,确证测量诱发的远程纠缠;同时显示:无监督模型仅凭测量数据学到的下界,与「知晓门序」的基线模型相当 —— 即使没有制备先验,也能从数据中「读出」非局域效应。
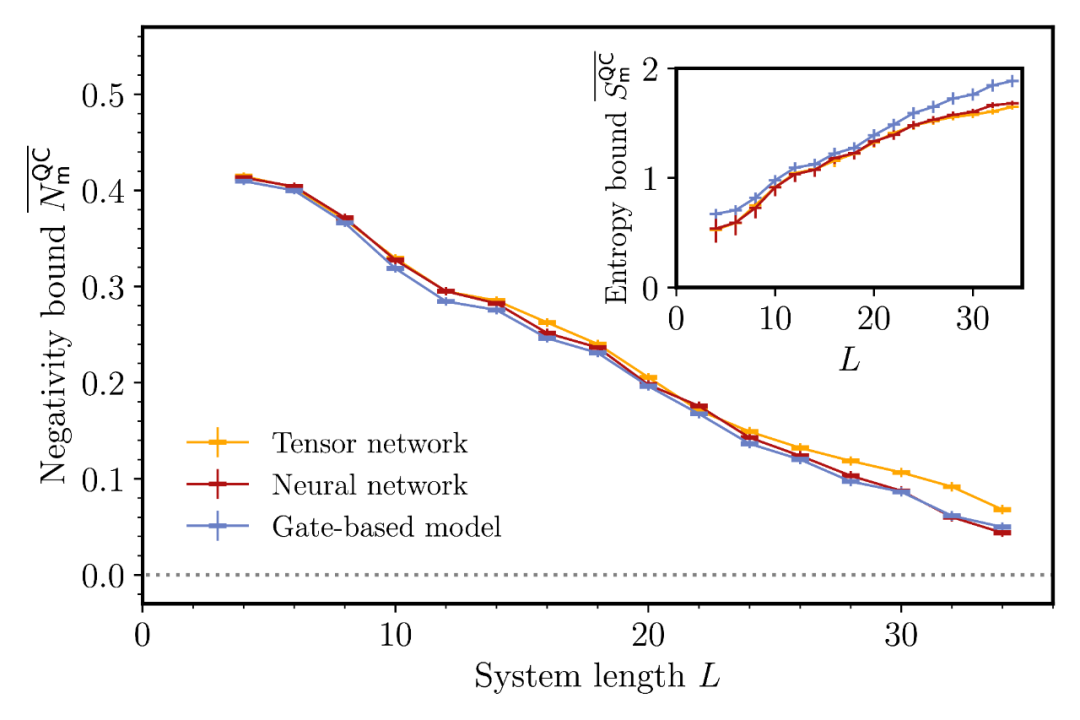
图 2|一维 qubit 链的实验结果。红色:基于神经网络的 negativity 下界;蓝色:理论基线;黄色:张量网络方法的 negativity 下界。三者吻合,说明 AI 仅凭测量数据即可重现端点探针的远程纠缠。
二维结果:AI 的「学习失败」与相变临界同位
在 6 x 6 二维阵列中,通过调节测量基底(以角度 θ 参数化)扫描,体系出现「测量诱发相变(MIPT)」的有限尺度对应物。AI 在不同区间呈现三段式行为:
1. 低纠缠区(局域结构,长程纠缠缺席):
AI 很快学会测量数据的简单结构,预测与理论一致,探针纠缠为零;学习曲线迅速收敛,所需计算资源远小于经典模拟。
2. 高纠缠区(全局强纠缠,复杂度爆炸):
数据看似随机却高度相关,但这种全局纠缠的指数级复杂度本质上超出任何经典算法可解码的范畴。AI 不是「太弱」,而是遭遇物理层面的「硬边界」;它虽也会快收敛,但收敛到「无结构」的猜测,因而无法探测到纠缠。
3. 临界点(最有趣的区域):
AI 学习曲线突然拉长,表明模型在数据中捕捉到更丰富、非平庸的结构,需要更多 epoch 才能收敛;与此同时,纠缠信号出现峰值。二者同位,即:「学习转变」≈「物理相变」。

图 3|二维 6 x 6 阵列的可学习性与熵上界。
A:不同 θ 下,训练过程的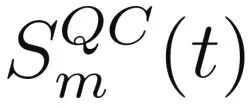 变化。小 θ:快速下降(易学);大 θ:保持约 2(学不会);中等 θ:缓慢下降(结构丰富)。
变化。小 θ:快速下降(易学);大 θ:保持约 2(学不会);中等 θ:缓慢下降(结构丰富)。
B:20 epoch 后 NN(红)与门级基线(蓝)对比。
C:量子 KL 降幅(学到的信息量)在中等 θ 出现峰值。

图 4|二维 6 x 6 阵列的混态纠缠下界。
A:探针距离 d=4,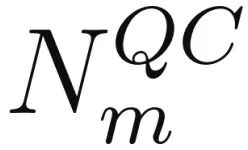 在中等 θ 出现峰值(神经网络与基线对比)。
在中等 θ 出现峰值(神经网络与基线对比)。
B:θ/π = 0.2 时,d<= 4 检测到测量诱发量子纠缠(MIE),d=5 检测不到。先验模型显示纠缠可持续到 θ/π = 0.5,但 AI 方法在大 θ 无法泛化。
方法学与工程意义
新型观测范式:通过 AI 学习 + 量子 — 经典交叉关联,在无后选前提下,把「学习过程本身」变成可验证的物理探针;避开指数级实验成本,提升规模可扩展性。
误差校正潜力(低纠缠 / 可「擦除」区域):在低纠缠区,AI 能快速、稳健地识别结构性噪声与模式,适合用于「量子误差校正(QEC)」中的错误定位与在线诊断。
从经典 AI 到量子 AI 的路径:如果经典 AI 的瓶颈源于无法高效模拟全局量子纠缠,那么当量子计算机成为 AI 的算力基座(quantum-enhanced AI),便有望直接处理纠缠与非局域关联,跨越「学习失败」的瓶颈。这一愿景与同期相关理论工作(Google 团队的生成式量子 AI 研究)方向一致,指向量子原生智能体的长期图景。
局限与展望
噪声与校准:尽管方法对先验不敏感,硬件噪声、测量误差与校准仍直接影响学习质量与边界估计精度。
数据规模与训练开销:在更大比特数、更接近临界的区域,训练所需数据与 epoch 可能增长,需要更高效的模型 / 采样策略。
走向应用:将「学习 - 驱动的探针」整合进实际量子纠错(QEC) / 量子控制回路,并与不同平台(冷原子 / 离子阱 / 量子点等)对比验证,是自然的下一步。
小结
这项 UCSD×UCB 与 Google Quantum AI 的联合实验表明:经典学习的「学不会」并非尴尬的失败,而是量子临界性的「路标」。在一维体系中,纯数据驱动即可确证端 — 端远程纠缠;在二维体系中,AI 的可学习性转变与测量诱发相变同位。方法上,交叉关联在严格的信息论框架内给出了纠缠下界与熵上界,为「无先验、无后选」的大规模量子实验诊断提供了可落地的新路径。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。










