机器之心编辑部
2025年9月17日,中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)在香港正式开源发布其最新科研成果——EchoCare“聆音”超声基座大模型(简称“聆音”)。该模型基于超过450万张、涵盖50多个人体器官的大规模超声影像数据集训练而成,在器官识别、器官分割、病灶分类等10余项典型超声医学任务测试中表现卓越,性能全面登顶。同时,“聆音”已在山东大学齐鲁医院、中南大学湘雅医院、香港中文大学医学院的多个超声检查领域完成3000多例临床回溯性验证,与当前SOTA(最优)模型相比,性能平均提高3%~5%。
“聆音”首创的结构化对比自监督学习框架,高效解决了传统超声AI模型普遍存在的技术难题,包括对大规模标注数据的依赖、难以处理长尾分布问题、模型泛化能力不足以及缺乏足够领域知识。同时,该框架为AI大模型在其他医疗领域的应用探索提供了创新路径,是人工智能与临床医学深度融合的又一里程碑式突破。
超声AI的发展困局:数据枷锁与泛化死结
超声诊断凭借动态成像与无创安全的双重优势,已成为医学影像领域的“核心工具”。目前,我国超声年检查量已超20亿人次,占医学影像检查总量的70%以上。从产科胎心的实时监测,到急诊创伤的快速评估,再到慢性病的长期随访,超声技术贯穿临床诊疗的全流程。然而,超声AI在快速发展的同时,仍面临多重挑战。
1.1复杂且多样化的临床需求
超声图像的“多变性”使大模型难以应对。在设备层面,不同厂商的信号算法差异会导致相同解剖结构呈现出截然不同的纹理特征;在操作层面,医师的扫查角度、探头压力等变量会导致同一患者的图像发生显著变化。这些因素直接导致传统超声AI面临“碎片化开发”的困局,严重制约了技术的落地。
1.2现有解决方案的致命短板
虽然医学影像领域的基座模型如MedSAM、BioMedCLIP、USFM等已崭露头角,但在超声领域表现仍显不足。数据显示,现有超声AI训练数据量普遍低于100万张,且多集中于单一部位。更为关键的是,这些模型大多直接套用自然图像的算法架构,未能针对超声特有的斑点噪声、声影伪影等特性,以及“区域-器官”的临床推理逻辑进行定制化优化。

1.3理想超声模型的三大标准
临床对超声AI的核心诉求包括:数据高效性,需摆脱对专家标注的高度依赖;场景适应性,能够快速适配多部位、多任务应用;临床实用性,输出结果需符合诊断习惯,支撑全流程辅助。“聆音”正是基于这三大标准,通过“数据奠基-架构创新-场景验证”的路径构建而成。
“聆音”的技术突破:数据、架构与范式革新
2.1全球规模最大的超声图像数据集
“聆音”的突破始于数据根基。团队遵循“广度覆盖+深度质控”的原则,从Zenodo、Kaggle等多个渠道整合了138个高质量数据集,涵盖五大洲20多个国家,最终构建了一个包含超过450万张图像的EchoAtlas,其数据规模位居全球首位。
这份数据集展现出极强的多样性:在人种上,涵盖黄种人、白种人、黑种人、棕种人;在解剖结构上,覆盖人体9大区域的56个解剖器官;在模态上,涉及B超、M超、超声造影、弹性成像等5大主流类型;在设备上,涵盖飞利浦、西门子、日立等130种不同厂商的产品。同时,为确保数据质量,团队建立了四阶段质控体系,为“聆音”的性能突破奠定了坚实的数据基础。

2.2层级化双分支架构:贴合临床诊断逻辑
针对超声特性,“聆音”创新设计了层级化双分支架构,有效突破了传统模型架构的局限性:
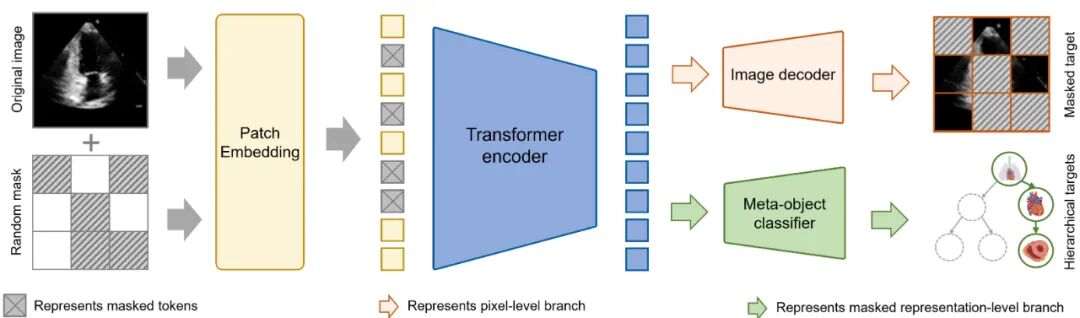
图像编码器以SwinTransformer为骨干,同时通过优化注意力机制增强边缘特征的鲁棒性,从而有效应对超声斑点噪声的干扰。
双分支解码器实现双重特征学习:图像重建分支学习组织纹理等像素级特征;解剖分类分支引入三级分类头,模拟医师“胸部→心脏→心尖四腔心”的诊断思维,逐步提取并分类解剖结构特征。
层级化损失函数构建多任务优化目标:引入图像重建损失和层级化损失,在提升图像重建质量同时学习超声图像之间的语义关联,有效解决“同一器官不同视图”下的歧义问题。
这种架构与临床诊断逻辑高度契合,使模型不仅能够“看懂图像”,还能够“理解结构”。
2.3自监督训练范式:无标注数据的价值最大化
“聆音”采用两阶段训练策略,充分挖掘无标注数据的价值:
全局预训练阶段首创结构化对比自监督学习框架,基于医学先验的层次化树形标签结构,实现多标签语义关系的结构化学习与隐式编码,并结合图像掩码重建与自适应困难图块挖掘技术,引导模型聚焦于临床诊断关键细节。
下游任务微调阶段:分割任务将预训练的编码器结合解码器;诊断任务使用分类的蔬菜头;量化任务在预训练的骨干网络添加回归头进行预测络。通用预训练编码器使微调仅需原训练量 40%-60% 即可快速适配新任务。
临床验证:10项任务突破现有技术水平
团队在 7 大类 10 项核心超声任务中验证 “聆音” 性能,所有数据均来自未参与预训练的独立中心,确保结果客观。
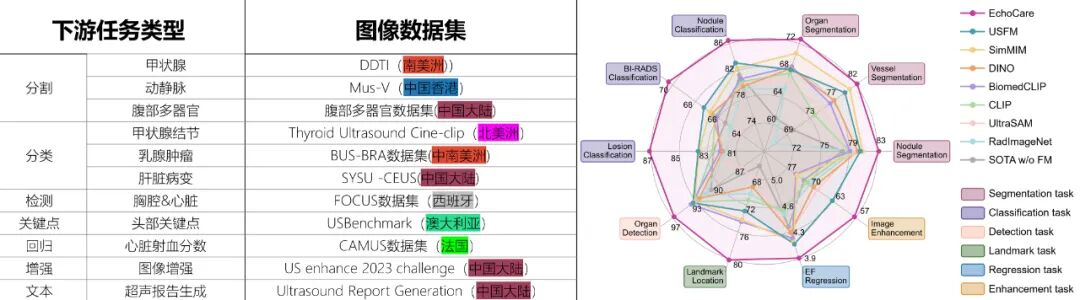
3.1解剖分割:精准定位组织区域
分割作为诊断基础,“聆音” 在三项任务中表现突出:甲状腺结节分割,血管分割和腹部多器官分割。其中,对于甲状腺结节分割,“聆音” 的 DSC 达 83.17%,比 USFM 高约 3%。血管分割任务,“聆音” 实现 mDSC 指标 82.24%,比 USFM 高 2%,显著高于传统模型 SwinUNETR 的 70.20%。腹部多器官分割数据集,“聆音” 同样实现了最高的多器官识别分割性能。
3.2疾病诊断:提升准确性与一致性
在高价值诊断任务中,“聆音” 展现出临床价值:甲状腺结节良恶性鉴别(192 个病理证实结节)的 AUC 达 86.48%,F1 分数 87.45%,假阳性率仅 8.3%。引入时序特征使 AUC 提升 4.2%,<1cm 恶性结节检出率达 82.1%,比现有模型高 11.3%,可减少 30% 不必要活检。乳腺 BI-RADS 分级多分类的准确率 70.36%,比 USFM 高 3.09%。肝脏病变诊断准确率 87.12%,肝癌敏感性 90.3%、特异性 88.7%,辅助医师理解依据。
3.3定量分析:精准计算关键指标
量化指标是疾病评估金标准,“聆音” 在两项核心任务中实现高精度:胎儿心胸比测量的检测定位准确率 94.42%,比 USFM 高 2.78%,误差 < 5% 的病例占 89.2%,测量时间从 5 分钟缩至 2 秒,助力先天性心脏病筛查。而在 CAMUS 数据集上,左心室射血分数计算 MAE 比 USFM 低 19%,有望用于指导心衰治疗。
3.4特殊场景:破解基层与未知部位难题
低质量图像增强任务中,“聆音” 的 NIQE6.35、BRISQUE17.62,均优于 USFM 与 EnlightenGAN。
3.5临床适配:高效且实用
标注效率上,“聆音” 用 60% 标注数据即可达传统模型 100% 数据性能,血管分割仅需 40% 数据实现 80% 性能上限,收敛速度快 30%-40%。
临床适配性上,单张图像分析 < 0.5 秒满足实时需求;输出分割掩码、热力图等可视化结果;报告生成的 BLEU-4 达 78.47,可辅助医师完成初稿。
讨论与展望:超声AI的未来方向
4.1技术创新的核心价值
“聆音”通过三大创新破解行业难题:数据层面构建大规模超声预训练数据集,打破数据壁垒;架构层面设计贴合临床应用的双分支结构;训练层面首创结构化对比自监督学习框架,实现像素与语义特征协同学习。这些创新带来性能突破、临床适配与生态构建的三重价值。
4.2现存局限与改进路径
当前模型仍有提升空间:多模态信息融合不足,未来需构建图文等多模态超声数据集,赋予模型多模态分析能力;动态序列处理能力薄弱,未来将扩展至超声视频等时序数据的分析与处理;临床落地需深化,计划开展10家医院的多中心试验,建立性能监测体系。
4.3超声AI的三大发展趋势
从"专用模型"到"通用基础模型",未来超声AI将成为覆盖全流程的"AI助手";从"数据驱动"到"数据-知识双驱动",融合临床规则以提升泛化能力与可解释性;从"被动辅助"到"主动决策支持",实现实时提示病变、推荐方案、预测风险的能力。
结论
“聆音”作为首个面向超声临床场景的超声基座大模型,通过超过450余万张大规模多器官、多中心、多地区超声数据预训练,以及层级化双分支架构的创新模型设计,在超声医学图像分割、诊断、量化分析等10项核心临床任务上实现了性能突破。
其技术价值不仅体现在超越现有模型的准确率与泛化能力,更在于构建了"大规模数据-定制化架构-多场景验证"的超声AI研发范式,为行业发展提供了新思路。
该研究的公开数据集(EchoAtlas)和模型代码,将打破超声AI领域的数据壁垒和技术垄断,推动更多科研机构和企业参与到超声AI的创新研究中。随着多中心临床试验的开展和技术的持续优化,“聆音”有望在基层医疗、远程诊断、慢性病管理等场景中发挥重要作用,为提升全球超声诊断水平、实现医疗资源普惠做出贡献。
未来,随着多模态融合、知识驱动学习等技术的发展,超声AI将从"图像分析工具"进化为"全流程临床决策伙伴",为精准医疗和个性化医疗的实现提供强大支撑,最终实现"以患者为中心"的医疗AI发展目标。
EchoCare“聆音”超声基座大模型可通过以下渠道获取:
https://echocare.cares-copilot.com/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










