将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


编辑 | 心悦
这种转变很大程度上得益于交叉型科研人才不断的共同探索,特别是青年人敢于颠覆传统范式、直面 AI 技术给科学研究带来的挑战与机遇。越来越多的创新突破乃至应用由带有研发底色的年轻人创造。
因此,要了解科学智能的前瞻趋势和新颖见解,最直接的途径就是聆听一线青年研究员的声音。
9 月 26 日,一场聚焦科学智能前沿进展的青年分享会 ——SAIS Talk「上智院星辰之夜」,在位于上海西岸的上海科学智能研究院(下称「上智院」)举办。五位青年研究员着眼于物质科学、生命科学、地球科学、AI 共性技术等方向,分享了他们的核心工作和创新思辨。






左右滑动
成立于 2023 年 9 月的上智院是一个聚焦科学智能基础研究、前沿技术与场景落地的战略性新型研发机构,致力于「用人工智能驱动科学研究范式变革、赋能千行百业」。在此次分享会上,通过五位青年研究员的讲述,我们看到了上智院面向科学智能核心方向为多项科研难题给出的解决方案,兼具前沿深度和实践价值。
我们来一起回顾下这场前沿分享。
表征学习
数据的表征决定了机器理解世界的深度。上智院研究员、复旦大学人工智能创新与产业研究院助理教授姜若曦长期从事表征学习研究工作。她认为,生成模型与表征学习就像是一枚硬币的两面,相辅相成。

在分享会上,姜若曦围绕静态图像生成和动态系统模拟两个关键任务,分享了两项前沿工作。
第一项工作是关于静态图像生成,研究论文《Nested Diffusion Models Using Hierarchical Latent Priors》还被 CVPR 2025 接收。

论文地址:https://arxiv.org/pdf/2412.05984
图像包含多尺度的语义结构 —— 从局部纹理、边缘到部件、物体乃至整体连贯场景。生成系统要产生逼真图像,就必须对所有层级进行建模。现有生成模型常难以准确表征物理属性和几何布局等特征,难以捕捉复杂的视觉关系。

姜若曦介绍道,该研究融合扩散模型与层级表征,不仅显著提高了复杂场景的图像生成质量,更实现了零成本的语义重采样控制,为复杂场景建模提供了新的研究方向。

在第二项工作中,研究团队将层级表征应用于动态系统的自回归建模(神经模拟器),研究论文被 NeurIPS 2025 接收。

论文地址:https://www.arxiv.org/pdf/2506.04528
神经网络数值模拟器为科学计算带来了革新,可其在破解传统计算成本瓶颈的同时,往往面临长期误差累积,难以保持稳定性和物理一致性的巨大挑战。

该研究提出了一种层级化时空表征与跨尺度隐式自回归的创新建模框架,基于传统的自回归模型,显著提升了长期预测的稳定性与短期的准确度,在气候建模、流体力学等复杂动力系统中展现出重要的应用潜力。

介绍了两项关键工作之后,姜若曦还分享了自己对于「表征」的见解,就像艺术家毕加索对于「抽象」的定义:「我们首先需要有一个对于事物的理解,然后再把一些冗余修饰进行抹除。」她指出:「表征是机器对于数据的一个理解,我们想得到更好的生成模型,就要确保模型通过表征对数据有一个很好的理解。」

催化反应预测
催化反应是构筑新物质的一种关键手段,能帮助化学家构筑材料、能源、生命、药物相关的新分子。但是由于催化反应涵盖复杂多样的化学空间,化学结构与反应性能之间的关系通常是不明晰的。

近年来,机器学习和深度学习等数据驱动方法在反应性能预测与合成规划方面展现出巨大潜力。然而,数值回归驱动的反应性能预测与基于序列生成的合成规划之间的固有方法差异,为构建统一的深度学习架构带来显著挑战。
上智院物质科学方向研究员徐丽成主要从事催化反应模型开发工作,他在分享会上介绍了一种统一的预训练反应预测框架 ——RXNGraphormer。该框架创新性地将反应性能预测(如反应活性和选择性)与单步合成规划(正向与逆向合成)整合至同一系统中,研究论文还登上了《Nature Machine Intelligence》9 月刊的封面。

论文地址:https://www.nature.com/articles/s42256-025-01098-4
研究团队特别开发了一种「片段交换算法」,通过生成虚构反应样本并与真实反应进行对比学习,使模型在预训练过程中自主掌握化学键的断裂与形成模式。这一独特策略不仅使模型无需依赖显式标注即可区分不同反应类型,还能生成具有明确化学意义的嵌入表示。

RXNGraphormer 不仅实现了对化学反应活性、选择性和单步正向 / 逆向合成的精准预测,还使模型能够自发学习化学键的变化规律,在多项预测任务中均达到领先水平。以该框架为基础的燧人催化大模型已与中国科学院上海有机化学研究所合作,在实际反应中实现选择性提升 3 倍,显著减少了项目的湿实验次数、原料浪费和副产物。

在分享会现场提问环节,一个有趣的问题吸引了大家的注意:「AI 有没有可能会基于成断键规律等本质物理化学现象,去重新定义化学反应分类?AI for Science 能否从底层去颠覆传统经验范式?」
徐丽成给出的答案是肯定的:「在我看来是可以的,因为我们这个实验确实验证了 AI 学会了键的变化,键的变化其实就是化学反应的本质,可以通过其来做一些分类。」
生物分子动态模拟
蛋白质的许多关键功能源于其随时间演化的构象变化,蛋白质的主要功能是由它的动态结构来完成的。例如,阿尔茨海默病其中一个成因就是由神经细胞之间生长的斑块中 β - 淀粉样蛋白的积累引起的。

精准生成蛋白质构象对于深入理解蛋白质功能机制及推进药物发现(如抑制剂设计)至关重要。然而,现有模型主要聚焦于蛋白质静态结构的预测。尽管静态结构为学术研究提供了重要基础,但蛋白质在生理过程中实际处于动态变化中,因此攻克蛋白质动态变化预测这一难点,对于推动 AI 应用于药物设计等实际场景中具有关键意义。

上智院生命科学方向主任研究员杨自雄,主要从事生物大模型开发工作。在分享会上,他介绍了其负责团队提出的基于 4D 扩散模型的生成框架。相关研究论文《4D Diffusion for Dynamic Protein Structure Prediction with Reference and Motion Guidance》已被学术顶会 AAAI 2025 接收。

论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/31984
该方法能够实现蛋白质动力学轨迹生成或长时间尺度的构象生成,为阐释蛋白质功能与加速药物设计提供了全新的计算范式。
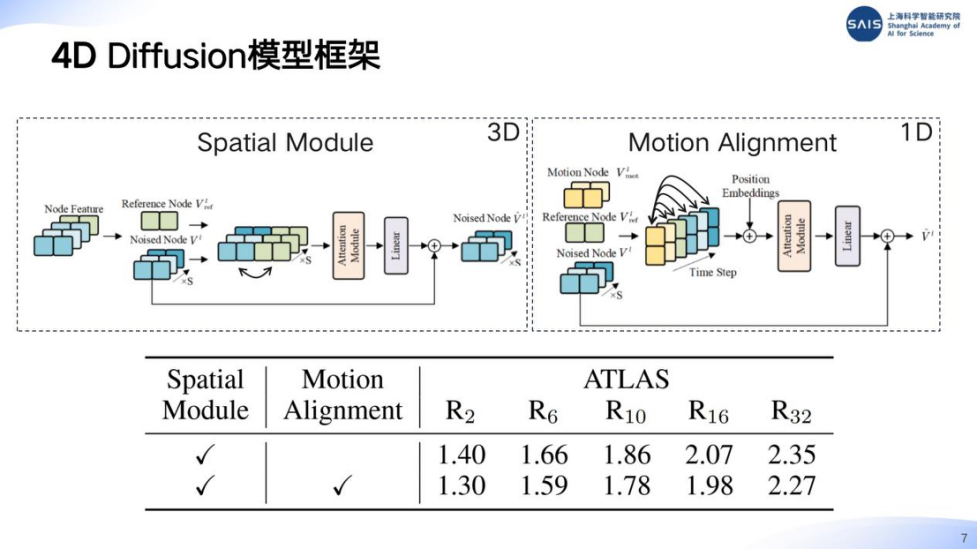
研究团队还进一步提出了「女娲蛋白状态迁移大模型」,实现了亚微秒级蛋白质动态过渡路径预测,并搭建了行业最大的全原子精度构象数据集 dynamicPDB。该数据集发布不到一年,已在开源社区获得超过 760 颗 Star、近百名关注者和 130 余个分支,迅速成长为全球蛋白质动力学研究的重要基础设施之一。

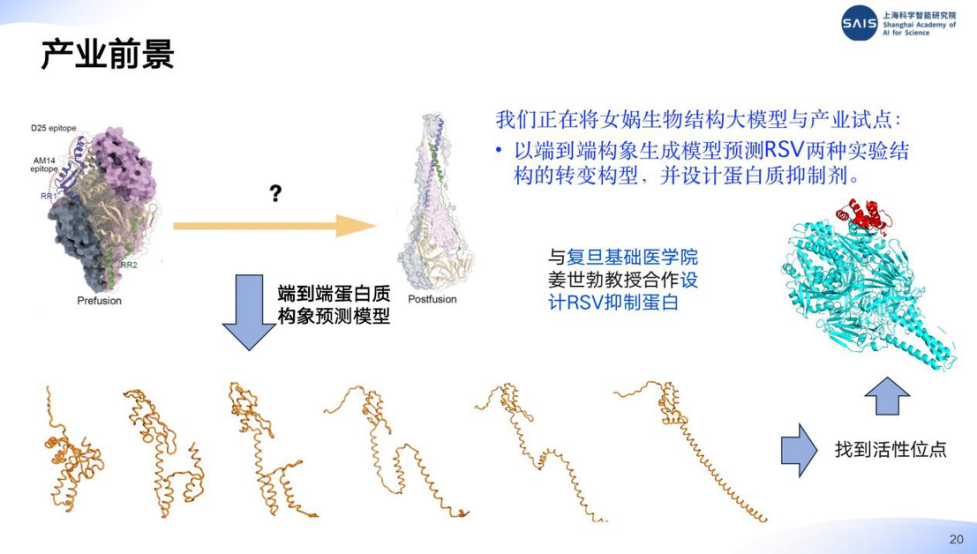
在产业合作方面,杨自雄介绍了研究团队正在进行的两项产业试点:
针对不同的蛋白质构象设计对应的抗体,实现针对变异构象的抗体诱导的自体免疫疗法;
以端到端构象生成模型预测 RSV 两种实验结构的转变构型,并设计蛋白质抑制剂。

单细胞图谱
随着单细胞测序技术的发展,我们对于疾病的发病机制有了更深刻的理解。在单细胞尺度下解析远距离的基因调控关系,对于理解细胞中的转录调控机制,进而阐明疾病相关的非编码变异的致病机制有重要意义。
上智院生命科学方向研究员张雨主要关注生命科学多组学领域的算法研究,及其在精准医疗、疾病机制解释和药物靶点发现等生物医学领域的应用。在分享会上,张雨介绍了一项关于「单细胞顺式调控关系」的工作。

论文地址:https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.202505021
顺式调控关系在基因组上广泛存在,人体发育过程实际上就是胚胎干细胞不断分化的过程,而顺式调控关系是细胞分化的主要驱动因素之一,顺式调控关系的不同塑造了人体多种多样的细胞类型。

现有工具还不能对顺式调控关系进行非常精确的预测,一是因为没有把生物学原理建模进去,还只是通过数据的相关性做出预测,二是因为没有充分利用公开数据库中大量的单细胞测序数据提高模型的预测性能。
为了解决现有计算方法预测能力不足的问题,研究团队开发了一种新的计算框架 ——SCRIPT,核心思路是将生物学的基因调控知识融合到模型中,精准预测单细胞分辨率的顺式调控关系。
研究团队认为:一维基因组上的调控元件可以通过在三维空间的折叠影响目标基因的表达,这种生物学原理很适合用图神经网络的方式进行建模,因而选择图神经网络作为基础模型架构。整个算法的设计旨在使用配对的 Single-cell ATAC-seq 和 Single-cell RNA-seq 数据模拟细胞内转录调控的过程,进而利用这个 Simulation Model 预测每个细胞内的顺式调控关系。
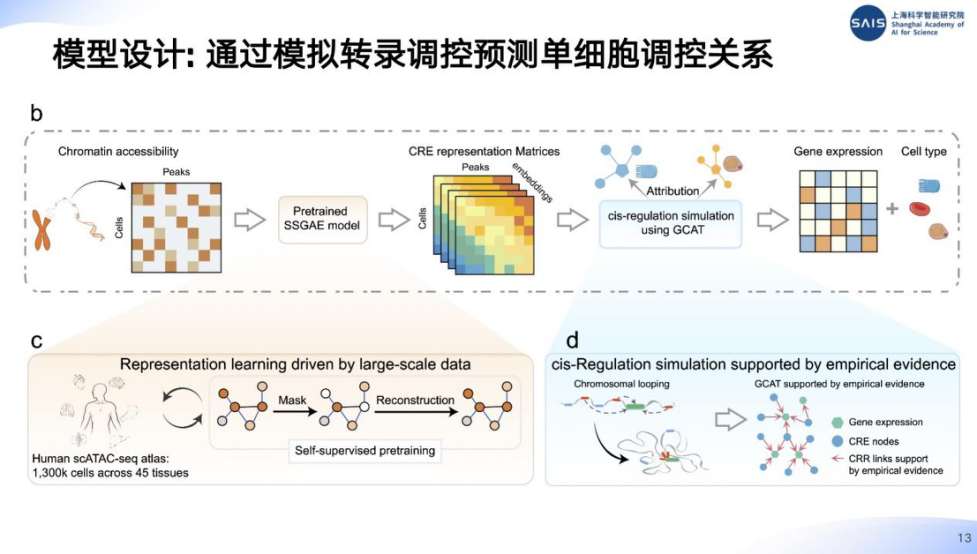
SCRIPT 在长程调控预测上取得了突破性进展,性能较当前最优方法提升逾两倍。利用其优异的预测性能,SCRIPT 在阿尔兹海默症和精神分裂症中发现了当前最优计算工具未发现的分子遗传学机制,有望在复杂疾病的遗传诊断和药物靶点发现上发挥重要作用。

由于图预训练模型存在模型结构和参数量的限制,其性能有明显的上限,因此研究团队提出了一个更先进的基础模型 ChromFound—— 基于 Mamba-Transformer 混合架构和基因组感知编码,拥有更大的参数量和更强的扩展性,在六种下游任务上达到最优性能。

全球天气预测
传统的数值天气预报系统通常由基于物理的预报模式和资料同化模块构成。其中,数值预报模式主要从当前的大气状态出发,通过求解偏微分方程来获取未来的大气状态;资料同化系统则负责吸收描述当前大气状态的大量观测,来估计当前的大气状态。预报模型和同化系统是缺一不可的,同化系统提供初始气象场,预报模型从初始气象场出发,预报未来的天气。
近年来,基于机器学习的天气预报模型已在预报性能上展现出与传统模式相当的能力,但其运行仍依赖于传统资料同化系统生成的初始场。但传统资料同化系统中卫星观测资料预处理过程特别复杂,计算资源消耗大、观测利用率低。
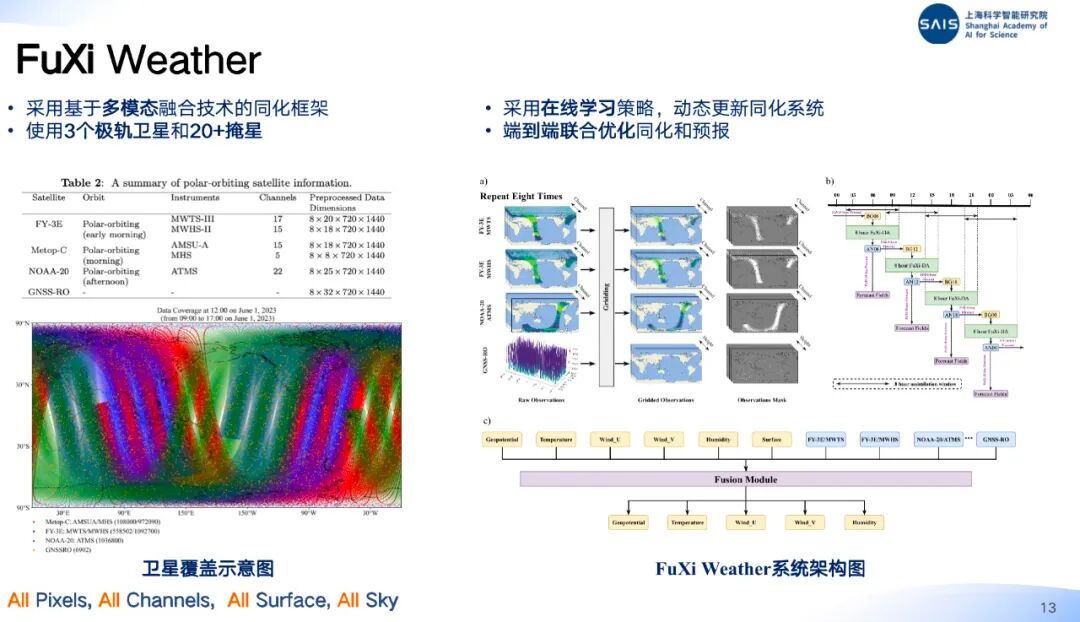
上智院地球科学方向研究员徐孝泽长期关注人工智能在数值天气预报与资料同化中的应用,实习期间就在上智院研发了首个可直接同化真实卫星观测的人工智能同化框架 FuXi-DA。这次分享会上,他介绍了伏羲气象大模型团队基于 FuXi-DA 的最新成果 —— 完全基于机器学习的全球天气预报系统 FuXi Weather。
首先,基于传统资料同化方法计算量大,观测利用率低等问题,研究团队提出了同化框架 FuXi-DA。FuXi-DA 简化了流程,提高了资料利用率,降低了计算成本,并通过引入预报损失联合优化,提高了长期预报精度。

在同化框架 FuXi-DA 的基础上,研究团队构建了全球天气预报系统 FuXi Weather。FuXi Weather 采用在线学习策略,动态更新同化系统,具备对多源卫星观测资料进行同化的能力,实现了循环资料同化与一体化预报。
在使用观测资料远少于传统数值预报系统的条件下,FuXi Weather 能够生成未来 10 天的高精度天气预报,并在观测稀疏区域的预报表现上优于欧洲中期天气预报中心(ECMWF)运行的 HRES 系统。
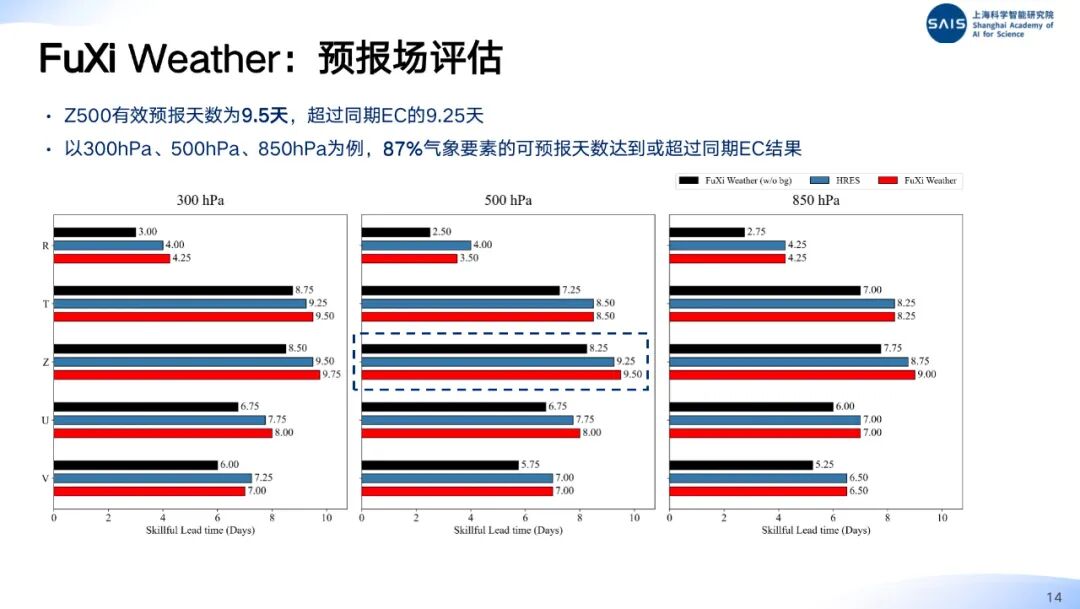
值得一提的是,FuXi Weather 采用的伏羲气象大模型不仅成功当选中国气象局官方认定的三大核心大模型之一,还在中国气象局开展的人工智能天气预报大模型示范计划中,三项综合指标均排名第一。其实战价值也在 2024 年的超级台风「贝碧嘉」等极端天气预测中得到了验证。
目前,FuXi Weather 的研究论文已被《Nature Communications》收录,徐孝泽表示研究团队正在积极推进 FuXi Weather V2 的研发工作。

论文地址:https://www.nature.com/articles/s41467-025-62024-1
汇聚青年智慧
科学智能的发展需要既懂 AI 又懂领域科学的复合型人才推动。2025 全球开发者大会期间,上智院院长漆远在接受媒体采访时就表示:「人工智能的发展,以前缺的是算力,现在比算力更缺的是人才。尤其是当人工智能走向了千行百业,和垂直领域结合,那你就需要懂这个领域。否则就像做了一个引擎,但它不是个车,不能把你从 A 点运到 B 点,所以你既要懂得领域也要知道怎么使用人工智能。」
为了汇聚青年创新力量,上智院已连续三年主导举办世界科学智能大赛,挖掘出不少创新团队。这次 SAIS Talk「上智院星辰之夜」的活动命名就源于世界科学智能大赛中备受瞩目的青年聚会传统,寓意着年轻智慧如星辰般汇聚闪耀,照亮科学智能的无限未来。
经过两年的探索,上智院已牵头研发伏羲气象大模型、燧人物质大模型、女娲生命大模型、早期中华文明多模态大模型、星河启智科学智能开放平台等一系列关键成果。在 SAIS Talk「上智院星辰之夜」上我们看到,这些成果内在的创新驱动力正是来源于众多优秀的交叉型青年科研人才。
如今的科学智能,正同步推动着基础技术突破、产业新兴应用以及全球创新生态发展。作为创新生力军,青年人才必将凭借其敢于挑战的科研精神,驱动科学智能走向新纪元。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。










