
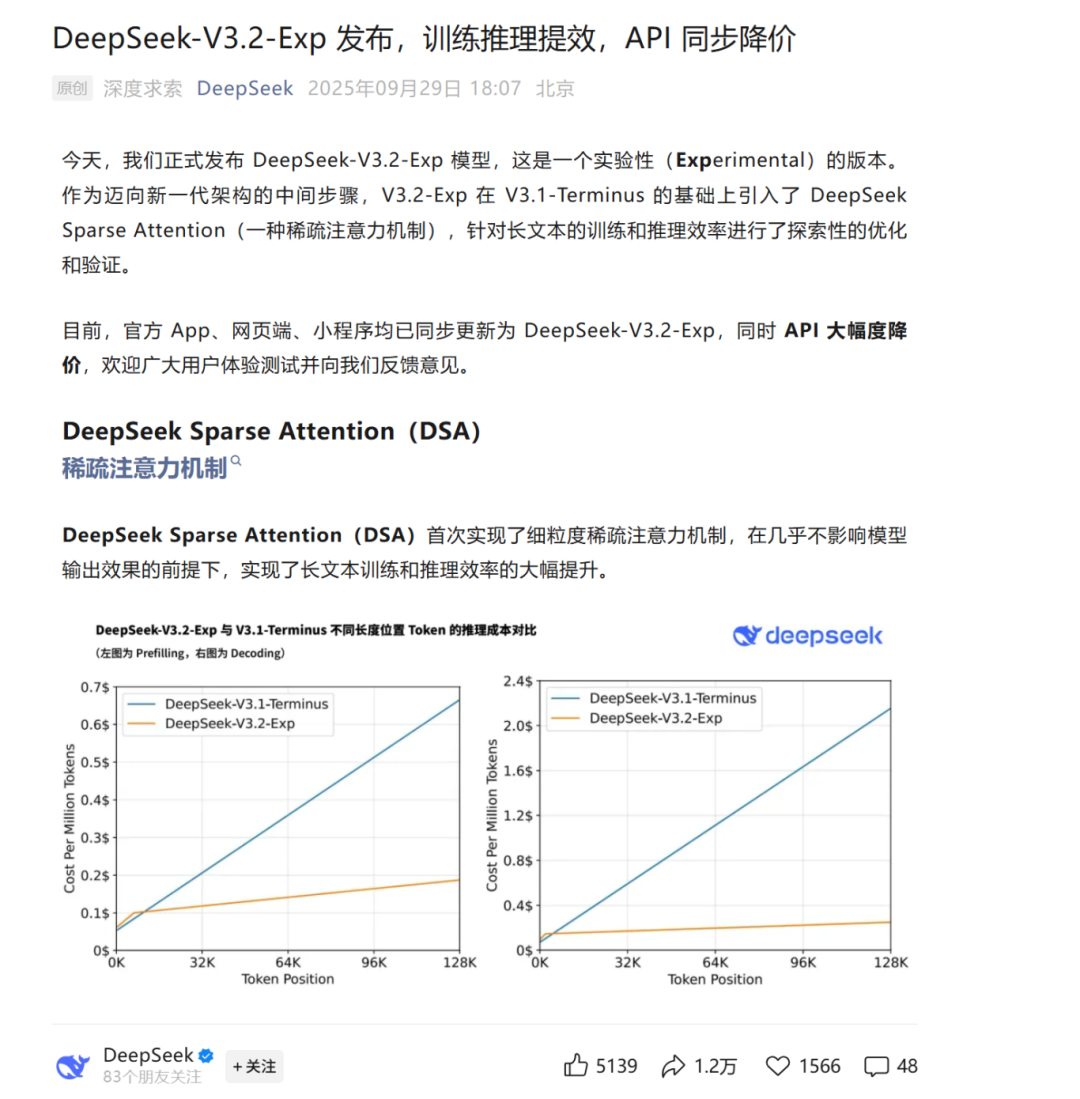
API 输入价格(缓存命中)从每百万 tokens 0.5 元降到 0.2 元,输出价格从 12 元砍到只剩 3 元,简直是三折跳楼甩卖的力度。
而且是马上生效,毫不拖泥带水,这波速度,属实带点国产厂商的豪爽气质。

这也让 DeepSeek 的 V3.2-Exp,成为了“性价比最高”的 API 之一。
其实老狐觉得连之一都可以省略了,目前主流 AI 大厂,能给到这个价格的,几乎一个没有。

值得一提的是,这波降价不是瞎搞促销,而是人家真在底层模型上做了优化。这一切的关键,是这次发布的 V3.2-Exp 模型核心创新技术:DeepSeek Sparse Attention(稀疏注意力机制,简称 DSA)。

为啥这玩意这么重要?稍微跟狐友们科普一下:
听着很抽象对吧?但其实你可以把它想象成一种“聪明的省电模式”。传统的注意力机制是每个 token 都要跟其他所有 token 打招呼,一句话几十个字,它们内部得互相问好几十次,累不累?
当然累啊,不仅计算慢,还特别烧钱(你懂的,服务器、GPU、电费、维护啥的都不是小钱)。
而 DSA 这个新招数呢?它只让重要的 token 说话,不重要的就自动闭麦,节省了大量计算资源和时间。
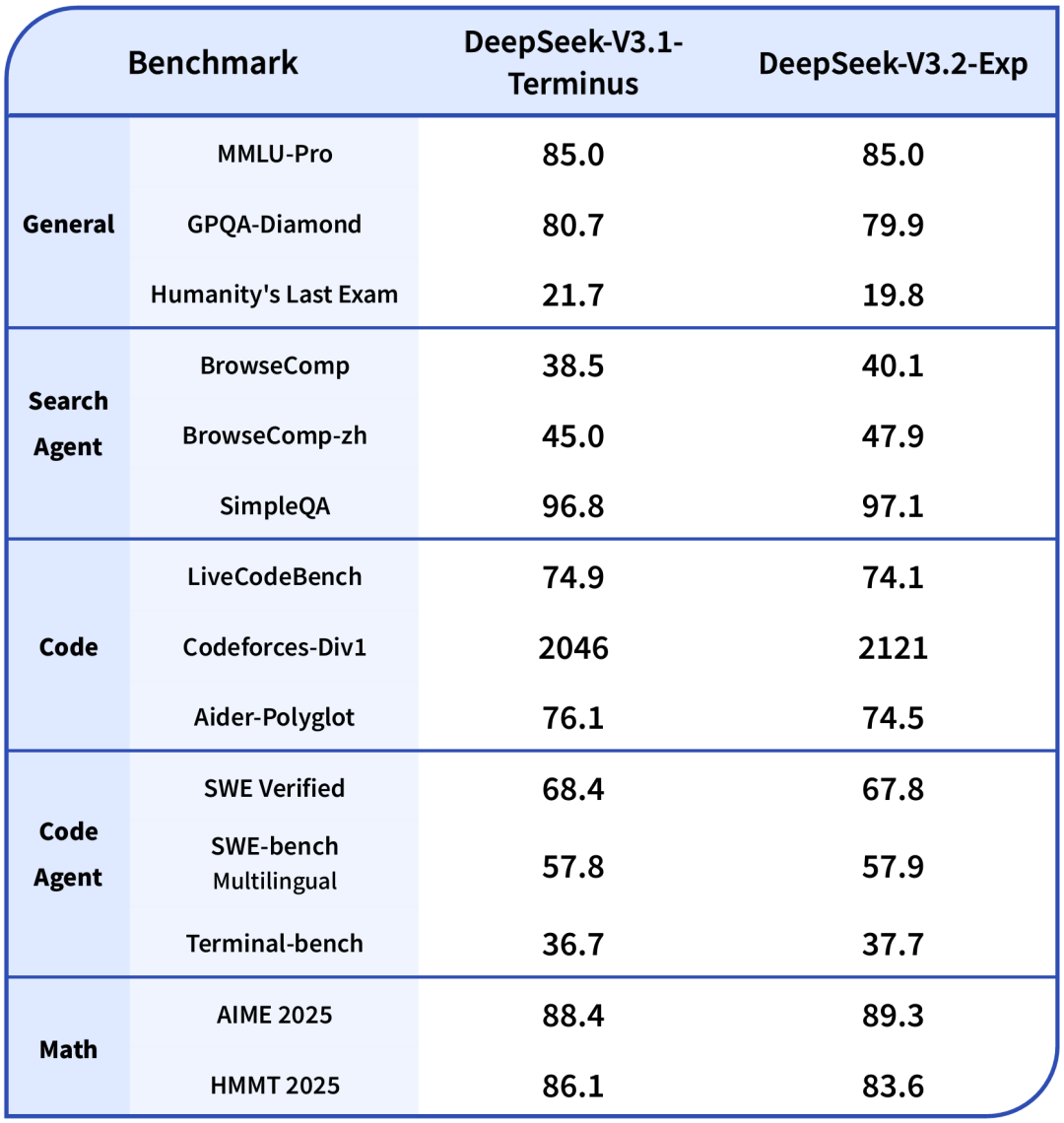
结果就是:推理更快了,成本更低了,关键是模型表现还没掉链子,跟前一版本 V3.1-Terminus 的水平差不多。就是说,在不牺牲效果的前提下,成功把算力这口锅轻了好几斤。
为啥叫“Exp”?因为这是个实验性版本,意思是团队在探索新架构的路上,迈出的关键一步,不是最终版本,但已经实用到可以全面开用。所以你现在用到的 DeepSeek API,全都已经是这个新模型了。
如果你是开发者,恭喜你,没动代码,调用成本直接砍半,喜提史上最值更新。

如果你还想对比下老模型的效果,DeepSeek也很贴心地保留了 V3.1-Terminus 的 API 接口直到 10 月 15 日,修改个 base_url 就能切换测试,不影响当前价格。
真学术范十足的安排,官方都劝你自己实测,不怕 PK,实力说话。

咱们再从开发者的角度,直白点说这波更新到底有多香。
比如你做长文本处理的,文档摘要、历史对话、代码分析这种,最怕的就是上下文太长,token 一多,价格跟着飙,跑一次你得犹豫半天。
这回好了,DSA 专门优化了“长上下文”任务的推理效率,成本一下就被拉下来了。再长的上下文也不用担心破产式调用了,终于能踏实跑大任务了。
而从模型训练的角度,V3.2-Exp 的开发过程其实也是科技感拉满。他们这次用的是“专家蒸馏+统一强化学习”双管齐下策略。

先是针对数学、编程、逻辑推理等多个领域,各自训练出了专精模型,再把这些“专家”的知识整合进最终大模型中(这波叫做蒸馏)。
然后在强化学习阶段,用一种新的 GRPO 策略(Group Relative Policy Optimization),把智能体能力、人类偏好(alignment)、推理水平全融合到一次训练中。
这样训练有两个好处:
每个领域都不落下,性能均衡
不会出现“新技能学了,旧知识忘了”的灾难性遗忘问题
更硬核的是,DeepSeek 还把 GPU 算子开源了,两套版本,TileLang 和 CUDA 全放出来了,研究、部署、二开随你选,开源力度拉满。MIT协议,不限商用,真诚到令人发指。
你要做本地部署?也OK。Docker 镜像准备好了,还兼容各种硬件平台,包括 NVIDIA H200、AMD MI350、甚至国产 NPU。
而这波重磅发布的时间点嘛……DeepSeek又一次选择了节前。
没错,他们是真的热爱在大家放假前丢重磅炸弹。前有 V3.1、再有 Terminus,这次 V3.2-Exp 又赶在国庆之前放出,这公司更新节奏,堪比高铁发车。
不过,也不是没人质疑:你这几次都是“小步快跑”,真正的大招呢?比如一直被期待的 V4、R2,什么时候上线?
甚至在 X(原推特)上就有海外网友留言问 DeepSeek:“你们啥时候发 V4?”底下有人直接回:看这节奏,短期内怕是看不到。

其实从这次发布内容来看,V3.2-Exp 已经是迈向 V4 的关键中间步骤了。
尤其是 DSA 架构的引入,为千亿参数级别的大模型做了前期验证,等下一波大规模模型上线,很可能就是在这个基础上完成的。
所以说,这波 DeepSeek 降价不仅不是“营销噱头”,反而更像是“提前放出未来技术红利”。你可以把 V3.2-Exp 看作一款“技术预告片”,但这预告片本身就已经能跑商用、能降成本、还能开源拿去部署。
这放在全球 AI 厂商里,真没几个能做到。
有人说,在开源模型竞争白热化的今天,留住开发者靠的不是光说不练,而是持续优化体验+价格给到位+社区透明度高。这次 DeepSeek 显然是三管齐下,全拿下了。
相比之下,大多数厂商仍在拼参数、拼能力、拼精度,但 DeepSeek 选择了另一条更难模仿的道路:卷服务成本,卷研发效率,卷开源透明度。
这种扎实且高门槛的优势,才是真正构筑护城河的核心。或许,是时候重新评估国产大模型实力了。












