YOLOv13出了,目标检测卷上天,2025年真的不能再做了?也不尽然。其实这方向发毕业论文属于easy模式,但如果想发点高质量的,也确实得多费心思。
今天我就给大家做点推荐,除了有名的Yolo系列之外,目标检测任务做的出彩的也就是DETR系列(基于Transformer),目前这个做的人还不算很多。另外还有开集目标检测这类,因为这小方向会涉及到多模态,属于当前学术界热点,很有前景。
再有就是大模型时代下的目标检测,比如SAM+目标检测就是个典型...其余推荐由于文章限制就不一一展开了,配上145篇目标检测参考论文,我都统一打包完毕,分享给大家,尤其是无GPU无指导的单兵们,希望可以有所帮助。

扫码添加小享,回复“135目检”
免费获取全部论文+开源代码

YOLO系列
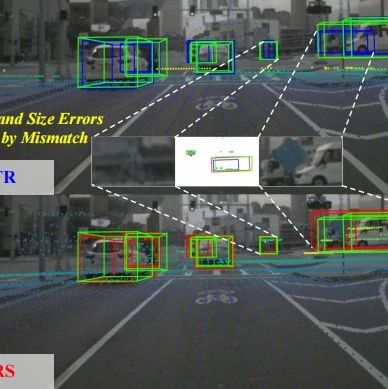
YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
方法:论文提出了一种名为YOLOv13的新型实时目标检测模型,它是对YOLO系列模型的重大改进。YOLOv13通过超图计算增强特征融合,采用轻量级深度可分离卷积块,提升实时目标检测性能,降低计算复杂度。

创新点:
提出HyperACE机制,自适应地利用超图计算建模全局高阶相关性,实现跨位置和尺度的特征融合与增强。 设计FullPAD范式,将相关性增强的特征分配到全网络,促进信息流和表示协同,提升检测性能。 使用深度可分离卷积替换大卷积核,设计轻量化块,减少参数和计算复杂度,保持性能。

DETR系列
【CVPR25】Mr. detr: Instructive multi-route training for detection transformers
方法:论文提出Mr. DETR,通过多路线训练机制改进DETR,同时进行“一对一”和“一对多”预测,加速收敛并提升检测精度,推理时移除辅助路线,不影响模型架构和推理成本。

创新点:
提出多路线训练机制,包含用于“一对一”预测的主要路线和用于“一对多”预测的辅助路线。 引入指导性自注意力机制,通过可学习的指令标记动态引导对象查询进行“一对多”预测。 辅助路线在推理阶段被移除,确保模型架构和推理成本与基线模型一致。

扫码添加小享,回复“135目检”
免费获取全部论文+开源代码

开集目标检测
More Pictures Say More: Visual Intersection Network for Open Set Object Detection
方法:论文提出 VINO 模型,用于开集目标检测。它构建多图像视觉库保存类别语义交集,通过更新机制灵活整合新信息优化特征表示,提升语义理解与检测性能,减少预训练资源消耗,还拓展至分割任务。

创新点:
构建多图像视觉库保存类别语义交集,增强语义理解。 引入多图像视觉更新机制,灵活整合新信息优化特征表示。 在开集目标检测中性能优异,且拓展至分割任务展现广泛应用前景。

SAM+目标检测
RoboFusion: Towards Robust Multi-Modal 3D Object Detection via SAM
方法:论文提出RoboFusion框架,基于预训练SAM得到SAM-AD以适配自动驾驶场景,通过AD-FPN实现特征对齐,用DGWA模块融合深度信息与图像特征并降噪,再经自适应融合机制动态调权重,增强特征鲁棒性,提升复杂环境下多模态3D目标检测性能。

创新点:
提出SAM-AD,在自动驾驶数据上预训练SAM以适应该场景,提升复杂环境感知能力。 设计AD-FPN实现特征对齐,DGWA模块结合深度信息去噪。 引入自适应融合机制,融合点云与图像特征动态调整权重,提高特征鲁棒性和检测性能。

扫码添加小享,回复“135目检”
免费获取全部论文+开源代码