AI播客,快速了解:
近日,上海脑科学与类脑研究中心Jiawei Ju、索尼互动娱乐Yifan Zhuang和哈尔滨工业大学Chunzhi Yi等发表研究,提出了一种基于脑电图(EEG)与肌电图(EMG)的混合脑机接口(BCI)技术。该技术首次系统揭示了汉语四声在无声与有声语音中的神经特征,成功实现对声调及语音模式的高效解码,为全球数亿声调语言障碍者(如聋哑人)的言语康复与顺畅沟通提供了全新解决方案。
据世界卫生组织统计,全球超4亿人存在听力障碍,其中60%-70%为聋哑人;同时,近三分之一人口使用汉语、泰语等依赖声调传递语义的声调语言。然而,现有语言识别导向的脑机接口系统普遍忽视声调识别——对声调语言使用者而言,失去声调的“语音”往往语义全失,即便借助电子喉等设备合成语音,也难以实现准确沟通。
此前研究中,EEG相关探索多聚焦词汇或音节想象,未触及声调的神经机制;EMG虽用于语音解码,却未结合声调在不同语音模式下的肌肉激活差异,这一研究空白成为声调语言障碍者脑机接口辅助沟通的关键瓶颈。
本研究共招募12名24-35岁健康受试者。实验中,团队筛选汉语4个声调各30个常用汉字,每个汉字非连续出现4次且呈现顺序随机;受试者需在屏幕显示汉字时,分别以“无声(默读不发声)”和“有声(正常发声)”两种模式完成发音,每个汉字显示1.5秒后进入1.5-3秒休息阶段,直至所有汉字完成呈现。
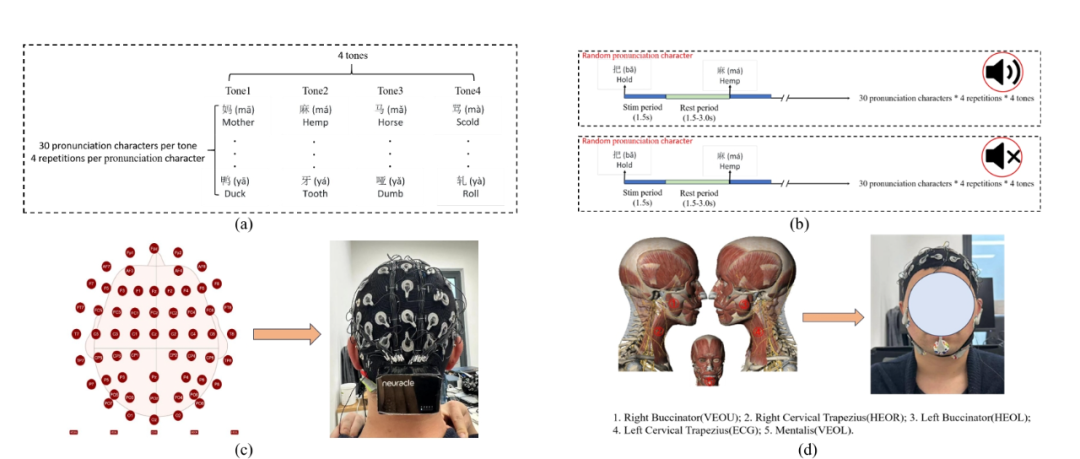
实验范式与数据收集 @IEEE
数据采集环节,团队采用64通道NeuSenW无线EEG系统(采样率1000Hz)捕捉脑电信号,同时通过专用通道采集右颊肌、左颊肌、颏肌等5个发音相关肌肉的EMG信号,全面记录声调产生时的神经与肌肉活动。
经过标准化信号处理与分析,研究团队发现了汉语四声的显著神经与肌肉特征差异。EEG时频分析显示,额叶是四声差异最核心的脑区——无声模式下,额叶不同声调激活的ANOVA检验p值为0.000,一声与二声、一声与四声的两两比较p值均为0.000,三声与四声也达到0.001的显著水平;有声模式下,额叶差异更为明显,所有声调两两比较p值均小于0.05。频域层面,中央区及C6通道的特征差异极显著(p=0.000),且有声模式下除枕叶外,所有脑区均表现出四声差异。

不同受试者的声调脑地形图 @IEEE
EMG分析则指出,左颊肌在无声模式下四声激活差异显著(p=0.023),颏肌的频域特征在两种语音模式下均呈现极显著差异(p=0.000);无声模式下5块肌肉均有差异,有声模式则集中在右颊肌、右颈斜方肌与左颊肌。值得注意的是,二声与四声的激活模式在两种模式下均存在较高重叠,这也成为后续解码需突破的难点。
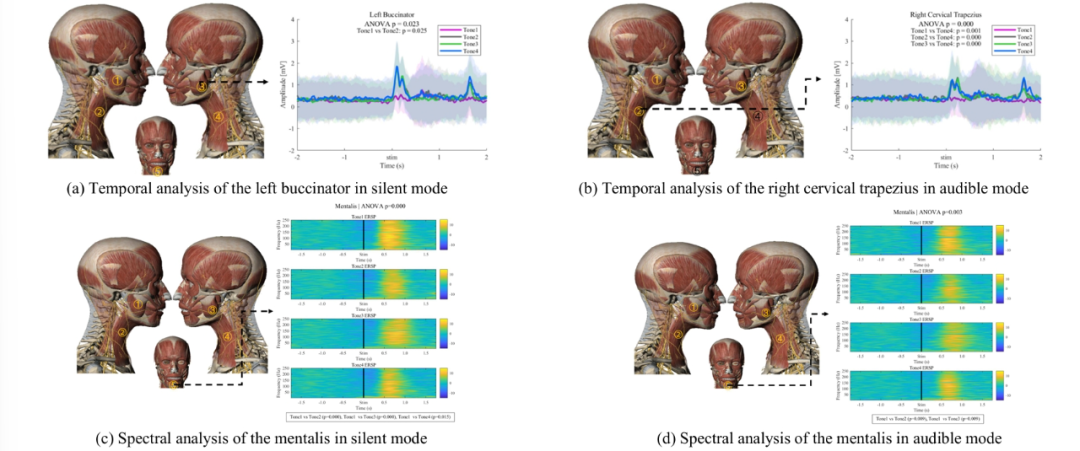
肌电信号声调的时间和频谱特征 @IEEE
在解码性能上,该混合脑机接口展现出优异表现。针对四声多分类任务,采用EEG时域特征结合支持向量机(SVM)分类器时,有声模式准确率达72.43%;结合正则化线性判别分析(RLDA)分类器时,无声模式准确率达71.22%,均显著优于频域特征解码效果。
更具实用价值的二分类任务中,RLDA结合EEG时域特征表现最佳——无声模式平均准确率91.00%,有声模式90.92%,其中一声与二声分类准确率最高(无声97.3%、有声98.0%)。而在区分“无声/有声”语音模式的任务中,EEG与EMG特征级融合的方案突破瓶颈:RLDA分类器结合时域特征时,准确率高达81.33%,显著高于EEG单独解码的79.36%;通过SHAP值评估发现,EMG特征贡献度达58.80%,EEG为41.20%,证实二者的互补优势。
研究团队表示,这项研究的核心价值在于为声调语言障碍者搭建了“神经-语义”的沟通桥梁。该技术不仅首次揭示了四声的多模态神经特征,更通过EEG-EMG融合提升了实用性能——对无法正常发音的聋哑人而言,未来只需通过“默读”或轻微肌肉活动,脑机接口即可精准解码声调与语义,结合语音合成设备实现顺畅交流。
尽管当前跨被试解码准确率(无声声调56.51%、有声声调63.02%)仍有提升空间,团队计划后续引入深度学习优化特征提取,同时纳入性别、姿势等个体差异因素,进一步拓展技术适用场景。该研究得到上海扬帆计划基金(24YF2730700)支持,其成果为声调语言脑机接口研究开辟新方向,也为全球声调语言障碍者的言语康复带来新希望。
*本文主要基于10月1日发表于《IEEE Transactions on Neural Systems and Rehabilitation Engineering ( Early Access )》的研究《An EEG-EMG-based Hybrid Brain-Computer Interface for Decoding Tones in Silent and Audible Speech》,图片来自网络或论文,播客由AI生成。本文仅用作学术分享,如有侵权请告知删除。












