超越简单的准确率,重新评估抽象能力
作者:MELANIE MITCHELL
日期:2025 年 10 月 7 日
在此,我将概述我们团队的一篇新论文:AI 推理模型是否执行类人抽象推理?
抽象与推理语料库,即 ARC-AGI-1,已成为衡量 AI 模型抽象推理能力的通用标准。
它旨在测试 AI 基于人类核心知识的抽象与类比能力,尤其是对象性这一关键先验。
同时,它也涵盖了基础的空间几何概念(如内外、上下)、语义概念(如异同)以及数值尺寸概念(如大小)。
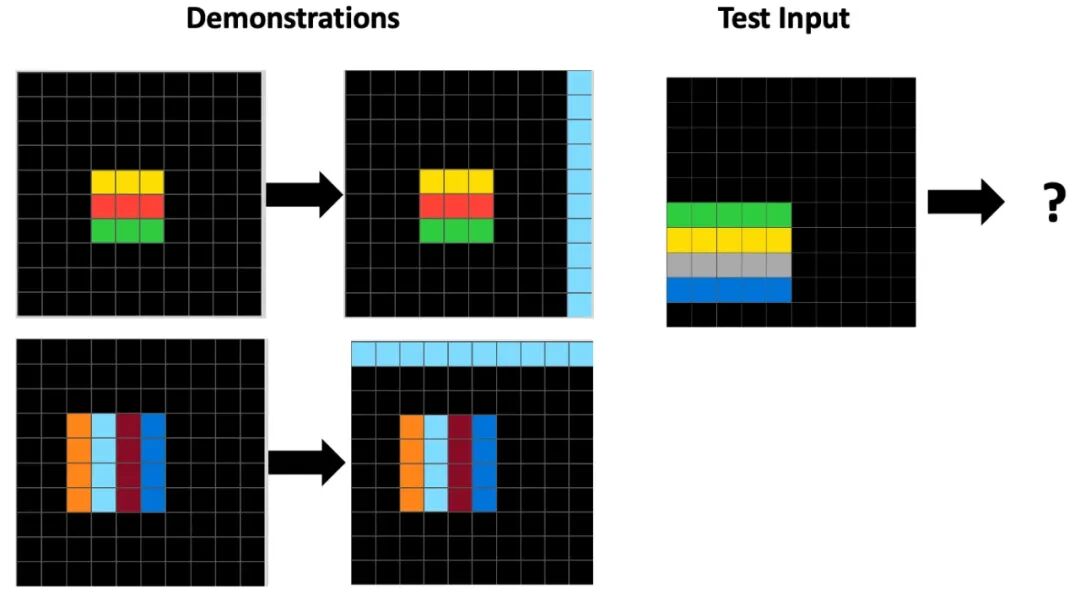
我们来看一个具体的例子。这个任务展示了三组输入到输出的转换示范,你需要找出其中的规律。
然后,将这个规律应用到新的测试输入上,从而得到正确的输出结果。

(图片描述:一个 ARC 任务示例,包含三个“输入-输出”对作为示范,以及一个待解决的“测试输入”。)
这个任务的规律可以总结为:提取最大空心矩形内部的子网格。
这里需要模型理解并运用的抽象概念包括:最大、空心、矩形、内部,以及提取子网格。
什么是真正的 AI 推理能力?
像 OpenAI 的 o3 这类 AI 推理模型,在 ARC 测试上的准确率已超过人类平均水平。然而,分数并不能说明一切。
它们得到正确答案的理由,和人类一样吗?它们真的掌握了任务设计者预设的抽象概念吗?
还是说,它们走了另一条路——利用一些低级、通用性差的模式,也就是我们常说的捷径来解题?
大型神经网络常常为了在基准测试中取得高分而找出这类捷径,但这也意味着它们在训练数据分布之外的泛化能力会很差。
为了探究这个问题,我们在 ConceptARC 这个基准上,对包括 o3、Claude Sonnet 4 和 Gemini 2.5 Pro 在内的多个模型进行了评估。
ConceptARC 专门为 ARC 领域设计,其包含的 480 个任务分别对应着不同的核心抽象概念。
下面是两个 ConceptARC 任务的例子:左边一个是关于“横向与纵向”的概念,右边一个是关于“补全形状”的概念。
(图片描述:两个 ConceptARC 任务。左侧任务展示“水平 vs. 垂直”概念。右侧任务展示“补全形状”概念。)
在实验中,我们为模型同时提供了两种输入方式。
一种是文本输入,将网格表示为由 0 到 9 的数字(代表颜色)组成的矩阵;另一种是视觉输入,即人类看到的图像。
我们不仅要求模型生成最终的输出网格,还要求它用自然语言解释其背后的转换规则。
我们对模型生成的每一条规则进行了人工评估,分为三类:
符合预期的正确:规则捕捉到了预设的抽象概念。 不符合预期的正确:规则能解释通示范案例,但并未抓住预设的抽象概念。 错误:规则无法解释通示范案例。
然后,我们将 AI 的规则与人类生成的规则进行对比。
当 AI 走上捷径
以下是针对“横向与纵向”任务,人类与各 AI 模型(均使用文本输入)生成的规则。
请注意,人类看到的是图像,而模型处理的是代表颜色的数字数组。在 AI 的规则中,数字 8 代表浅蓝色。
人类: 如果线条是横的,就在最右边画一整列浅蓝色竖线。如果线条是竖的,就在最顶上画一整行浅蓝色横线。
[评价:符合预期的正确]
Gemini: 找到连续的非零数字区域。如果数字在每行都相同,就用 8 填充最右列。如果数字在每列都相同,就用 8 填充最顶行。
[评价:符合预期的正确,尽管其描述方式与人类不同]
o3: 判断彩色条纹是横向还是纵向。若是横向,则在离条纹最远的空白边缘列涂上颜色 8;若是纵向,则在最远的空白边缘行涂上 8。
[评价:接近正确,但它关注的“距离最远”并非核心意图,因此属于不符合预期的正确。]¹
Claude: 如果输入中有数字 8,就用 8 填充第一行;如果没有,就用 8 填充最后一列。
[评价:典型的“正确的答案,错误的理由”。它关注的是有无浅蓝色这个浅层特征,完全没理解横竖线的概念,属于不符合预期的正确。]
接下来是“补全形状”任务的规则分析。在这里,数字 5 代表灰色。
人类: 右上角是样本。别动它。参考左边的两个图形,用和它们一样的颜色,把它们补充得和样本一模一样。
[评价:符合预期的正确]
Gemini: 对于除 5 以外的每种颜色,找到其边界框并用该颜色填满。所有 5 都替换为 0。如果边界框重叠,取值更高的颜色。
[评价:此规则在第二个示范中不成立,因此被评为错误。]
o3: 擦掉出现最多的颜色。对其他颜色,找到行列索引最小的像素,画一个 3x3 的方块。如果该颜色原本多于三个像素,就填满方块;如果只有两个,就画一个箭头图案。
[评价:这是在死记硬背。它为两个示范提供了精确指令,却毫无泛化能力。一个“不符合预期的正确”的绝佳案例。]
Claude: 移除所有 5。对于剩下的颜色,如果只有 2 个单元格,就套用 T 形模板;如果有 3 个或更多,就填满整个边界矩形。
[评价:与 o3 类似,它只是在描述两个孤立的案例,没有抓住“参照样本补全形状”这个核心抽象。]
超越准确率:为何需要类人抽象?
我们的研究发现,尽管 AI 模型在文本输入上的准确率不输人类,但它们远比人类更倾向于使用非预期的捷径来解题。
一个有趣的现象是,这些模型倾向于从像素、颜色、行列的角度描述网格,而非从“物体”的视角。
这表明,至少在文本环境中,它们似乎缺乏一种与人类相似的、强大的对象性先验。
换成视觉输入后,所有模型生成正确网格的准确率都大幅下降。
但值得注意的是,它们生成「符合预期的正确」规则的频率,反而比生成正确网格的频率更高。
这说明,在某些情况下,模型确实能够正确地处理和理解视觉信息。
我们的研究传递出的核心信息是,仅仅依赖准确率的评估方式,可能会高估 AI 在文本环境下的抽象推理能力。
同时,这种方式也可能低估了它们在视觉环境下的抽象推理潜力。
在评估 AI 的能力时,我们必须超越准确率这个单一维度!
有人可能会问,AI 是用“人类的方式”还是用“捷径”来解决问题,真的那么重要吗?
答案是,非常重要。掌握并运用与人类相似的抽象概念,正是 ARC 这类基准测试的根本目的。
正是凭借这种能力,我们人类才能理解世界,预测未来,并从容应对未知。这些,也正是我们对 AI 系统寄予的期望。
更进一步说,若想实现真正的人机协作,AI 就必须更好地理解我们的抽象思维。
只有这样,它们才能理解我们的意图,并用我们能懂的方式,解释自己的思考过程。
论文地址: https://arxiv.org/abs/2510.02125
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!