点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
3D视觉工坊很荣幸邀请到了武汉大学徐淇和西湖大学韦东旭,为大家着重分享他们团队的工作。如果您有相关工作需要分享,欢迎文末联系我们。
 SIU3R: SImultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
SIU3R: SImultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
主页:https://insomniaaac.github.io/siu3r/
代码:https://github.com/WU-CVGL/SIU3R
直播信息
时间
2025年10月10日(周五)19:00
主题
NeurIPS'25 Spotlight开源 | 首个免对齐框架SIU3R!无需2D特征对齐,0.1秒同时实现场景理解与三维重建!
直播平台
3D视觉工坊视频号
点击按钮预约直播
3D视觉工坊哔哩哔哩也将同步直播
主讲嘉宾
徐淇
武汉大学摄影测量与计算机视觉实验室硕士在读,目前在西湖大学空间智能与机器人实验室访问。研究方向为三维视觉基础模型、三维多模态大模型。
韦东旭
浙江大学博士毕业,曾于阿里巴巴达摩院城市大脑实验室从事视觉算法研究,目前在西湖大学工学院担任博士后。研究方向为可泛化的三维重建与生成、空间智能感知与理解。
直播大纲
背景与动机 技术方案 实验结果分析
参与方式

工作简介
本文是西湖大学刘沛东教授团队在3D场景理解与重建领域的最新研究成果,相关论文已被 NeurIPS 2025 接收,并被选为 Spotlight,代码/数据/模型权重已开源。
项目主页:https://insomniaaac.github.io/siu3r/ 论文链接:https://arxiv.org/abs/2507.02705 项目代码:https://github.com/WU-CVGL/SIU3R
背景与动机
近年来,三维重建和场景理解技术都取得了长足的进步,但两者往往被作为独立任务来研究,这阻碍了端到端具身智能系统的发展。为了将两者结合,近期的工作(如 DFF, LERF, LSM 等)大多遵循一种 “2D-到-3D特征对齐” 的范式:首先从预训练的2D视觉语言模型(如CLIP)中提取2D特征,然后通过逐场景优化的方式,将这些2D特征“贴”到三维几何表示(如NeRF或3D高斯)上。 然而,这种“特征对齐”的范式存在两大固有瓶颈:
实例级别理解能力受限:依赖的2D大模型通常缺乏精细的实例识别能力,导致现有的3D理解方法难以完成实例分割或全景分割等需要区分不同物体的任务。 特征压缩导致信息损失:为了在三维空间中高效存储和渲染,从2D模型提取的高维特征(如512维)通常需要被压缩到较低维度(如64维)。这种压缩会丢失大量细粒度的语义信息,从而降低3D理解的精度。
为了从根本上解决上述问题,我们提出了SIU3R,一个首创的、无需特征对齐的、可泛化的同时进行场景理解与三维重建的框架。我们的核心思想是:放弃“隐式特征对齐”,回归“原生3D理解”。我们不将2D特征“贴”到3D高斯球/点云上,而是通过像素对齐的2D到3D提升(2D-to-3D Lifting),让模型直接在3D空间中进行理解,从而摆脱2D特征模型的性能瓶颈和信息损失问题。

技术方案
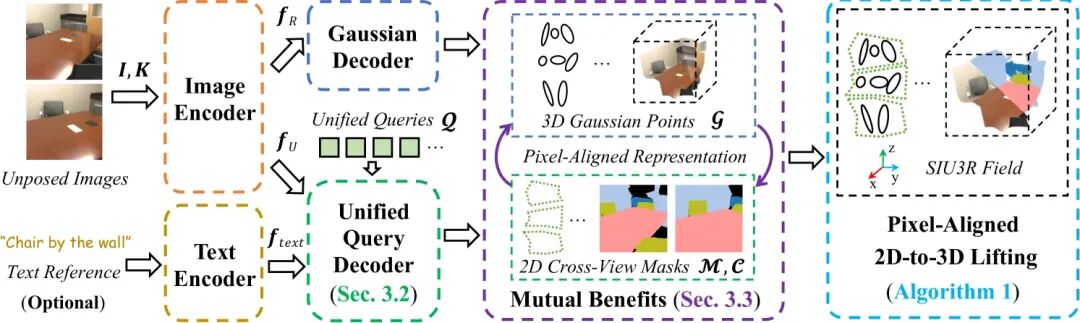
1. 整体框架:
如图2所示,SIU3R框架的核心在于通过像素对齐的3D表示(Pixel-Aligned 3D Representation)来桥接重建与理解两个任务。我们设计了统一查询解码器(Unified Query Decoder)和任务间互益机制(Mutual Benefit Mechanism),使得模型可以在共享的表示上,同时完成高质量的3D重建和多粒度的3D场景理解。
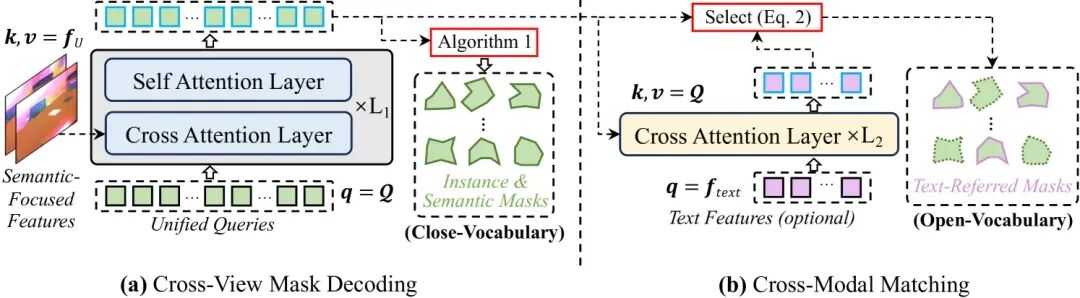
2. 统一查询解码器 (Unified Query Decoder):
为了实现“原生3D理解”,我们不再依赖外部2D模型的特征。我们引入了一组统一的可学习查询(Unified Learnable Queries)。这组查询有两大特点:
跨任务共享:无论是语义分割、实例分割、全景分割,还是文本指向性分割,都由这一组查询统一完成。模型通过学习,将不同理解任务的知识嵌入到这些查询上。 跨视角共享:这组查询在处理不同输入视角时保持不变,确保了在三维空间中理解结果的一致性。这种设计使得SIU3R能够通过2D-to-3D Lifting直接在3D层面进行端到端的学习和推理,而不是间接地对齐2D特征,从而实现了更强大和更灵活的3D理解能力。
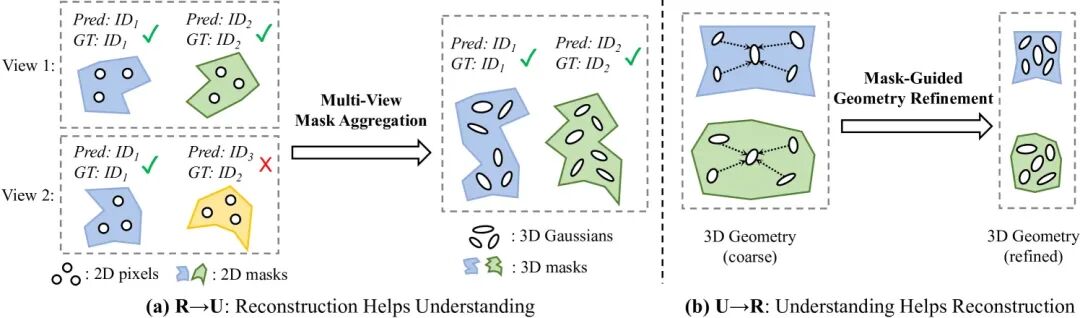
3. 任务间互益机制 (Mutual Benefit Mechanism):
既然重建和理解共享同一个框架,它们之间能否互相促进?我们对此进行了深入探索,并设计了两个轻量级模块来显式地增强这种“双赢”关系:
从理解到重建:掩码引导的几何增强 (Mask-Guided Geometry Refinement)我们利用场景理解任务预测出的实例掩码(mask)来指导几何重建。具体来说,我们施加一个约束,要求同一个物体实例内部的深度预测应该是连续平滑的。这使得重建出的物体表面更完整,边缘更清晰,有效提升了物体边界处的几何质量。 从重建到理解:基于渲染的掩码聚合 (Mask-View Mask Aggregation)我们利用3D重建来提升3D理解的一致性。具体来说,模型为每个输入视角预测2D掩码,我们将其提升到三维高斯上。然后,通过在新视角下进行渲染,可以将来自不同源视角的信息进行融合和传播,从而生成在任意新视角下都高度一致的3D分割结果。这个过程无需额外训练,即插即用。
通过这两个模块,重建为理解提供了一致的几何先验,而理解则为重建提供了精细的结构指导,实现了1+1>2的效果。
实验结果分析
我们在权威的室内场景数据集ScanNet上进行了大量实验,以验证SIU3R的有效性。实验结果表明,我们的方法在 3D重建、场景理解、同步3D重建与理解这三个方面均取得了当前最佳(State-of-the-Art)的性能。
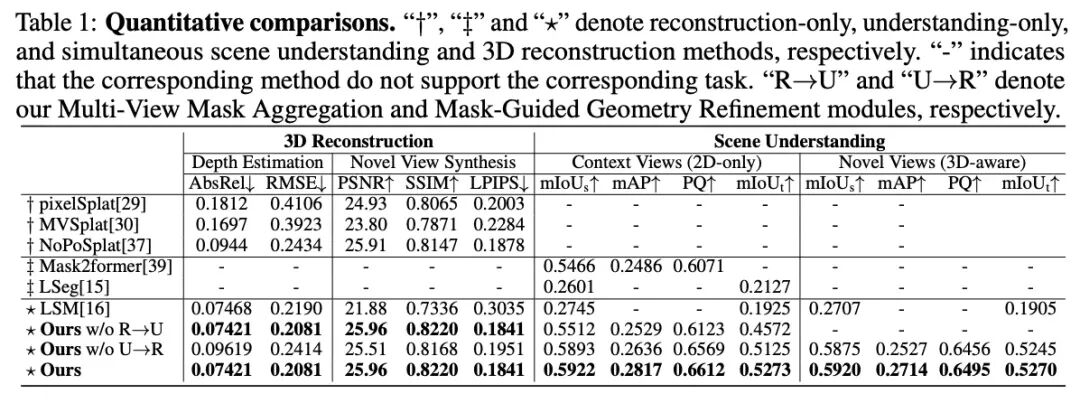
从表1可以看出,相较于之前基于特征对齐的方法,SIU3R不仅在PSNR等重建指标上表现优异,更在传统方法难以处理的实例分割(mAP)和全景分割(PQ)任务上取得了巨大优势,充分证明了我们“免对齐”框架的优越性。
此外,消融实验详细验证了我们提出的各个模块的有效性,特别是“任务间互益机制”中的两个模块,它们分别为重建和理解任务带来了显著的性能提升。
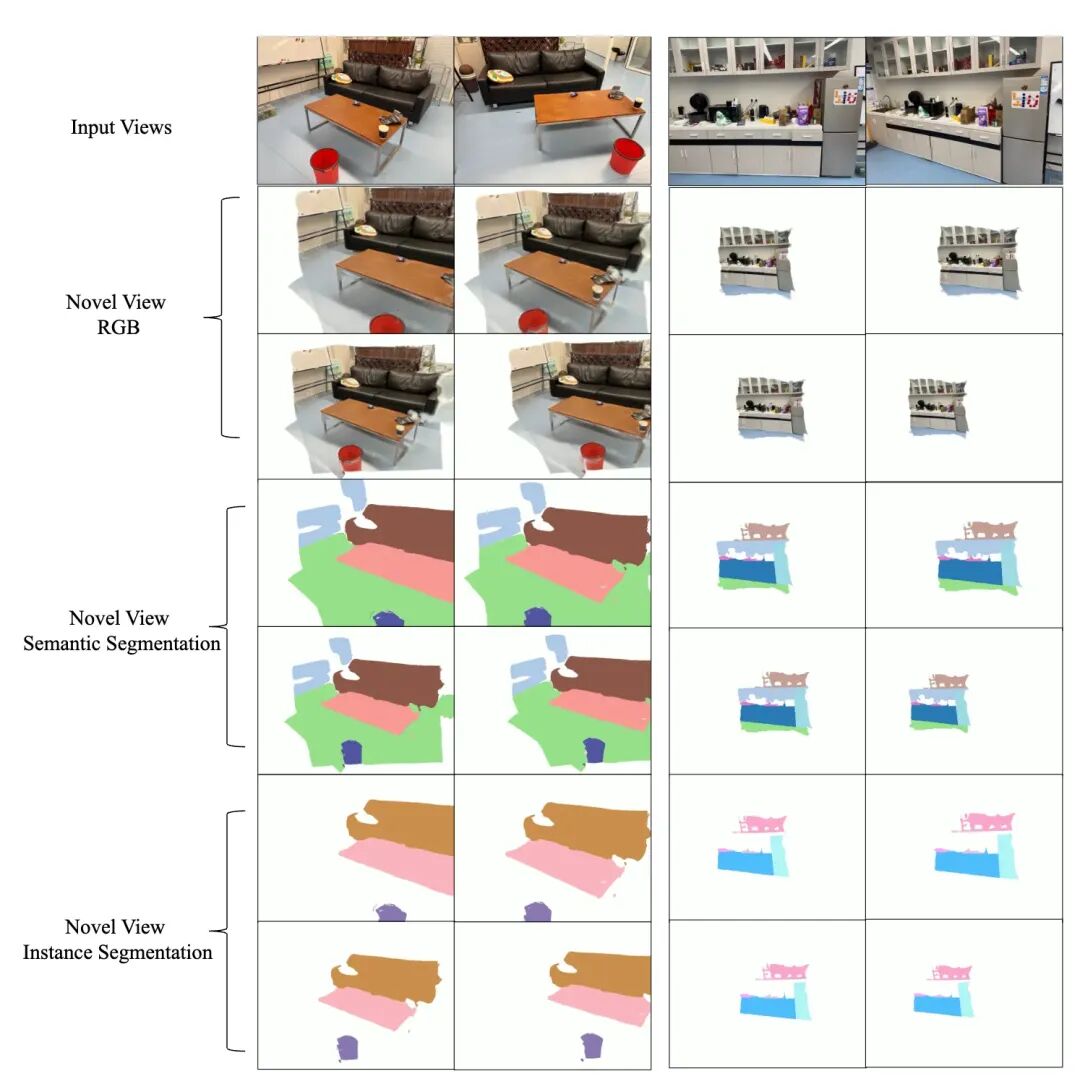
下图展示了SIU3R在重建和理解任务上的可视化效果。可以看到,我们的方法不仅能生成高质量、几何细节丰富的重建结果,还能同时输出精准的多粒度3D语义、实例和全景分割。

我们还在补充材料中进行了更多实验分析,并提供了更多的定量和定性的结果,包括但不限于:
与优化方法的对比:SIU3R作为一个前馈网络,能够在0.1秒内完成重建与理解,而优化方法通常需要十分钟到数小时的逐场景优化。我们的方法不仅在速度上有压倒性优势,在性能上也远超这些方法。 真实场景下的泛化能力:我们在真实拍摄的室内场景中测试了SIU3R,结果显示其具有良好的泛化能力,重建效果和分割性能均保持在较高水平。
个人和团队信息
徐淇
本文共同第一作者,武汉大学摄影测量与计算机视觉实验室硕士在读,目前在西湖大学空间智能与机器人实验室访问。研究方向为三维视觉基础模型、三维多模态大模型。
韦东旭
本文共同第一作者,浙江大学博士毕业,曾于阿里巴巴达摩院城市大脑实验室从事视觉算法研究,目前在西湖大学工学院担任博士后。研究方向为可泛化的三维重建与生成、空间智能感知与理解。
西湖大学-空间智能与机器人实验室
该实验室由刘沛东教授创立。刘沛东教授博士毕业于苏黎世联邦理工学院(ETH Zurich),师从 Marc Pollefeys 教授和 Andreas Geiger 教授,2021年获得计算机科学专业科学博士学位后加入西湖大学,目前已在CVPR、ICCV、ECCV、NeurIPS、ICLR、ICRA、TRO、TPAMI等国际顶级会议或期刊上发表论文40余篇。团队研究主要集中在三维计算机视觉、机器人和具身智能等领域,成员均来自上海交大、同济、西安交大、美国西北大学等海内外知名高校,拥有计算机科学与技术、自动化、机械电子等多专业背景。欢迎大家前来访问交流与合作。
武汉大学-摄影测量与计算机视觉实验室 (GPCV)
该实验室由季顺平教授创立。季顺平,武汉大学教授,博士生导师,珞珈青年学者,主持和参与多项国家自然科学基金面上项目、重大项目、重点项目、973计划、863计划等纵向科研项目。在ISPRS会刊、IEEE TGRS、PAMI、CVPR、ICCV、ECCV、NeurIPS等国际重要期刊和计算机视觉顶级会议上发表论文100余篇。团队研究主要集中在摄影测量与遥感、多模态大模型、三维视觉等方向,欢迎大家前来访问交流与合作。
注:3D视觉工坊很荣幸邀请到了武汉大学徐淇和西湖大学韦东旭,为大家着重分享他们团队的工作。如果您有相关工作需要分享,
欢迎联系微信:cv3d009,请备注:宣传工作,则不予通过。