SAIL-VL2团队 投稿
量子位 | 公众号 QbitAI
2B模型在多个基准位列4B参数以下开源第一。
抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。
SAIL-VL2以2B、8B等中小参数规模,在106个数据集实现性能突破,尤其在MMMU、MathVista等复杂推理基准超越同规模模型,甚至比肩更大参数的闭源模型。
方法上,SAIL-VL2通过数据、训练、架构三大维度的创新,为社区提供“小模型也能有强能力”新范式。
SAIL-VL2既具备细粒度视觉感知能力,又能在复杂推理任务中媲美更大规模模型。同时,团队通过开源模型与推理代码,提供可扩展的多模态基础模型。

Pretrain:三大核心创新
架构层面:稀疏MoE+灵活编码器,平衡性能与效率
SAIL-VL2突破传统稠密LLM的架构,引入稀疏混合专家(MoE),并提供多规格模型配置,满足不同场景需求:

SAIL-ViT:渐进式优化的视觉编码器
为攻克视觉-语言对齐这一核心挑战,SAIL-VL2设计了「热身适应→细粒度对齐→世界知识注入」三阶段训练:
阶段I(热身适应):冻结SAIL-ViT与LLM,仅训练Adapter,使用8M数据激活跨模态映射能力; 阶段II(细粒度对齐):固定LLM,解锁SAIL-ViT与Adapter,使用6.7M Caption和COR数据,强化跨模态对齐深度; 阶段III(世界知识注入):解锁所有参数,使用36.5M多任务数据,提升模型泛化能力。
经此流程,SAIL-ViT与LLM特征空间的平均最近邻距离从1.42降至1.15,Wasserstein距离从4.86降至3.88,证明视觉-语言对齐效果显著提升。
MoE架构:参数与计算的平衡
SAIL-VL2的31.1B大模型采用Qwen3-MoE架构,每次推理仅激活3B参数。为优化专家激活不平衡问题,模型引入负载均衡损失与数据校准策略,最终将专家激活熵提升20%,保障了各专家功能特化。
SAIL-ViT-AnyRes:任意分辨率的突破
为打破传统ViT的固定分辨率瓶颈,SAIL-ViT-AnyRes借助“2D RoPE插值”技术,实现了对任意分辨率输入的动态支持(最高1792×1792)。这一突破的价值在RefCOCO视觉定位任务中得到验证:其平均精度高达57.82,远超固定分辨率版本的53.28。
数据层面:评分过滤+合成增强,构建高质量多模态语料库
SAIL-VL2设计了一套全自动数据pipeline,从“质量筛选”与“类型扩展”两大方向提升数据价值:

SAIL-Caption2:通过“视觉信息丰富度(VIR)”与“图文对齐度(ITA)”双维度评分(1-5分),过滤低质量样本(得分<3),得到250M通用caption+1.69M图表caption; 合成VQA数据:将80MSAIL-Caption2通过LLM生成QA形式,补充QA数据多样性; 纯文本与多模态指令数据:文本语料保留LLM语言能力,VQA数据强化指令跟随能力。
训练层面:渐进式框架+动态学习率,激活模型多维度能力
SAIL-VL2设计三阶段视觉预训练与两阶段多模态预训练的渐进式流程,从基础感知逐步过渡到复杂推理:

两阶段多模态预训练:先通过“基础预训练”(64M数据)培养跨模态对齐能力,再通过“多任务预训练”(180M数据)强化视觉理解与指令跟随能力; 数据重采样:数据集平衡采样比例,在语言层面优化n-gram分布,缓解数据偏置,提升训练效率; 动态学习率:使用AdaLRS算法——基于损失下降斜率动态调整学习率,训练效率大幅提升。
Posttrain:全链路优化
后训练数据:三大高质量数据集
SAIL-Video
针对视频理解中“帧-指令错位”痛点,从6个权威数据集初筛623万条样本,通过“视频-问答对齐度(-1~10分)、内容丰富度(-1~7分)、问答难度(-1~3分)”双维度评估,仅保留均达标的样本,最终得到510万条高质量视频-问答数据,保障视频理解训练可靠性。
SAIL-Instruction2(指令微调数据)
使用Mammoth、MMPR等数据集补充长回答与推理样本,通过“质量评估+增量评估”双验证与“潜在类别过滤”,生成2000万条指令样本。

Multimodal CoT Data(多模态思维链数据)
基于VisualWebInstruct、MathV360K等数据集,通过“质量过滤、格式统一、样本去重”清洗,筛选出“有挑战性但可解决”的样本,最终形成40万LongCoT SFT样本、100万条Think-Fusion SFT样本及15万条RL样本,为推理训练提供结构化数据支撑。
后训练策略:五阶段递进强化能力
SAIL-VL2设计了一套递进式的五阶段后训练策略,以系统性地提升模型综合能力:
1、基础SFT:首先,通过四阶段数据注入与模型融合技术,为模型构建坚实的基础指令遵循能力。
2、LongCoT SFT:接着,使用40万条CoT样本,训练模型掌握逐步推理(step-by-step)的能力。
3、可验证奖励RL:然后,引入RL,基于“答案正确性+格式规范性”双重奖励优化STEM样本,确保推理结果准确、规范。
4、Think-Fusion SFT:随后,采用混合数据与条件损失进行训练,让模型学会按需推理,实现能力的收放自如。
5、混合奖励RL:最后,利用更复杂的三维奖励信号进行最终优化,实现强大推理能力与简洁输出的平衡。
训练基础设施:高效支撑大规模训练
Stream Packing:双策略提升训练效率
批处理与在线打包:通过动态拼接样本减少填充令牌,将SM利用率提升近1倍,训练速度加快50%,并提升了0.7%的QA性能。
视觉打包:通过加入视觉令牌平衡约束,缓解了视觉编码器的内存压力,使训练效率再提升48%。
MoE基础设施:突破稀疏架构训练瓶颈
计算优化:采用核融合技术将多个操作合并执行,减少数据搬运开销,使MoE训练速度提升达3倍。
通信优化:设计流式数据读取和混合并行机制,有效降低通信和训练开销。
性能验证:106个数据集上的全面领先
SAIL-VL2在106个多模态数据集上得到验证,从基础感知到复杂推理,从图像理解到视频分析,均展现出同规模模型中的顶尖水平。
基础模型性能:小参数规模实现大突破
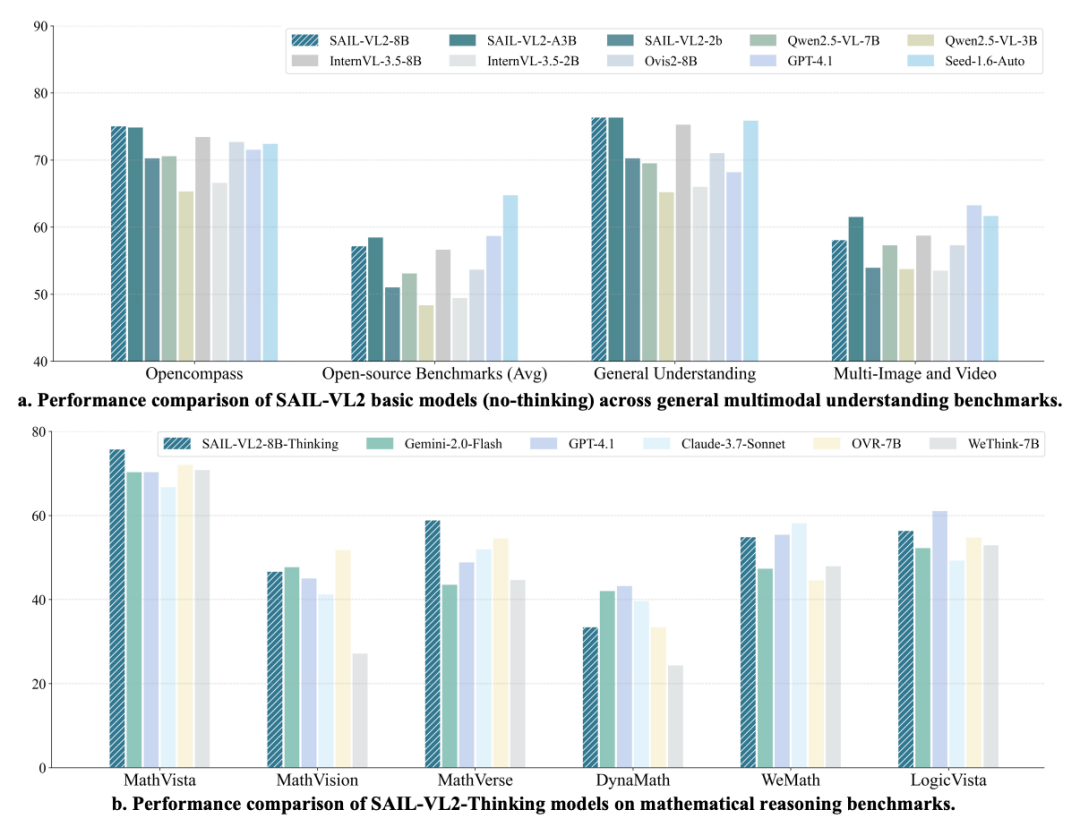
在通用多模态理解基准中,SAIL-VL2基础模型(无思维增强)表现突出(如下表所示):
SAIL-VL2-2B OpenCompass为70.31,超越Qwen2.5-VL-3B(65.36)、InternVL3.5-2B(66.64)等模型,位列4B参数以下开源第一;SAIL-VL2-8B在OpenCompass取得开源同量级模型的最高分数:

细粒度任务,SAIL-VL2-2BMMStar达64.07分,OCRBench达89.50分,均为同参数规模最优;SAIL-VL2-8B进一步将MMStar分数提升至70.73,OCRBench提升至91.30,8B规模领先。

思维增强模型性能:复杂推理能力媲美大模型
SAIL-VL2-Thinking在OpenCompass多模态推理榜单表现卓越:
SAIL-VL2-8B-Thinking平均得分54.4,超越所有开源模型,仅次于GPT-4o-latest(54.8);SAIL-VL2-A3B-Thinking(MoE架构)以3B激活参数实现53.6分,超越闭源模型Gemini-2.0-Flash(50.6),展现出极高的效率性能比。

论文地址:https://arxiv.org/pdf/2509.14033
代码与模型:https://github.com/BytedanceDouyinContent/SAIL-VL2
Hugging Face模型库:https://huggingface.co/BytedanceDouyinContent