点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:深蓝AI
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

导读
如果无人机真的能听懂人话,会是一种怎样的体验?比如你说:“飞到穿绿色衣服的人那儿”,它就立刻起飞、识别目标、绕开障碍、稳稳停在那人身边——不需要任何训练、没有任务微调、也不依赖预定义动作库。这并非幻想。
来自台湾阳明交通大学与台大的研究团队在 CoRL 2025 上提出了一个颇具突破性的框架——See, Point, Fly(SPF)。它让大语言模型(VLM)第一次在真实无人机控制中实现“所见即所飞”:只需一张图像和一句自然语言,就能完成目标定位、路径规划与闭环飞行。更令人惊讶的是:SPF 完全无需训练(training-free),却在模拟和真实环境中分别取得了 93.9% 和 92.7% 的成功率,比上一代方法提升了整整 63%。这意味着,未来的无人机可能不再需要专门学习如何飞,而是直接“看图说话”就能上天。

图1|一张图展示了 SPF 的核心循环:摄像头捕捉画面,VLM 输出目标坐标与障碍框,控制器实时更新飞行指令。无人机“看懂一句话”后,就能自动起飞并避障前进
论文出处:CoRL2025
论文标题:See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
论文作者:Chih Yao Hu, Yang-Sen Lin, Yuna Lee, Chih-Hai Su, Jie-Ying Lee, Shr-Ruei Tsai,Chin-Yang Lin, Kuan-Wen Chen, Tsung-Wei Ke, Yu-Lun Liu
传统的VLM无人机方案大多把导航当作“文字输出问题”——模型生成“turn left”“go forward”这类动作文本,再交给控制器解析。而 SPF 的核心思想恰恰相反:让VLM直接在图像上“指路”。研究者把无人机的相机画面输入到冻结的VLM中,并附上自然语言指令(例如“飞向那个穿绿色衣服的人”)。模型输出的不是文字,而是一个 JSON 结构化结果:包括目标点的 2D 像素坐标、预测的飞行距离以及障碍物的边界框。随后,SPF 的控制模块将这些2D点“抬升到3D空间”,转换成无人机的位移指令(前进、上升、转向),形成完整的闭环飞行控制循环。每一次循环就是“看—想—飞”的一次决策,这种思路让VLM真正走出了屏幕,成为会“动”的智能体。

图2|SPF 的飞行闭环包括三个阶段:理解阶段:VLM 接收图像与语言指令,输出结构化 JSON,包含目标点、预测距离与障碍物框。控制阶段:Action-to-Control 模块将这些输出转化为底层控制信号(偏航、俯仰、升降速度)。执行阶段:无人机实时更新视觉输入并重复循环,直到任务完成
语言变“坐标”
SPF 重新定义了 VLM 的角色——不再生成文本,而是生成带空间语义的“可视化标注”。
模型根据语言理解,在画面中选出目标区域并标出飞行点。这种“所见即所得”的方式天然具备空间一致性,无需再训练任何导航网络,就能把复杂语义转化为可执行动作。即使遇到模糊指令(如“飞到看起来最舒适的椅子”),VLM 也能凭通用常识推断合理目标。

图3|这张图解析了 SPF 如何把“看懂的点”变成“能飞的动作”:(a) 系统用一条非线性曲线自适应调整飞行步长,开阔处走快一点、障碍多时放慢脚步;(b) 将预测的 2D 航点通过针孔模型反投影为 3D 位移向量;(c) 再把这个向量分解为偏航、俯仰、升降三种控制指令。最终,这些命令被连续发送给无人机,实现流畅、稳定的闭环控制
自适应步长:越开阔飞得快,越危险走得稳
不同于传统的固定速度控制,SPF 设计了一个自适应飞行距离机制。
● 系统根据VLM输出的“深度提示”动态调整飞行步长——在开阔场景中迈大步、快速前进;
● 在狭窄空间里则谨慎微调。
这一机制大幅提升了导航效率:实验显示,在相同任务下,飞行时间从61秒缩短到28秒,几乎减半。可以理解为:它不仅知道“去哪”,还懂得“该多快”。

图4|这张图展示了自适应步长控制器的效果。在相同任务下,将固定步长改为自适应调节后,无人机的飞行时间直接缩短一半,同时任务成功率提升到 100%(5/5)。也就是说,SPF 不仅能聪明地“去哪”,还知道该多快、多稳地飞过去
零训练闭环控制
SPF 整个系统无需任何新训练或数据微调。它利用冻结的VLM(如 Gemini 2.0/2.5、GPT-4.1、Claude 3.7 等)直接推理,并结合几何映射与轻量控制器,实现完整闭环。这一点尤其关键:SPF 不是让AI学会飞,而是让AI直接会飞。在硬件上,它甚至可以运行在低功耗平台(如 DJI Tello EDU)上,用纯 Python SDK 即可实时控制。
研究团队在 Drone Racing League Simulator 和真实无人机上共设计了 34 个任务场景,包括:
● 静态导航(Navigation)
● 动态避障(Obstacle Avoidance)
● 多阶段长程飞行(Long Horizon)
● 推理与语义理解(Reasoning)
● 搜索与跟随(Search / Follow)
结果令人震撼:
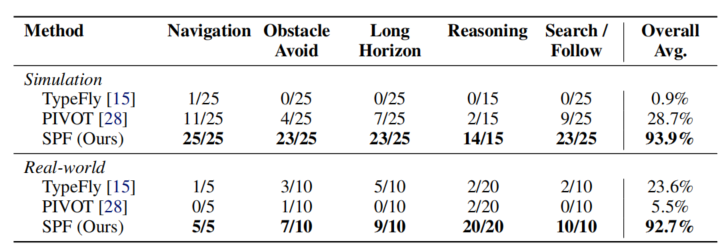
图5|SPF多场景实验结果(定量)
从实验结果能够看到,SPF在仿真环境和真实环境都达到了92%以上的成功率,相比之下,前一代方法 TypeFly 仅为 0.9%,PIVOT 为 28.7%。在真实场景中,SPF 成功避开障碍物、理解复杂指令,还能跟随动态目标——几乎达到“即插即飞”的通用智能水平。

图6|这张图展示了 SPF 与其他方法在真实环境中的飞行轨迹对比。绿色表示无人机的起飞路径,洋红色表示执行任务时的飞行轨迹。可以看到,SPF 的路线更加平滑、精准,能稳定避障并到达目标;而其他基线方法常出现偏航、漂移甚至中途停滞
SPF 的出现,是大模型进入“低空智能时代”的重要信号。它证明了——无需再为机器人训练专用模型,通用VLM也能直接驱动真实世界的物理行为。
这不只是“看图飞行”,更是一种新的范式转变:让AI从语言世界,真正“走向空间”。未来,在旅行途中,或许我们能对无人机直接说“帮我拍一个日照金山下的希区柯克变焦吧”,随后张开不再需要握紧遥控器的双手摆好pose,等待旅行大片的生成。
审编|阿蓝
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











