
> 本文转载自Datawhale
> 作者:Oana Olteanu,编译:Datawhale
 原文链接:https://www.motivenotes.ai/p/what-makes-5-of-ai-agents-actually
原文链接:https://www.motivenotes.ai/p/what-makes-5-of-ai-agents-actually大多数创始人以为自己在打造 AI 产品,但实际上他们真正在构建的是上下文选择系统。
上下文工程 ≠ 提示词技巧
索引过多 → 检索到过多信息 → 混淆模型
索引过少 → 模型缺乏有效信号
混合结构化和非结构化数据 → 破坏嵌入或简化关键架构
那么,真正的高级上下文工程到底是什么样的呢?

a) LLM 的特征选择
选择性上下文剪枝 = 特征选择 上下文验证 = 模式/类型/时效性 检查 “上下文可观测性” = 跟踪哪些输入提高/降低了输出质量 带元数据的嵌入增强 = 类型化特征 + 条件
b) 语义 + 元数据分层
语义层 → 经典向量搜索 元数据层 → 根据文档类型、时间戳、访问权限或垂直领域本体进行过滤控制
业务词汇表及术语对应关系 具有约束条件的查询模板 能够在执行前捕获语义错误的验证机制 能够随时间推移不断优化理解能力的反馈循环
治理与信任并非“仅限企业”的问题
在垂直领域构建产品的创始人请注意:
必须追踪哪些输入导致了哪些输出(溯源/谱系)
必须尊重行级别、基于角色的访问(策略门控)
即使提示词相同,你也必须为不同用户定制特定的输出
一位嘉宾说:
“如果两个员工问同一个问题,模型的输出应该不同,因为他们的权限不同。”
没有这些控制,Agent 在功能上可能是正确的,但在组织层面是错误的,会泄露访问权限或违反合规。
当前主流的解决方案是:针对结构化和非结构化数据构建统一的元数据目录,并在索引和查询时嵌入访问策略。
信任问题源自于人,而不是技术本身。
一位嘉宾分享了一个他的个人故事,很好的说明了这一点:他的妻子拒绝让他使用特斯拉的自动驾驶。为什么?不是因为它不管用,而是因为她不信任它。
“当 AI 触及到与你的安全、你的钱等非常敏感的领域时,你会信任它吗?我认为这是当前最大的障碍之一。我们确实有时候会使用 AI Agent,但最终还是会要考虑:我真的能信任这个 AI 吗?”
记忆不仅仅是存储,更是一种架构设计
记忆的不同层级:
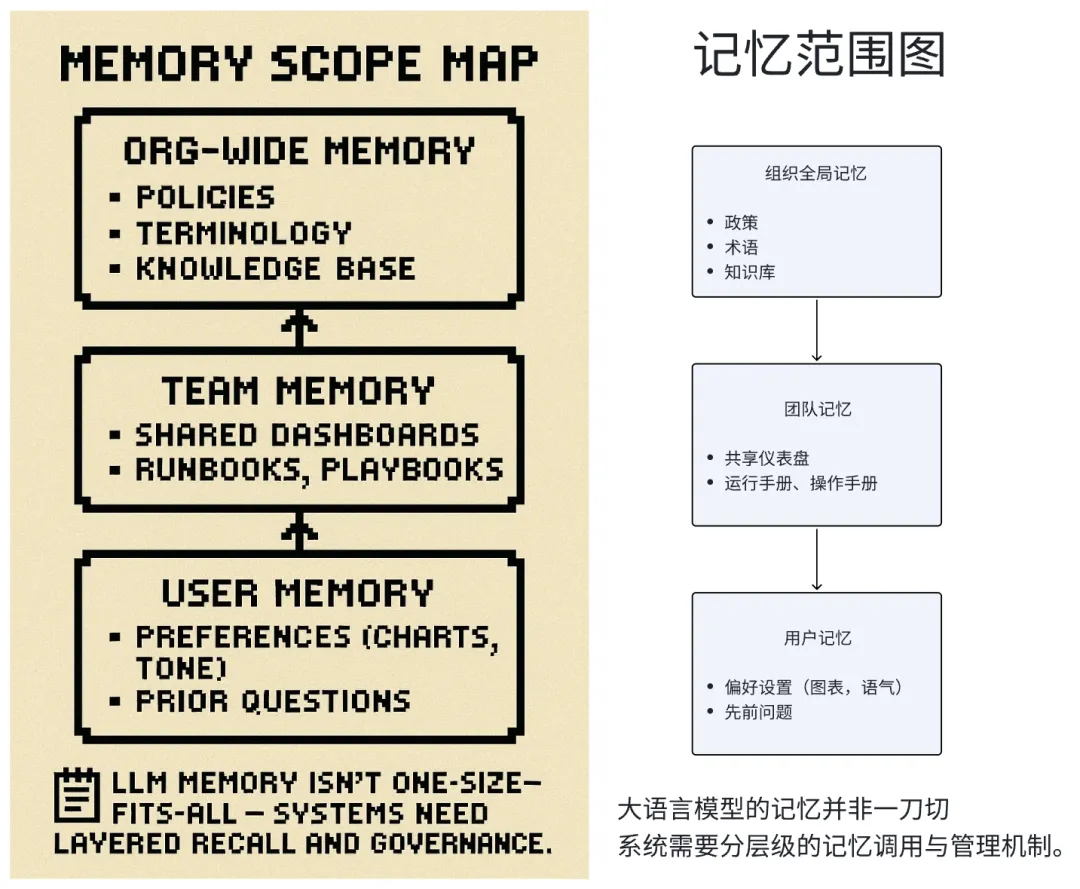
语义记忆+分类体系+操作指南=上下文 个人偏好=记忆
利用记忆实现个性化
根据用户的个人偏好、写作风格、常用格式及专业领域知识来定制化行为 基于事件和元数据提供主动协助,而不仅限于只是被动的聊天回应
设计记忆过程中的冲突与平衡
记忆功能能够改善用户体验并提升 Agent 的交互流畅度
但过度个性化很容易迅速触及隐私问题
如果不加以严格的范围限制,共享内存可能会突破访问控制
多模型推理与流程编排模式
任务的复杂程度 延迟约束 成本敏感度 数据本地化及监管合规问题 查询类型(例如,摘要生成、语义搜索或结构化问答)
对于简单查询 → 由本地模型处理(无需网络请求) 对于结构化查询 → 调用 DSL 或 SQL 翻译器 对于复杂分析 → 调用 OpenAI / Anthropic / Gemini 回退或验证机制 → 采用双模型冗余设计(判别模型+响应模型)
为何这很重要:

什么时候聊天界面是最合适的?
并不是所有任务都必须使用聊天机器人。
一位观众直接提出了质疑:“我觉得自然语言并不是总比图形界面更好。比如我要叫辆优步时,我根本不想跟手机对话,只想要轻轻点几下,车就来了。”
在这点上,嘉宾们达成的共识是:对话式交互的价值,在于它能够消除用户的学习成本。
对于 BI 仪表板、数据分析这类传统上需要专业技能的复杂工具,自然语言能够显著降低使用门槛。然而,当用户获得结果后,往往仍希望借助图形界面进行操作和调整——例如将饼图切换为条形图,这时候不应该再依赖额外的文字输入。
一种理想的混合模式: 将聊天界面作为起点,让用户能轻松上手,无需学习成本 提供图形界面的控制功能,支持后续的精细化调整与迭代
让用户能够根据具体任务和个人偏好,自由选择合适的模式
提供图形界面的控制功能,支持后续的精细化调整与迭代
让用户能够根据具体任务和个人偏好,自由选择合适的模式
一位嘉宾提到了自然语言处理(NLP)的两个理想应用场景:
处理偶发的、情绪化的任务,比如客户服务。例如用户感到沮丧时,只想倾诉或寻求帮助,而不是去费力地浏览层层菜单。
进行探索性的、开放式的查询,比如“帮我找一家靠近加州、第一排、能看到海景和蓝天的 Airbnb”,这类需求往往较为复杂且高度依赖具体情境
关键在于:应该去理解用户使用自然语言的真正意图,并据此进行设计,而非一味地将所有交互都强加于聊天界面之中。
还缺少什么?(一些具有潜力的方向)
在讨论中提到了一些还没有被深入挖掘的方向,但其实它们是真正有待产品化的核心组件:
上下文可观测性
哪些输入能够持续提升输出质量?什么样的上下文容易引发模型幻觉?你该如何像测试模型提示词那样来测试上下文?
目前,大多数团队都处于盲目前行的状态,缺乏系统性的方法来评估哪些上下文真正提升了模型性能,哪些反而造成了负面影响。
可组合记忆
记忆是否可以随用户携带(而非依附于应用),具备安全性和可移植性,并支持用户按需选择组织、团队或个人状态的层级?
这将解决两个问题:
用户不需要在每个新工具中重新建立上下文
隐私和安全由用户掌控,而不是被服务提供商限制
面向特定领域的领域感知语言
大多数企业用户的需求都是结构化且重复的。与其费力地将自然语言解析成容易出错的 SQL,为何不直接设计更高层次、具备约束安全性且更可靠的专用语言(DSL)呢?
有团队建议,不应该局限于文本转 SQL,而是应该构建一个语义化的企业业务逻辑层,例如“显示第四季度收入”直接对应到一个经过验证的计算方法,而不是直接生成原始 SQL。
具备延迟感知的用户体验
一位讨论嘉宾提到,他们开发的带记忆增强功能的聊天机器人,虽然响应速度较慢,但体验却令人欣喜。原因在于,机器人会根据用户上周的提问,智能地生成一系列后续回应。
这为异步、主动式 AI 如何提升用户体验提供了新思路,不仅限于聊天场景。想象一下:Agent 在你开会前自动生成好简报,在你打开文档时动推送相关信息,或是在你尚未察觉时就提前预警数据中的异常。
关键洞见:不同任务对延迟的要求不同。如果是一个笑话任务,需要即时呈现,而如果是一个深度分析任务,即使延迟 10 秒,只要系统能展示它的思考过程并最终给出有效的答案,用户体验就不会差。

生成式 AI 领域的未来方向
参加完这场专题讨论后,我更加确信:我们很快将迎来一波基础设施工具、记忆模块、编排框架以及上下文可观测性技术的发展浪潮。这些技术在将来回顾时,可能会显得顺理成章,但目前仍处于混乱且未被解决的状态。
生成式 AI 领域真正的壁垒,将不在于模型的获取,而在于:
上下文的质量
记忆设计
编排的稳定性
信任的用户体验
创始人需要自问的 5 个关键问题
我的应用程序的上下文容量是多少?(理想的上下文窗口大小是多少?我又该如何优化其中的内容?)
我的记忆边界在哪里?(哪些信息属于用户级、团队级、组织级?这些数据存储在何处,用户是否可以查看?)
我能否追踪输出结果的来源?(我能通过调试 LLM 的回复,知道具体是哪个输入导致了该回复吗?)
我使用的是单一模型还是多模型?(我是如何根据复杂度、延迟还是成本来分配请求的?)
用户会放心把他们的资金或医疗数据交给我的系统管理吗?(如果不会,我的安全性或反馈机制上还缺失什么?)










